NIPA AI 교육
1.머신러닝 개론 - NIPA AI 교육

머신러닝은 빅데이터를 분석할 수 있는 강력한 툴기존 통계학 및 시각화 방법의 한계를 해결예측, 패턴 파악, 추천시스템 등의 기능을 수행머신러닝이란?명시적으로 프로그래밍을 하지 않고도 컴퓨터가 학습할 수 있는 능력을 갖게 하는 것지도학습 / 비지도학습 / 강화학습 이 있
2.자료 형태의 이해
자료의 형태를 파악하는 것은 머신러닝 사용을 위한 필수 과정데이터가 어떻게 구성되어 있을까?어떤 머신러닝 모델을 사용해야할까?데이터 전처리를 어떻게 해야할까?자료형태구분 1\. 수치형자료 1\. 연속형자료 2\. 이산형자료범주형자료순위형자료명목형자료수
3.범주형 자료의 요약
다수의 범주가 반복해서 관측관측값의 크기보다 포함되는 범주에 관심각 범주에 속하는 관측값의 개수를 측정\-> 전체에서 차지하는 각 범주의 비율 파악\-> 효율적으로 범주 간의 차이점을 비교 가능많이 쓰이는 것 - 도수분포표가장 대표적인 예) 강의 만족도 설문도수(개수)
4.수치형 자료의 요약
