Python Crawling
인터넷 상에 오픈 되어 있는 수많은 정보들을 잘 활용하면 새로운 가치의 데이터로 만들어 낼 수 있다. 이러한 데이터를 수집하는 행위를 크롤링(Crawling) 이라하고, 크롤링하는 프로그램을 크롤러(Crawler) 라고 한다.
로또 당첨 번호 크롤링
로또 사이트에서 당첨 번호를 가져와서 출력해 보자. 파이썬에서 BueautifulSoup을 이용하면 크롤링 기능을 손쉽게 사용할 수 있다. 우선 다음과 같이 requests와 BueautifulSoup을 설치 해보자.
requests: 파이썬용 HTTP 라이브러리BueautifulSoup: HTML에서 쉽게 데이터를 추출할 수 있도록 도와주는 라이브러리
pip install requests # jupyter notebook에서 설치할경우 앞에 '!' 붙이기 (!pip install requests)
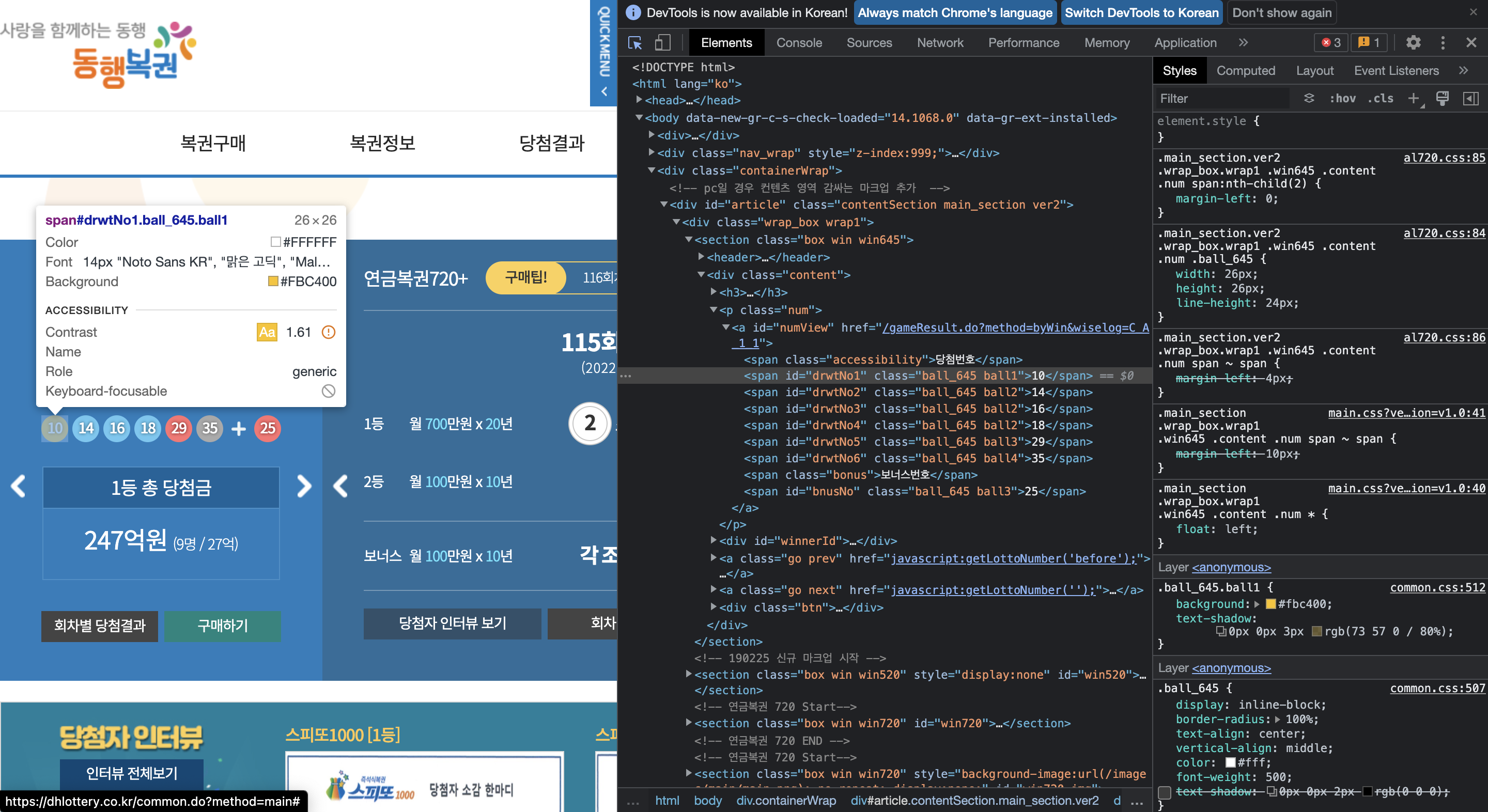
pip install BeautifulSoup4사이트에 들어가서 개발자도구(F12)를 들어가 로또 당첨 번호가 있는 쪽에 커서를 올려보면 해당 html 코드를 볼 수 있다. 로또 당첨번호가 모두 공통적으로 ball_645 class를 사용하고 있는 것을 알 수 있다. 이를 이용하여 크롤링을 진행해보자.
import requests
from bs4 import BeautifulSoup as bs
res = requests.get("https://dhlottery.co.kr/common.do?method=main")
soup = bs(res.content, "html.parser")
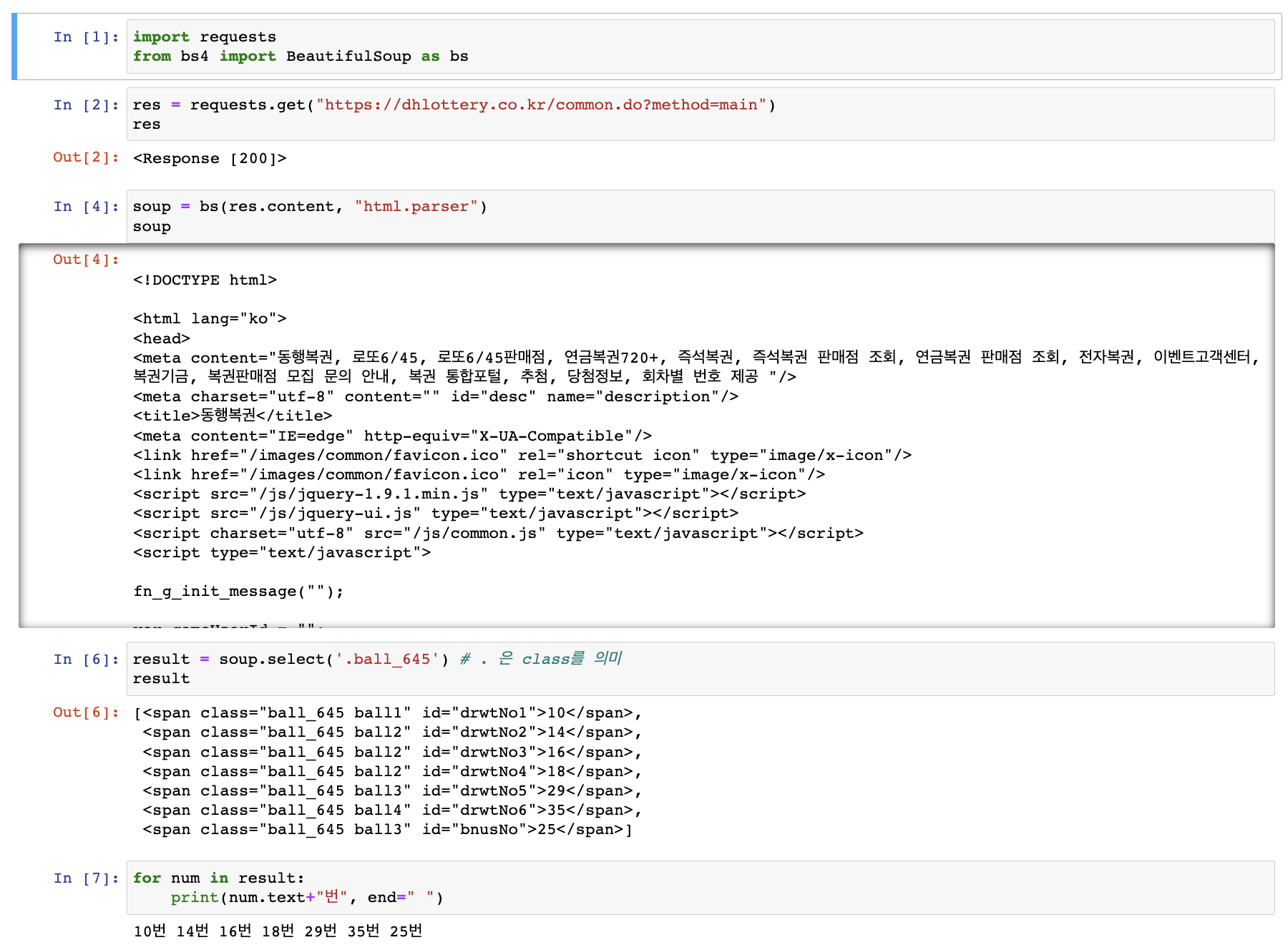
result = soup.select('.ball_645') # . 은 class를 의미
for num in result:
