시간 내서 자주 AI 관련 post를 읽으려고 노력 중이다.
이왕이면 블로그에 정리해두면 좋을 것 같아서 글을 남긴다.
오늘 읽은 글은 "멜론에서 음악 추천을 어떻게 할까? – 카카오 아레나 3회 대회(Part.1)" 이다.
대회 목표
시드(seed) 곡과 내가 원하는 느낌을 표현하는 단어 리스트가 주어졌을 때, 주어진 곡과 비슷한 느낌의 곡들이 수록되어 있는 플레이리스트 생성
추천 시스템
아이템에 대한 선호도를 예측해서,
사용자가 관심을 가질만한 정보를 추려서 제공하는 것
이름만 들으면 별거 아닌 것 같아 보여도, 사업성이나 사용자의 편의 등 여러 측면에서 정말 중요한 것 같다.
( 캡스톤 디자인 이쪽으로 해봐도 좋은 경험이 될 것 같다. )
추천 방법론
추천에서 주로 사용하는 추천 방법론에는 크게 두 가지가 있다고 한다.
1. 콘텐츠 기반 필터링(content-based filtering)
대상 자체의 특성을 바탕으로 추천하는 방법론
ex) 음악 추천 시스템 -> 곡 자체의 내용물을 살펴봄
- 곡 자체에서 정보를 뽑아내기 때문에 딥러닝이 개입할 여지가 많음.
- 오디오 정보 입력 형태 (엔드 투 엔드 / 멜 스펙트로그램)
- 엔드 투 엔드(end-to-end): 오디오 웨이브 데이터를 있는 그대로 넣어서 처리하는 모델로 가장 단순한 방식. 데이터의 전처리가 필요 없다는 장점이 있으나 모델이 학습해야 할 필터의 종류가 많기 때문에 모델이 충분히 학습되려면 전문 지식을 통해서 처리한 결과를 넣어주는 것보다 훨씬 많은 데이터를 필요로 함.
- 멜 스펙트로그램(mel-spectrogram): 웨이브 시그널을 짧은 시간별로 잘라서 각 조각마다 푸리에 변환을 취하고 이를 붙여서 해당 오디오의 2D 표현을 얻음. 이를 인간의 청각적 지각 능력에 맞춰서 로그 스케일로 스펙트로그램의 주파수 축을 줄이고 이 값들을 몇 개의 주파수 대역대로 묶으면 크기를 줄이는 동시에 가장 중요한 정보들을 보존할 수 있는 멜 스펙트로그램을 만들 수 있음.
=> 멜론에서 음원 데이터를 활용하는 방식
최근, 이미지에서 잘 동작하는 convolutional 모델이 오디오 데이터에서도 잘 동작한다는 연구 결과가 빈번하게 발표되고 있음.
멜론에서는 convolutional layer를 활용한 아키텍처를 사용해 오디오의 임베딩을 만들고, 이것을 사용해서 음악의 High-level feature들을 추출하거나, 임베딩 간 비슷한 정도를 활용해서 유사곡을 추천하고 있음.
2.협업 필터링(collaborative filtering)
'이것을 좋아했던 다른 사람들은 또 어떤 걸 좋아해요?' 라는 물음을 기반으로 추천하는 방법론
ex) 음악 추천 시스템 -> 다른 사람들이 들은 곡들을 바탕으로 어떤 곡들이 서로 비슷한지 알아냄.
- 협업 필터링을 활용한 추천에서는 얕은 모델들이 아직까지는 상당 부분 우위를 점하고 있음. (행렬 분해 / 오토인코더 / 디노이징 오토인코더)
- 행렬 분해(matrix factorization) : 행렬을 랭크가 작은 두 행렬로 나누고, 나뉜 두 행렬의 곱이 원래 행렬과 비슷하게 나오도록 학습하는 방법. (압축하고 복원하는 과정에서 원래 유저가 소비하지 않았던 곡들에 대한 숫자들이 나오는데, 이 숫자들을 유저에 대한 해당 곡의 계산된 선호도라고 볼 수 있음.)
* 추천 시 유별난 요구사항이 없는 경우에 주로 사용
- 오토인코더(autoencoder): 행렬 분해와 비슷하게 입력 데이터를 원래의 차원보다 적은 데이터로 줄인 후에, 변환한 데이터를 기반으로 원래의 데이터를 복원하는 구조.