범주형 자료와 달리 수치로 구성되어 있기에 통계값을 사용한 요약이 가능함시각적 자료로는 이론적 근거 제시가 쉽지 않은 단점을 보완함많은 양의 자료를 의미있는 수치로 요약하여 대략적인 분포상태를 파악 가능그래프 등을 꼭 그려서 보여주지 않아도 통계값 수치를 통해 의미 파
5.머신러닝 과정 이해하기
데이터수집크롤링 또는 DB데이터를 통해 데이터수집데이터분석 및 전처리수집한 데이터를 분석하고 머신러닝에 사용할 형태로 전처리머신러닝 학습머신러닝 모델을 사용하여 데이터를 학습머신러닝 평가학습된 머신러닝 모델을 평가용 데이터를 사용하여 평가잘 안될 때는 전 과정으로 돌아
6.데이터 정제 및 분리하기

결측값 처리대체로 머신러닝 모델의 입력값으로 결측값을 사용할 수 없음.1) 결측값 존재하는 샘플 삭제 -> 결측값이 있는 row 전체를 삭제2) 결측값이 많이 존재하는 변수 삭제 -> 결측값이 많다고 판단되는 column 전체를 삭제3) 결측값을 다른 값으로 대체 ->
7.지도학습 - 회귀 / 회귀 개념 알아보기

문제 정의와 해결 방안선형관계: A, B가 있을 때, A가 증가하면 B가 증가하거나, A가 증가하면 B가 감소하는, 서로 일관되게 변화량이 연관되어있을 때 선형적인 관계라고 일단 단순하게는 그렇게 생각하면 된다.평균기온에 따른 아이스크림 판매량\-> 지도학습 -> 판매