print(num.text+"번", end=" ")다음과 같이 잘 크롤링 된 것을 확인할 수 있다!
네이버 뉴스 크롤링
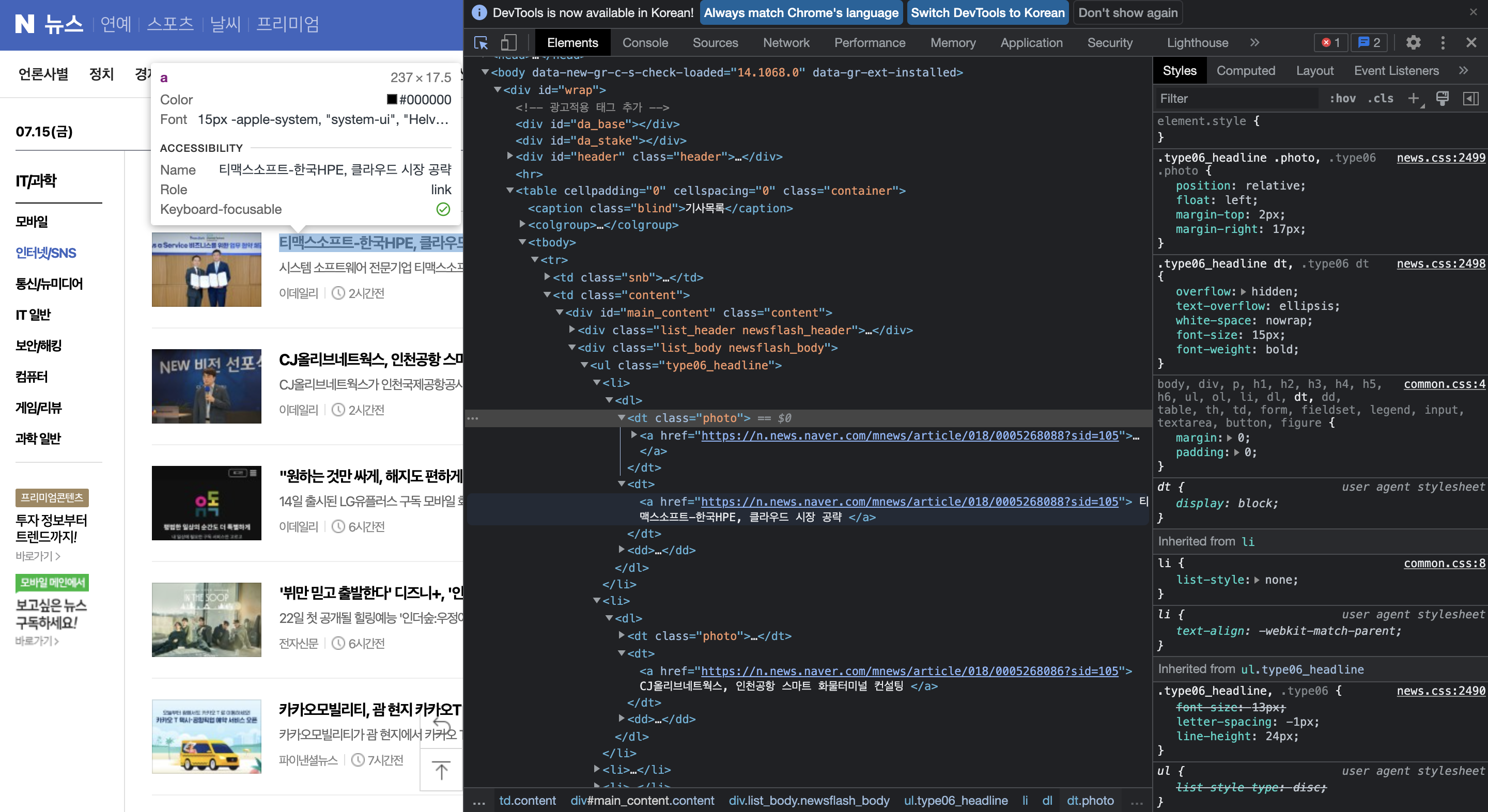
이번엔 네이버 뉴스 기사를 크롤링 해보자! 우선 똑같이 개발자 도구를 열어주고, html을 살펴보자. 사진과 기사 url 모두 <a>를 사용하고 있다. 이를 구별하기 위해 짝수 판별법(사진-기사-사진-기사-... 이라서 ㅎ)을 사용했다 ,, ^^ 다른 방법이 있을 것 같은데, 못 찾았다 ㅎㅎ (아시는 분 알려주세요,,)
뉴스 기사 크롤링을 위해 newspaper 모듈을 이용하였다. newspaper는 사용자가 지정한 url에서 text를 추출해주는 모듈이다. 다음과 같이 설치할 수 있다.
pip install newspaper3kimport requests
from bs4 import BeautifulSoup as bs
import newspaper앞서 진행했던 것처럼 http response를 받아온다. 이 때, 브라우저를 설정해주어서 python이 아닌 web에서 접속한 것처럼 보여야 네이버 서버에서 거부를 안한다고 한다 ^^..
url = 'https://news.naver.com/main/list.naver?mode=LS2D&mid=shm&sid1=105&sid2=226'
res = requests.get(url, headers={'User-Agent':'Mozilla/5.0'}) # 브라우저 정보 입력 (미 입력 시 응답 거부)
soup = bs(res.text, 'html.parser').은 class를 의미하고 >는 하위로 내려갈 때 사용하면 된다~!
news_url = soup.select('.list_body > ul > li > dl > dt')아래는 크롤링 해온 것에서 뉴스 url만 뽑아내는 코드다!
