🎈 seq2seq(Sequence to Sequence)
seq2seq은 입력 sequence를 받아 출력 sequence를 생성하는 모델로써 RNN 계열의 알고리즘을 활용한 archtecture이다.
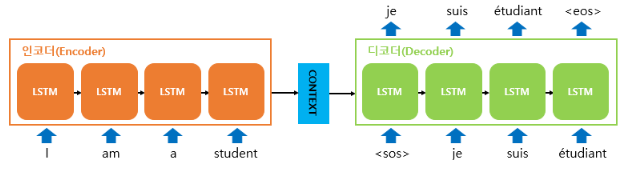
seq2seq은 가변적인 입/출력 sequence 길이를 처리할 수 있다. 또한, 입력 sequence에 대한 압출 정보인 context vector를 디코더의 hidden state로 활용하여 출력 sequence를 생성한다.
하지만 seq2seq는 RNN(LSTM)의 고질적인 문제인 기울기 소실과 입렵 sequence를 고정된 크기의 vector로 압축하며 생기는 정보 손실 문제를 갖고 있다.
seq2seq의 자세한 내용은 아래에서 확인할 수 있다.
🎈 Attention Mechanism
Attention은 특정 알고리즘이 아닌 정보 전달 기법이다. 그렇기 때문에 seq2seq의 단점을 보완하고자 적용된 것이며 seq2seq뿐만 아니라 다른 알고리즘에도 활용 가능하다.
📌 Attention 개념
어텐션(attention)은 단어 뜻 그대로 집중의 역할을 한다. 어텐션의 핵심 아이디어는 디코더의 매 시점마다 인코더의 전체 입력을 다시 한번 참조할 수 있도록 돕는 것이다. 이때 중요한 것은 전체 입력을 동일하게 확인하는 것이 아니라 현재 예측해야할 디코더에 가장 연관있는 부분을 더 집중적으로 참조하는 것이다.
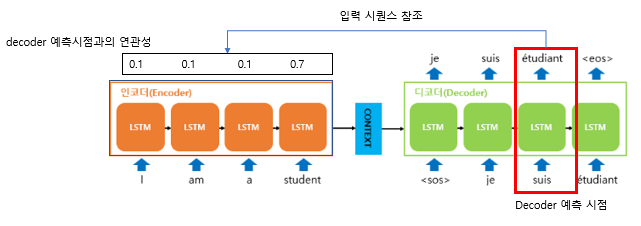
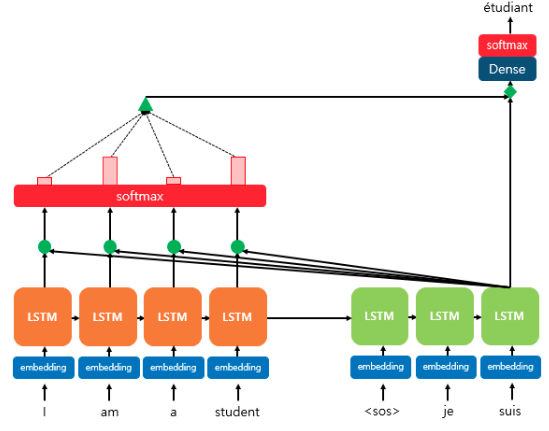
위 예시를 보면 'étudian'를 예측해야 하는 시점이기 때문에 입력 시퀀스 중 가장 연관성이 높은 'student'를 더 집중적으로 참조한다.
정리하자면 어텐션 메커니즘은 디코더의 매 예측 시점마다 현재 예측과의 연관성을 활용해 입력 sequence를 참조하는 것이다.
📌 Attention Score
어텐션 스코어(attention score)는 디코더의 예측 시점에서의 hidden state가 인코더의 모든 hidden state와 얼마나 연관성이 있는지를 나타낸 값이다.
어텐션 스코어는 어떠한 함수를 사용하느냐에 따라 달라지는데 대표적으로 아래와 같은 방식이 있다.
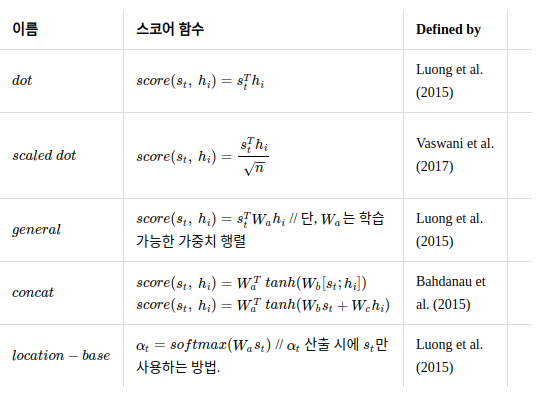
📌 Attention Mechanism 방식
0. Query, Key, Value
먼저 attention mechanism을 이해하려면 쿼리(Query), 키(Value), 값(Value)를 알아야 한다.
Query Q: 현재 디코더가 예측해야하는 디코더의 hidden state
Key K: 인코더와 디코더의 hidden state가 얼마나 연관성이 있는지 알기 위해 참조하는 인코더의 hidden state
Value V: 각 Key와 연관된 인코더의 hidden state(실제 값)
- 이때 Q, K, V는 모두 hidden state의 vector이다.