8.단순 선형 회귀 분석하기
데이터 전처리기계학습 라이브러리 scikit-learn 을 사용하면 Loss 함수를 최솟값으로 만드는 β0, β1을 쉽게 구할 수 있습니다. 주어진 데이터를 sklearn에서 불러 올 선형 모델에 적용하기 위해서는 전 처리가 필요합니다. 이번 실습에서는 sklear
9.다중 선형 회귀

하나의 Label 데이터를 예측하기 위해 하나보다 많은 수의 Feature데이터, 값들이 들어갈 때각각의 입력값 X에 맞는 기울기값들을 찾아주어야 함.여러 개의 입력값과 결과값 간의 관계 확인 가능어떤 입력값이 결과값에 어떠한 영향을 미치는지 알 수 있음(각 X들의 기
10.회귀 평가 지표
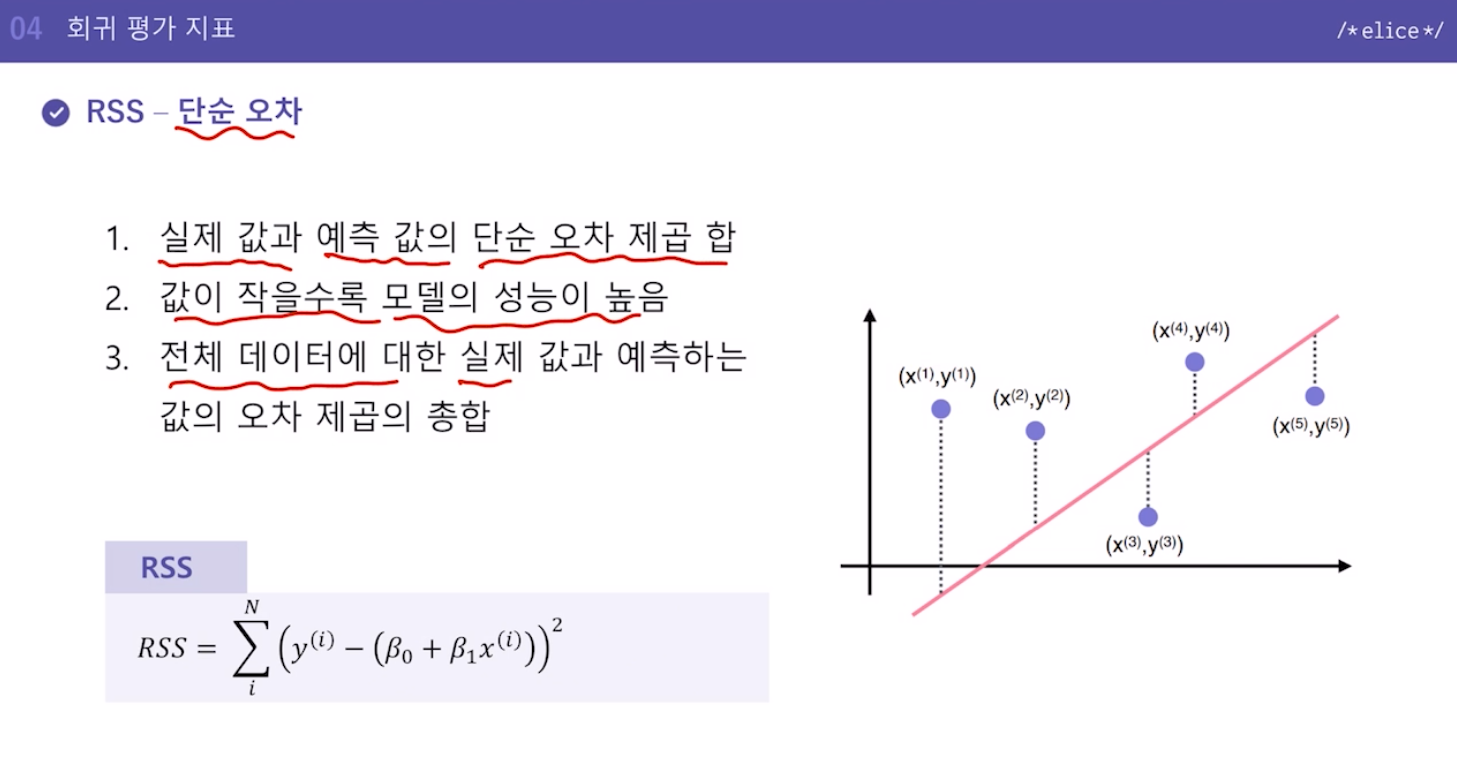
어떤 모델이 좋은 모델인지 어떻게 평가?목표를 얼마나 잘 달성했는지 정도를 평가해야 함실제 값과 모델이 예측하는 값의 차이에 기반한 평가 방법 사용 => Loss함수처럼예시) RSS, MSE, MAE, MAPE, R^2실제 값과 예측 값의 단순 오차 제곱 합Loss와
11.지도학습 - 분류 / 분류 개념 알아보기