news = []
for i in range(len(news_url)):
if i%2!=0:
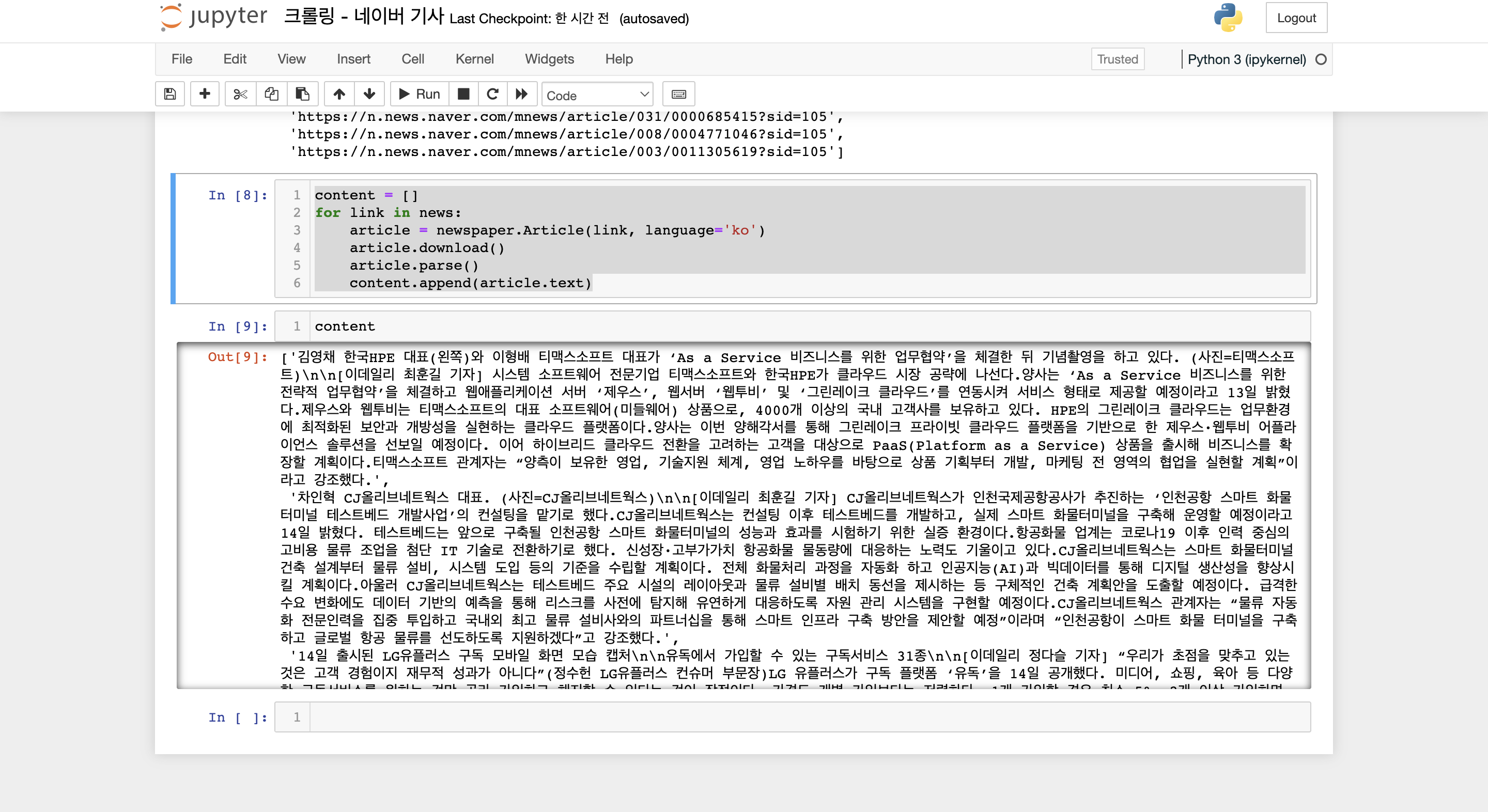
news.append(news_url[i].find('a')['href'])다음과 같이 newspaper를 이용하여 뉴스 기사를 추출해주었다~!
content = []
for link in news:
article = newspaper.Article(link, language='ko')
article.download()
article.parse()
content.append(article.text)기사가 잘 추출된 것을 확인할 수 있다!
Selenium