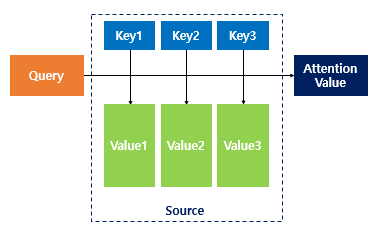
1. 전체 구조
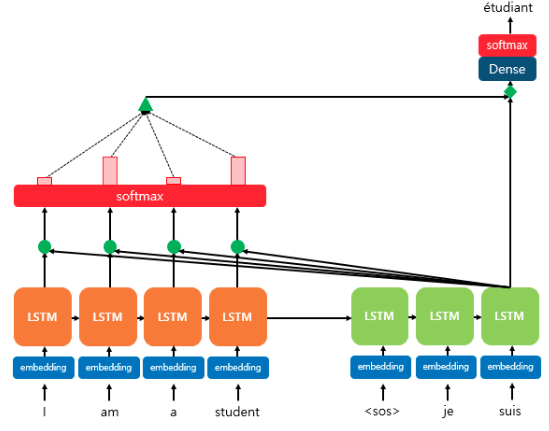
위 예시는 3번째 디코더의 LSTM이 입력 sequence를 참조해 예측을 하는 상황이다. 디코더에서 예측을 위해 인코더의 각 시점에서 Key(초록색 동그라미)를 통해 연관성을 확인한다. 그 후 softmax 함수를 적용한 값들을 이용해 attention score를 계산(초록색 세모)하고, 그 정보를 토대로 attention Value(초록색 다이아몬)를 추출한다.
2. 어텐션 스코어(Attention Score) 구하기
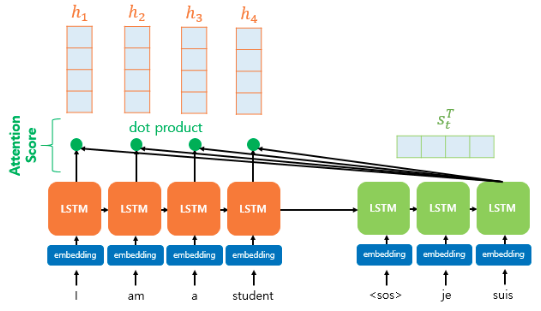
: 인코더의 hidden state (=1, 2, ..., n)
: 현재 시점(time step) 에서의 디코더의 hidden state
어텐션 value를 구하기 위해서는 먼저 어텐션 스코어를 구해야 한다. 어텐션 스코어는 현재 디코더의 시점 에서 단어를 예측하기 위해 인코더의 모든 hidden state 가 디코더의 hidden state 와 얼마나 유사한지를 판단한다.
이렇게 얻은 스코어 값(스칼라)를 모두 모은 것을 라고 한다.
3. 어텐션 분포(Attention Distribution) 구하기
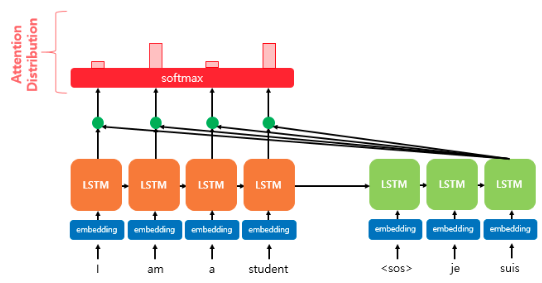
어텐션 스코어 에 softmax 함수를 적용하면 어텐션 분포(확률 분포)를 구할 수 있다. 어텐션 분포의 각각의 값을 어텐션 가중치(attention weight) 라고 한다.
4. 어텐션 값(Attention Value) 구하기
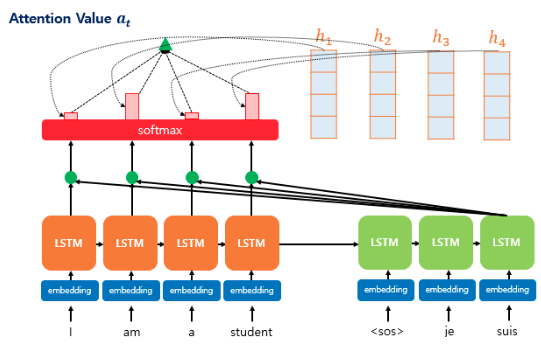
어텐션 값 를 구하기 위해 인코더의 각 hidden state 를 어텐션 가중치와 곱한 후 모두 더한다.
이때 어텐션 값 은 인코더의 문맥을 포함하고 있어 컨텐스트 벡터(context vector)라고 불린다.
5. 어텐션 값과 디코더의 현재 시점 hidden state 연결하기
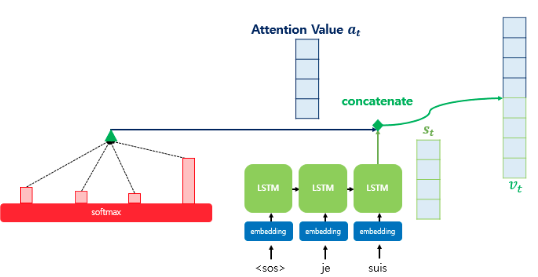
어텐션 값 와 디코더의 현재 시점 hidden state인 를 결합(concatenate)하여 하나의 벡터 를 만든다.
6. 출력층 연산의 입력 계산하기
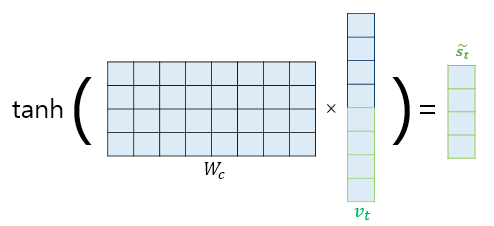
와 가중치 행렬 를 곱한 후 함수 적용해 출력층 연산을 위한 벡터 를 구한다.
7. 최종 예측 벡터 구하기
를 출력층의 입력으로 하여 예측 벡터를 얻는다.