* 행렬 분해 보다 더 유연함.
* 모델에서 더 다양한 정보를 얻고 싶은 경우 사용.
한 문장의 설명을 듣고 몽타주를 그리는 과정과 유사
(몽타주는 초상화와 다르게 제한된 정보를 이용해 최대한 원본에 가깝게 그려내는 것이기 때문에, 주어지는 정보는 높은 가치가 있어야 함. + 설명을 듣고 그림을 그리는 사람의 실력이 좋아야 함.)
즉, 오토인코더는 " 몽타주를 그리는 과정에서 한 문장을 설명하는 사람과 이를 듣고 몽타주를 그리는 사람이 서로 합을 맞춰가는 과정"과 유사함.

강제로 정보를 축약해서 표현하고 이를 복원하는 과정에서 원본 값이 그대로 나오기보다 원본에서 가장 중요한 핵심 값들이 나오는 방식임.
음악 플레이리스트에서의 오토인코더 적용 > 현재 플레이리스트에 해당 곡이 들어있다면 이 값을 1로 두고, 들어있지 않다면 값을 0으로 두는 방식으로 플레이리스트를 표현함.이후, 인코더 스텝에서 나온 한 문장 설명(100여 개의 숫자들 = 임베딩)을 기반으로 원래 플레이리스트에 들어있었을 곡들이 무엇인지를 유추하는 작업을 진행함.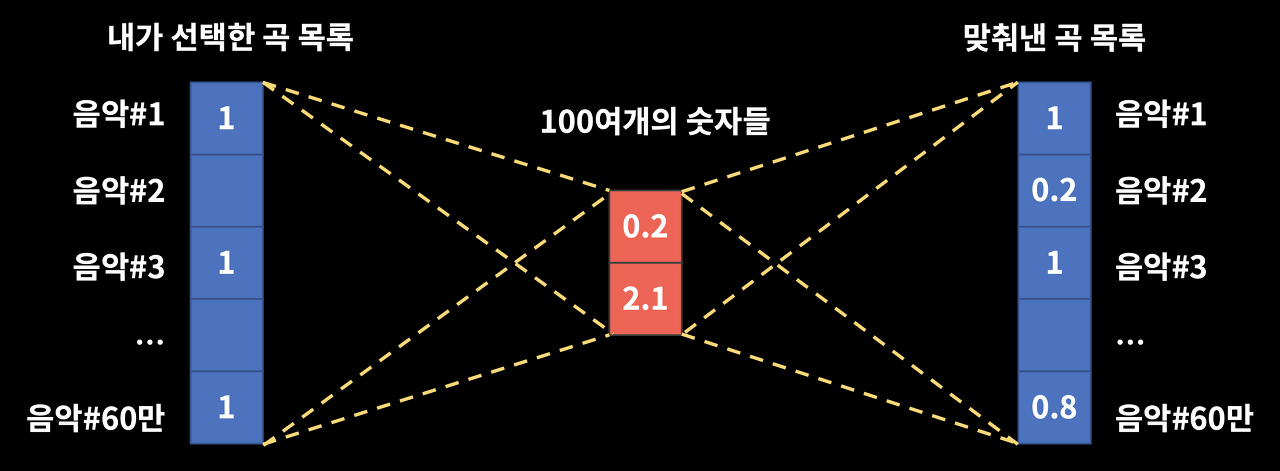
- 디노이징 오토인코더(denoising autoencoder): 노이즈가 낀 인풋을 가지고 원본을 복원하는 태스크를 수행하는 오토인코더.
지금까지와 같이 모든 곡을 입력으로 넣지 않고 내가 들은 곡의 일부만 보여주고 나머지 곡들을 맞추는 태스크를 학습시킨다면, 시드 곡들을 모두 보여주는 경우에도 이 곡들을 들었을 때 어울리는 곡을 추천해 줄 수 있을 것이라 기대할 수 있음.
ex) 걸그룹 노래만 들어있는 플레이리스트보이는 두 곡을 단서로 숨겨진 두 곡을 맞추는 것을 학습하면 꼭 맞추지는 못하더라도, 비슷한 곡을 추출해 내는 모델이 학습될 것이라 기대할 수 있음.
