머신러닝 과정 이해하기
-
데이터수집
크롤링 또는 DB데이터를 통해 데이터수집 -
데이터분석 및 전처리
수집한 데이터를 분석하고 머신러닝에 사용할 형태로 전처리 -
머신러닝 학습
머신러닝 모델을 사용하여 데이터를 학습 -
머신러닝 평가
학습된 머신러닝 모델을 평가용 데이터를 사용하여 평가
잘 안될 때는 전 과정으로 돌아가서 반복해서 수행하기도 한다.
데이터 전처리의 역할
-
머신러닝의 입력 형태로 데이터 변환 (특성 엔지니어링)
-
결측값 및 이상치를 처리하여 데이터 정제
-
학습용 및 평가용 데이터 분리
왜 데이터 전처리가 필요할까?
- 데이터 변환
대부분의 머신러닝 모델은 숫자데이터를 입력 받는다.
범주화 데이터도 수치화할 필요가 있다.
일반적으로 행렬 형태로 입력 -> 머신러닝 모델
실제 데이터셋 -> 머신러닝 모델이 이해할 수 없는 형태로 되어있음
예) 이미지 데이터, 자연어 데이터, 범주형 데이터, 시계열 데이터
-> 데이터 전처리 -> 머신러닝 모델
- 데이터 정제
전처리를 통하여 결측값 및 이상치를 처리
결측값과 이상치가 있는 데이터
결측값이나 이상치가 있는 경우 사용할 수 없거나 성능이 떨어진다.
- 데이터 분리
전처리를 통하여 학습용과 평가용 데이터를 분리
꼭 분리를 해줘야 학습용 데이터 따로 평가용 데이터 따로 해줘야함.
학습데이터에 원본 데이터를 다 쓰면, 평가의 객관성이 떨어지게 됨. 객관성을 얻기 위해 평가용 데이터를 분리해둔다는 점.
너무 학습용 데이터에 몰입해서 학습할 경우 다른 데이터가 들어왔을 때 객관성이 떨어지는 결과가 나올 수 있어서 그런지 아닌지 평가하기 위해서 분리된 평가데이터가 필요.
범주형 자료 전처리
- 타이타닉 생존자 데이터 살펴보기
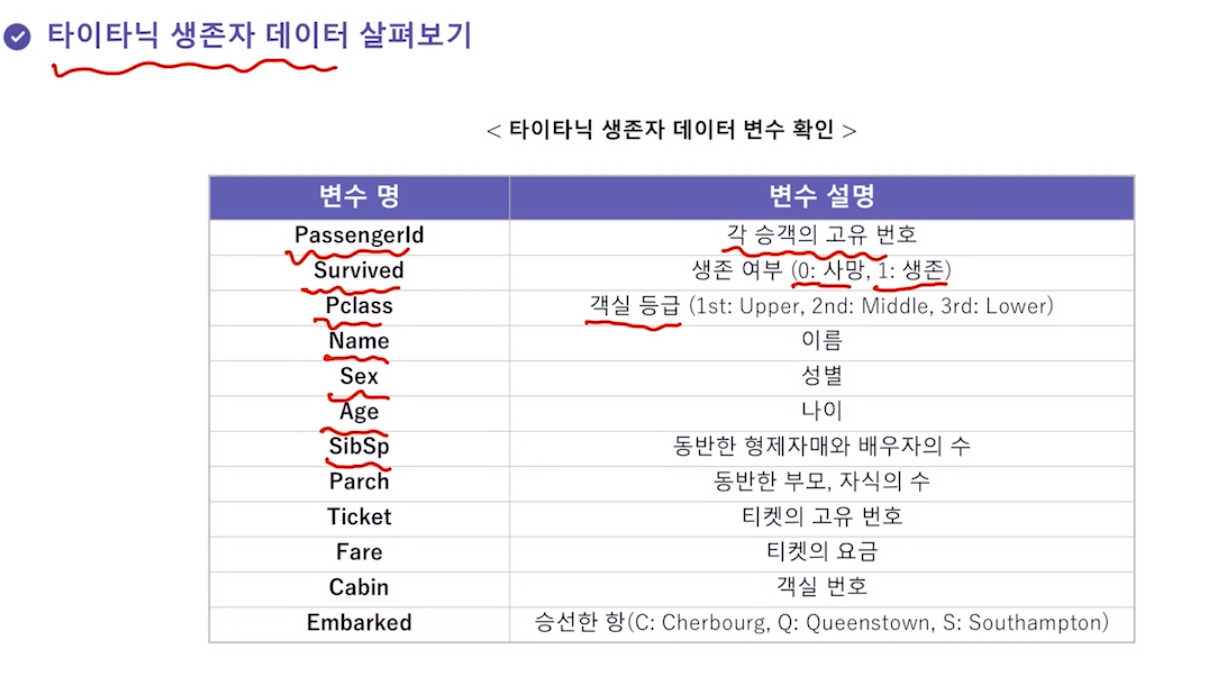
범주형 데이터는 몇개의 범주로 나누어진 자료.
나이, 형제수, 부모수, 요금 등은 수치형자료
나머지는 범주형 자료
범주형 자료는 다시 명목형 자료와 순서형 자료로.
