KoBERT
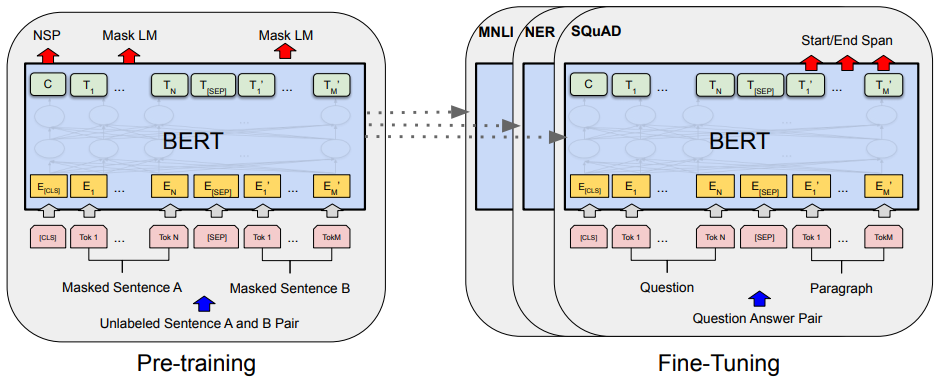
2018년 구글에서 공개한 BERT는 수많은 NLP task에서 아주 높은 성능을 보여주었다. 하지만 BERT로 한국어를 처리할 경우 영어보다 정확도가 떨어진다. KoBERT 모델은 SKTBrain에서 한국어 위키 5백만 문장과 한국어 뉴스 2천만 문장을 학습시켜 한국어 처리를 용이하게 만든 모델이다. 기존에 많은 문장을 이용하여 pre-trained 되었기 때문에, 사용 목적에 따라 output layer만 추가로 달아주는 방식으로 fine-tuning을 진행하여 원하는 결과를 얻을 수 있다.
NAVER Shopping Review fine-tuning
우선 11번가 리뷰 데이터를 클롤링하여 fine-tuning을 진행하기 전, 공개되어있는 naver shopping review data를 이용하여 성능이 어느 정도 나오는지 확인하였다.
1. Install KoBERT as a python package
KoBERT Repo에 가면 다음과 같이 KoBERT를 설치할 수 있다고 설명해주고 있다.
!pip install git+https://git@github.com/SKTBrain/KoBERT.git@master설치 후 필요한 library들을 import 해준다.
import torch
from torch import nn
import torch.optim as optim
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
import numpy as np
import pandas as pd
import gluonnlp as nlp
from tqdm.notebook import tqdm
from transformers import AdamW
from transformers.optimization import get_cosine_schedule_with_warmup
from transformers import BertModel# for gpu setting
device = torch.device("cuda:0")
device2. Data 불러오기
기존에 naver shopping review 텍스트 파일을 csv 파일로 변환하여 저장해두었고, 여기서는 csv 파일로 가져왔다. 이 때, 한국어 encoding을 위해 cp949을 이용했다. 총 20만개의 데이터가 긍부정 약 1:1로 분포된 것을 확인할 수 있었다.
# -*- coding: cp949 -*-
data = pd.read_csv("/content/naverReview.csv")
data3. 0과 1로 label 변경
apply 함수를 이용하여
기존에 부정(1,2)은 0으로 긍정(3,4)은 1로 label을 변경해주었다.
def changeTo01(x):
if x<3:
return 0
else:
return 1
data['star'] = data['star'].apply(changeTo01)
data4. Input for BERTDataset
후에 만들 BERTDataset에 Input으로 넣기 위해 다음과 같이 review, star로 이루어진 list들을 data_list에 넣어주었다.
data_list = []
for review, label in zip(data['review'], data['star']):
data = []
data.append(review)
data.append(label)
data_list.append(data)
len(data_list)아래와 같이 리뷰와 평점으로 잘 구성된 것을 확인할 수 있다.

5. Train Test Split
sklearn의 train_test_split을 이용하여 train과 test data를 4:1로 나누어주었다.
from sklearn.model_selection import train_test_split
train, test = train_test_split(data_list, test_size = 0.2, shuffle=True, random_state = 0)6. KoBERT tokenizer, model
다음과 같이 tokenizer와 pre-trained된 model을 불러올 수 있다.
from kobert import get_tokenizer
from kobert import get_pytorch_kobert_model
tokenizer = get_tokenizer()
tok = nlp.data.BERTSPTokenizer(tokenizer, vocab, lower=False)7. BERTDataset
학습에 이용될 DataLoader에 넣을 Dataset을 정의해주었다.