틀린 부분은 다음 시도에는 맞출 수 있도록 진행해가며 모델을 학습시킬 수 있음.
(디노이징 오토인코더 = 노이즈가 낀 인풋을 가지고 원본을 복원하는 태스크를 수행하는 오토인코더)
- 유연한 모델 형태를 가지는 오토인코더는 곡만 맞추는 것이 아닌 태그 등의 부차적인 정보도 같이 넣을 수 있음.
- 학습을 할 때 입력으로 곡 목록을 넣어주고 이 곡 목록에서 latent feature(숨어있는 특징)를 뽑은 후에, 디코딩 시 곡 목록과 태그도 같이 학습을 함으로써 이 태그들이 곡을 설명하는 역할을 하도록 할 수 있음.
- 곡들을 넣고 만들어진 latent feature를 보고 거기서 바로 태그를 맞추는 태스크로 설정할 수도 있고, 입력에서부터 태그를 넣어 레이턴트 피쳐에도 태그의 영향이 있도록 모델을 구성할 수도 있음.
* 모델을 더 강하게 키우기 위해 환경을 더 어렵게 만듦.
학습된 임베딩의 활용 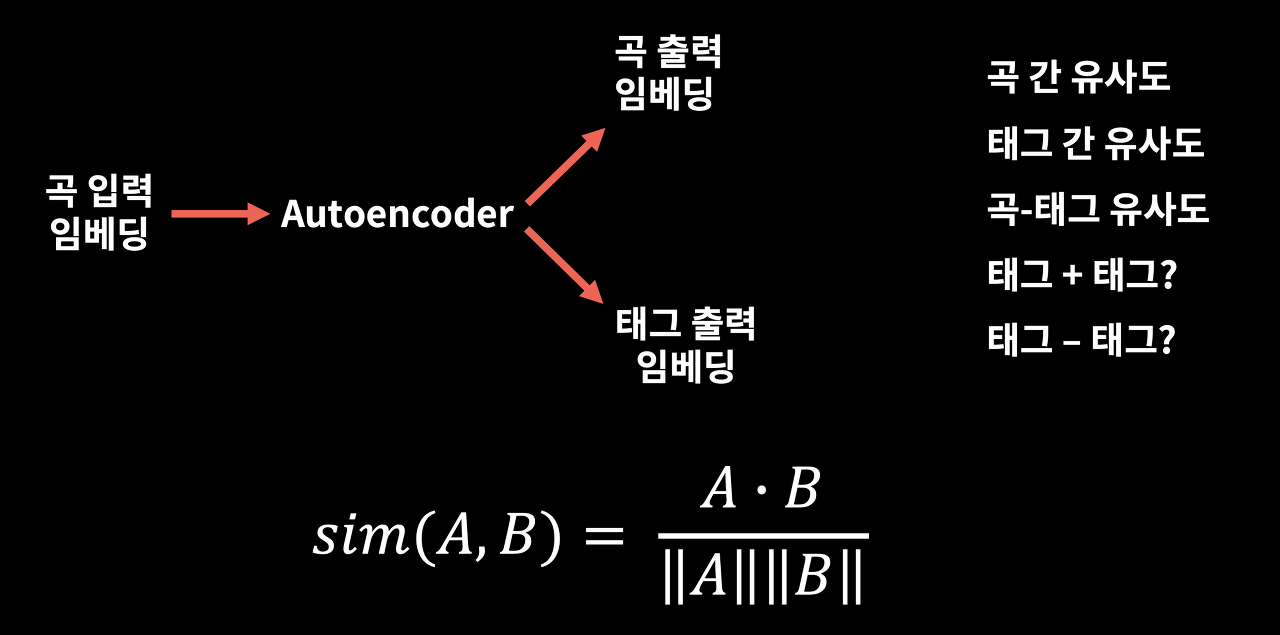
앞에서 설명한 방법으로 학습된 임베딩을 활용해 여러 가지 유사도 태스크를 진행할 수 있다. 원래 트레이닝 목적인 곡들을 넣고 해당 곡과 유사한 곡과 태그들을 추천받는 것뿐만 아니라, 학습된 임베딩을 가지고 임베딩 간 유사도를 활용해서 여러 가지 흥미로운 값들을 뽑아낼 수 있다.