객실클래스만 순서형 자료.(1등급, 2등급, 3등급)
-
범주형 자료 변환하기
- 명목형 자료 변환하기 - 수치 맵핑 변환
-
일반적으로 범주를 0, 1로 맵핑
-
범주를 숫자로 변환하는 것을 수치맵핑 변환이라고 한다.
-
0과 1이 가장 무난하고 다양한 방법이 있고 모델에 따라 성능이 달라진다.
-
3개 이상인 경우 0,1,2 등 가장 간단한 건 역시 0부터 1씩 올라가면서 설정
import pandas as pd from elice_utils import EliceUtils elice_utils = EliceUtils()
# 데이터를 읽어옵니다.
titanic = pd.read_csv('./data/titanic.csv')
print('변환 전: \n',titanic['Sex'].head())
"""
1. replace를 사용하여 male -> 0, female -> 1로 변환합니다.
"""
titanic = titanic.replace({"male":0, "female":1})
# 변환한 성별 데이터를 출력합니다.
print('\n변환 후: \n',titanic['Sex'].head())
```
2. 명목형 자료 변환 - 더미 기법 Dummy
- 각 범주를 0, 1로 변환하는데 모든 범주를 컬럼으로 만들고 아닌 것엔 전부 0, 해당하는 것엔 1을 넣는 방식 (수치맵핑은 한가지 변수에다 여러 숫자를 넣는 것, 더미 기법은 범주 수만큼 변수를 만들어서 그 중 하나에만 1을)
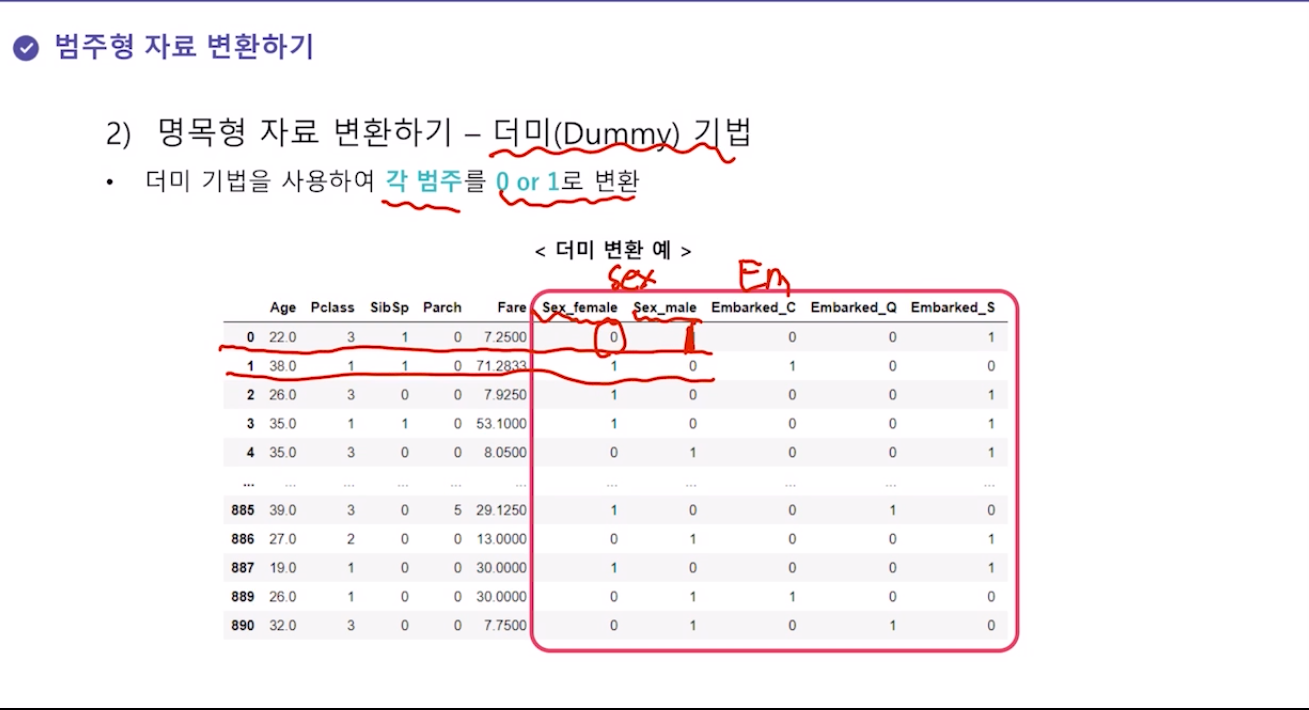
```python
import pandas as pd
from elice_utils import EliceUtils
elice_utils = EliceUtils()
# 데이터를 읽어옵니다.
titanic = pd.read_csv('./data/titanic.csv')
print('변환 전: \n',titanic['Embarked'].head())
"""
1. get_dummies를 사용하여 변환합니다.
"""
dummies = pd.get_dummies(titanic[['Embarked']])
# 변환한 Embarked 데이터를 출력합니다.
print('\n변환 후: \n',dummies.head())
```
3. 순서형 자료 변환하기 - 수치 맵핑 변환
- 수치에 맵핑하여 변환하지만, 수치간 크기 차이는 커스텀 가능
- 크기 차이가 머신러닝 결과에 영향을 끼칠 수 있음

- 사람의 의도에 따라 수치간 크기 차이를 둘 수 있다