PyTorch

Open source DL framework로 GPU를 이용한 Tensor computing, Automatic differentiation system을 지원한다.
torch.Tensor
PyTorch Tensor는 GPU acceleration을 제외하면 NumPy ndarrays와 유사하다.
Initialize with Python lists
아래는 Python의 list를 각각 numpy와 tensor로 만드는 방법이다.

Initialization: ones & zeros
ones(), zeros() 함수를 이용하면 1과 0으로 채운 numpy와 tensor를 만들 수 있다.

Initialization: ones_like & zeros_like
ones_like() 와 zeros_like()를 이용하면 입력 numpy 배열, 텐서와 동일한 모양의 0과 1로 채워진 numpy 배열, 텐서를 만들 수 있다.

Two ways of specifying data type
- keword,
dtype사용

- typed tensors 사용


Tensor operations
Accessing elements
아래와 같이 index를 이용하여 접근할 수 있다.

index로 접근 시 tensor 형태로 반환되는데, python number를 얻기 위해서는 item()을 사용하면 된다.

index로 접근해서 값 변경도 가능하다.

Slicing
아래와 같이 원하는 부분을 추출하는 slicing도 이용할 수 있다.
- start (inclusive), end (exclusive)
- Default values (start: 0, end: length)


다음과 같이 Negative slicing 도 가능하다.

Shape & Transpose (matrix)
전치 행렬 (행과 열을 교환하여 얻는 행렬)을 얻고 싶은 경우에는 .T를 이용하면 된다.

tensor의 shape을 알고 싶은 경우에는 .shape 을 이용하면 된다.

Sum
torch.sum(input, dim, keepdim=False, *, dtype=None) → Tensor
- input(Tensor): the input tensor
- dim(int or tupke, optional): the dimensions to reduce
- keepdim(bool): whether the output tensor has dim retained or not
- Equivalent representations:
𝑋.sum()andtorch.sum(𝑋)

Mean
torch.mean(input, dim, keepdim=False, *) → Tensor
sum과 파라미터 및 사용법이 유사하다! 평균을 구하는데 이용한다.

Max
torchmax(input, dim, keepdim=False, *) → Tensor
sum과 파라미터 및 사용법이 유사하다! 최대값을 구하는데 이용한다.

Binary Operators
tensor간 binary operator를 사용하는 경우, 원소별(element-wise)로 계산해준다.


Inner product
.inner()를 사용해서 내적을 계산할 수 있다.

Tensor manipulation
이제 텐서의 shape, dimension 등을 조작하는 방식을 알아보자.
View
X.view(*shape)를 이용해서 사용자가 원하는 shape으로 바꿀 수 있다. 이 때 지정되는 shape은 element의 개수가 동일해야한다. 즉, data와 element 개수는 동일하지만 지정된 shape의 tensor로 만들어주는 것이다! ex) 6*2*2 => 3*4*2

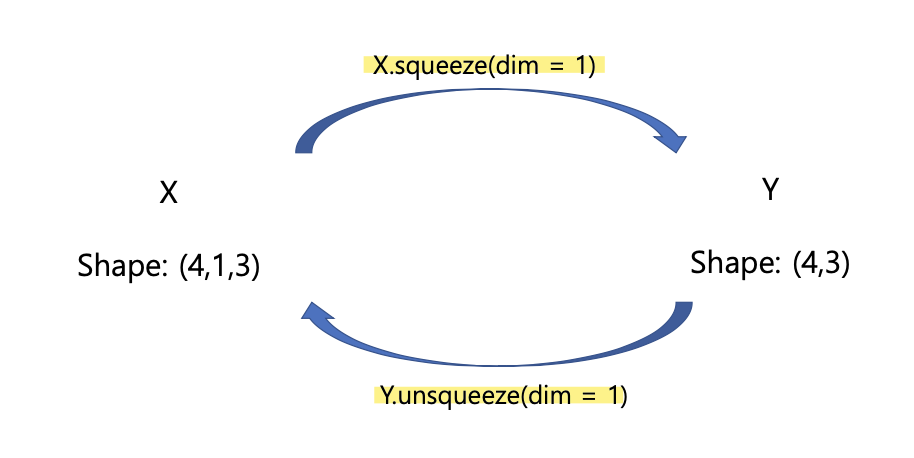
Squeeze/Unsqueeze
squeeze는 차원을 줄일 때 사용하고, unsqueeze는 차원을 늘릴 때 사용한다!
Broadcasting
뒤쪽 dimension부터 비교할 때, 1이거나 차원이 없는 경우일 때 broadcasting이 이루어질 수 있다. 아래 사진을 보며 이해해보자.

ndarray <-> tensor
from_numpy()를 이용하여 numpy를 tnesor로 바꿀 수 있고, numpy()를 이용하여 tensor를 numpy로 바꿀 수 있다.

Autograd
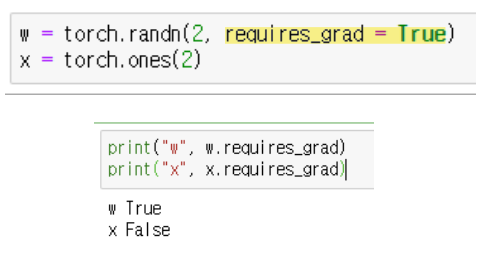
우리는 이전에 gradient descent를 사용하기위해 chain rule을 이용하여 미분 값을 계산했다. 하지만 앞서 살펴본 작은 모델과 달리 큰 모델들의 파라미터는 수천만개도 넘는다. 이를 일일히 계산하기는 매우 비효율적일 것이다... 이런 파라미터들의 자동미분을 도와주는 것이 바로 torch.autograd라는 PyTorch의 자동미분 엔진이다. 아래와 같이 model parameter의 requires_grad를 True로 설정해주면, 해당 model parameter의 gradient를 자동으로 추적해준다!
그리고는 아래와 같이 loss.backward()를 호출하면, 자동으로 역전파가 이루어지는 것이다!

아래와 같이 gradient의 추적을 끄고 킬 수도 있다. validation, test와 같이 미분값 계산에 따른 파라미터 업데이트가 필요하지 않은 곳에 torch.no_grad()를 쓰면 되는 것이다!