곡 간 유사도, 태그 간 유사도, 그리고 곡과 태그의 유사도 등을 구할 수도 있고, 곡 임베딩과 태그 임베딩이 같은 공간 상에 분포해있다고 가정하면 마치 사칙연산을 하듯이 해당 임베딩들을 더하고 빼서 그 값이 어떤 곡의 태그와 유사한지 확인할 수도 있다.
- 태그 간 유사도
- 태그 결합성(composability) – 더하기
- 태그 결합성 (Composability) – 빼기
- ‘곡 + 태그’ 그리고 추천 플레이리스트
(원래 목표였던 곡과 태그를 바탕으로 플레이리스트를 추천받는 태스크)
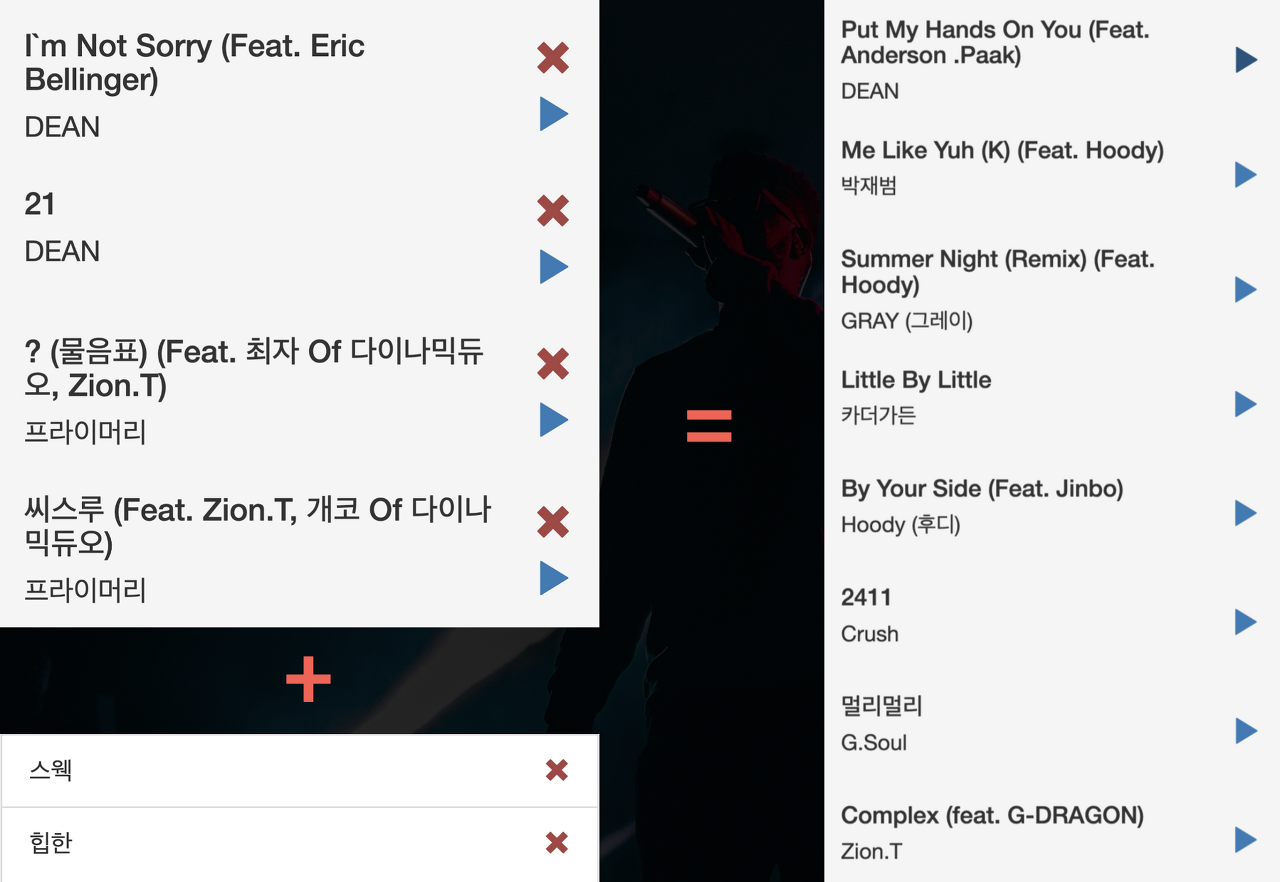



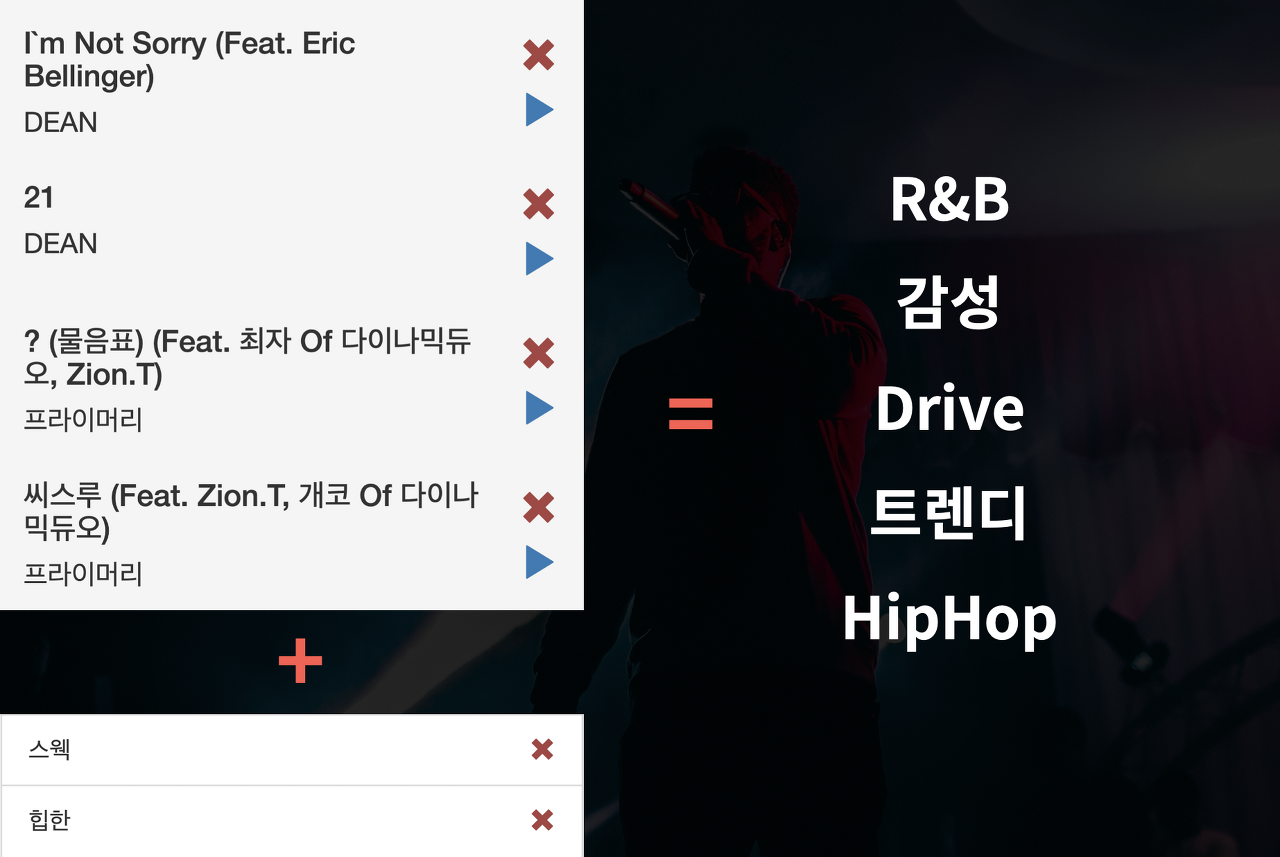
카카오에서 이 글은 아레나 3회 대회에 앞서 참가자들의 이해를 돕기 위해 작성한 글이며, 대회 참가자들은 위에서 설명한 방법보다 더 창의적이고 혁신적인 방법으로 유의미한 결과를 얻기를 희망한다고 말했다.
나도 공부 열심히해서 꼭 카카오 아레나 참가해보는 날이 오기를 .. ✊🏻