BERTSentenceTransform : BERT style data transformation

class BERTDataset(Dataset):
def __init__(self, dataset, sent_idx, label_idx, bert_tokenizer, max_len, pad, pair):
transform = nlp.data.BERTSentenceTransform(bert_tokenizer, max_seq_length=max_len, pad=pad, pair=pair)
self.sentences = [transform([i[sent_idx]]) for i in dataset]
self.labels = [i[label_idx] for i in dataset]
def __getitem__(self, i):
return (self.sentences[i] + (self.labels[i], ))
def __len__(self):
return (len(self.labels))8. Parameter 설정
학습에 이용될 parameter를 정의해주었다.
max_len = 64 # max seqence length
batch_size = 64
warmup_ratio = 0.1
num_epochs = 5
max_grad_norm = 1
log_interval = 200
learning_rate = 5e-59. DataLoader
앞서 정의해둔 BERTDataset을 이용하여 dataset을 만들어준 후, DataLoader를 만들어 주었다.
train_dataset = BERTDataset(train, 0, 1, tok, max_len, True, False)
test_dataset = BERTDataset(test, 0, 1, tok, max_len, True, False)
# num_workers : how many subprocesses to use for data loading
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, num_workers=5)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size, num_workers=5)10. KoBERT model
fine-tuning을 위한 BERTClassifier를 다음과 같이 정의하였다.
bert는 최종 Output으로 2가지를 내놓는다.
- 마지막 hidden_state의 첫 토큰
- 마지막 hidden_state
class BERTClassifier(nn.Module):
def __init__(self, bert, hidden_size=768, num_classes=2, dr_rate=None, params=None):
super(BERTClassifier, self).__init__()
self.bert = bert
self.dr_rate = dr_rate
self.classifier = nn.Linear(hidden_size , num_classes)
if dr_rate:
self.dropout = nn.Dropout(p=dr_rate)
def gen_attention_mask(self, token_ids, valid_length):
attention_mask = torch.zeros_like(token_ids)
for i, v in enumerate(valid_length):
attention_mask[i][:v] = 1
return attention_mask.float()
def forward(self, token_ids, valid_length, segment_ids):
attention_mask = self.gen_attention_mask(token_ids, valid_length)
_, pooler = self.bert(input_ids = token_ids, token_type_ids = segment_ids.long(), attention_mask = attention_mask.float().to(token_ids.device))
if self.dr_rate:
out = self.dropout(pooler)
else:
out = pooler
return self.classifier(out)위에서 정의한 BERTClassifier를 아래와 같이 사용한다.
model = BERTClassifier(bertmodel, dr_rate=0.5).to(device)11. optimizer, loss, scheduler
optimizer는 AdamW를, loss function은 CrossEntropyLoss를 사용했다.
AdamW
: Adam이 L2 regularization과 weight decay 관점에서 SGD에 비해 일반화 능력이 떨어지는 문제점을 해결하기 위해 등장했다.

Learning rate schedule
: 학습이 진행됨에 따라 epoch 또는 iteration 간에 학습률을 조정하는 사전 정의된 프레임워크
get_cosine_schedule_with_warmup
: 0과 옵티마이저에 설정된 초기 lr 사이에서 선형적으로 증가하는 워밍업 기간 후에 옵티마이저에서 0으로 설정된 초기 lr 사이의 코사인 함수 값에 따라 감소하는 학습률로 스케줄을 생성
- optimizer (Optimizer) — The optimizer for which to schedule the learning rate.
- num_warmup_steps (int) — The number of steps for the warmup phase.
- num_training_steps (int) — The total number of training steps.
no_decay = ['bias', 'LayerNorm.weight']
# 최적화해야 할 parameter를 optimizer에게 알려야 함
optimizer_grouped_parameters = [
{'params': [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)], 'weight_decay': 0.01},
{'params': [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}
]
optimizer = AdamW(optimizer_grouped_parameters, lr=learning_rate) # optimizer
loss_fn = nn.CrossEntropyLoss() # loss function
t_total = len(train_loader) * num_epochs
warmup_step = int(t_total * warmup_ratio)
scheduler = get_cosine_schedule_with_warmup(optimizer, num_warmup_steps=warmup_step, num_training_steps=t_total)12. Calculate Accuracy
학습 및 평가 시 정확도 측정을 위한 함수이다.
def calc_accuracy(X,Y):
max_vals, max_indices = torch.max(X, 1)
train_acc = (max_indices == Y).sum().data.cpu().numpy()/max_indices.size()[0]
return train_acc13. Train and Evaluation
학습 결과 약 93%의 정확도가 나타났다.
for e in range(num_epochs):
train_acc = 0.0
test_acc = 0.0
# Train
model.train()
for batch_id, (token_ids, valid_length, segment_ids, label) in tqdm(enumerate(train_loader), total=len(train_loader)):
optimizer.zero_grad()
token_ids = token_ids.long().to(device)
segment_ids = segment_ids.long().to(device)
valid_length= valid_length
label = label.long().to(device)
out = model(token_ids, valid_length, segment_ids)
loss = loss_fn(out, label)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), max_grad_norm)
optimizer.step()
scheduler.step() # Update learning rate schedule
train_acc += calc_accuracy(out, label)
if batch_id % log_interval == 0:
print("epoch {} batch id {} loss {} train acc {}".format(e+1, batch_id+1, loss.data.cpu().numpy(), train_acc / (batch_id+1)))
print("epoch {} train acc {}".format(e+1, train_acc / (batch_id+1)))
# Evaluation
model.eval()
for batch_id, (token_ids, valid_length, segment_ids, label) in tqdm(enumerate(test_loader), total=len(test_loader)):
token_ids = token_ids.long().to(device)
segment_ids = segment_ids.long().to(device)
valid_length= valid_length
label = label.long().to(device)
out = model(token_ids, valid_length, segment_ids)
test_acc += calc_accuracy(out, label)
print("epoch {} test acc {}".format(e+1, test_acc / (batch_id+1)))14. 모델 저장
학습한 모델을 불러와서 사용할 수 있도록 가중치 파일을 다음과 같이 저장해준다!
PATH = '/content/'
torch.save(model.state_dict(), PATH + 'naver_shopping.pt')15. 저장한 model 불러와서 test
학습한 model을 불러와서 local에서 test를 진행하는 코드이다! 꽤 분류를 잘하는 것 같다 :)
import torch
from torch import nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
import gluonnlp as nlp
import numpy as np
from tqdm import tqdm, tqdm_notebook
from BERTDataset import BERTDataset
from model.BERTClassifier import BERTClassifier
from kobert.utils import get_tokenizer
from kobert.pytorch_kobert import get_pytorch_kobert_model
# parameter
max_len = 64
batch_size = 64
# device
device = torch.device('cpu')
#BERT 모델, Vocabulary 불러오기
bertmodel, vocab = get_pytorch_kobert_model()
## 학습 모델 불러오기
PATH = './model/naver_shopping.pt'
model = BERTClassifier(bert=bertmodel)
model.load_state_dict(torch.load(PATH, map_location=device))
model.eval()
# 토큰화
tokenizer = get_tokenizer()
tok = nlp.data.BERTSPTokenizer(tokenizer, vocab, lower=False)
def predict(predict_sentence):
data = [predict_sentence, 0]
dataset_another = [data]
another_test = BERTDataset(dataset_another, 0, 1, tok, max_len, True, False)
test_loader = torch.utils.data.DataLoader(another_test, batch_size=batch_size, num_workers=0)
for batch_id, (token_ids, valid_length, segment_ids, label) in enumerate(test_loader):
token_ids = token_ids.long().to(device)
segment_ids = segment_ids.long().to(device)
valid_length= valid_length
label = label.long().to(device)
out = model(token_ids, valid_length, segment_ids)
test_eval=[]
for i in out:
logits=i
logits = logits.detach().cpu().numpy()
if np.argmax(logits) == 0:
test_eval.append("부정적")
else:
test_eval.append("긍정적")
print(">> 해당 리뷰는 " + test_eval[0] + " 리뷰 입니다.")
print("\n0을 입력하면 리뷰 감성분석 프로그램이 중단됩니다.\n")
while True:
sentence = input("긍부정을 판단할 리뷰를 입력해주세요 : ")
if sentence == "0":
print(">> 긍부정 판단을 종료합니다!\n")
break
predict(sentence)
print("\n")