데이터: 과거 기상정보(풍속) X와 그에 다른 항공 지연여부 Y목표: 현재 풍속에 따른 항공 지연 여부 예측하기\-> Label인 지연여부데이터가 범주형임(수치형이 아님)수치형이면 회귀, 수치형이 아닐 때해결방안 -> 분류 알고리즘주어진 입력 값이 어떤 클래스에 속할지
12.의사결정나무 - 모델 구조
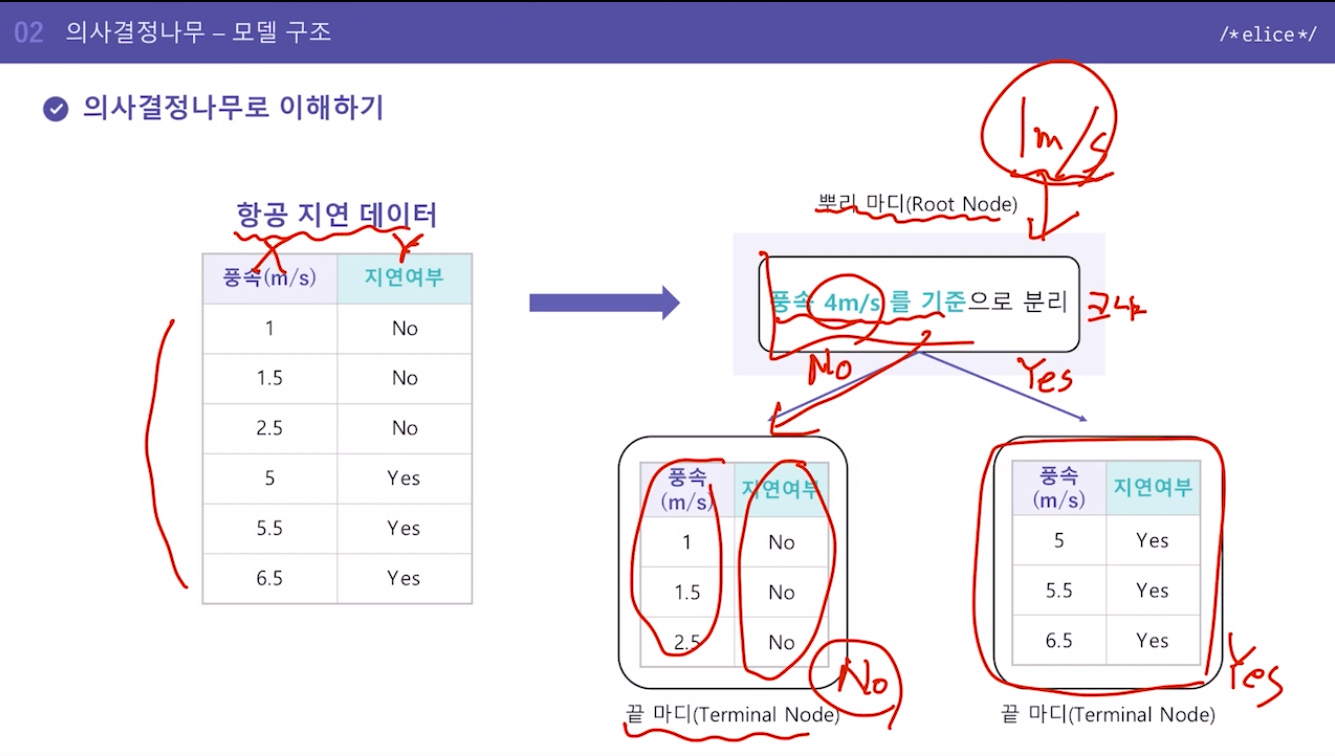
스무고개와 같이 특정 질문들을 통해 정답을 찾아가는 모델최상단 뿌리마디Root Node 에서부터 마지막 끝마디Terminal Node까지 아래 방향으로 진행예측할 수 있게 질문을 만들고 그 질문에 답함으로써 예측하는 것질문 하나로 안될 경우 중간 마디Internal N
13.의사결정나무 - 불순도
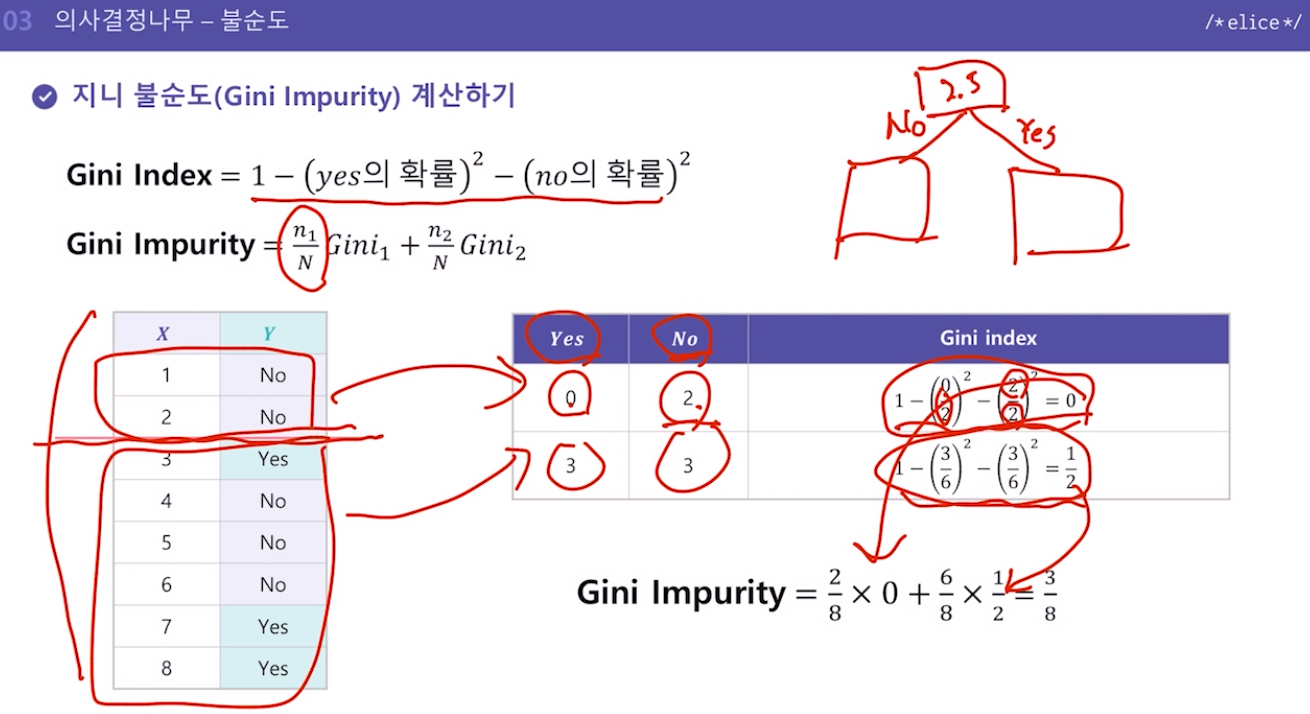
데이터의 불순도를 최소화하는 기준으로 나누자.불순도 : 다른 데이터가 섞여 있는 정도데이터가 많이 섞여있을수록 불순도가 높고,적게 섞여있을수록 불순도가 낮다.지니 불순도지니계수해당 구역 안에서 특정 클래스에 속하는 데이터의 비율을 모두 제외한 값즉, 다양성을 계산하는
14.의사결정나무 실습
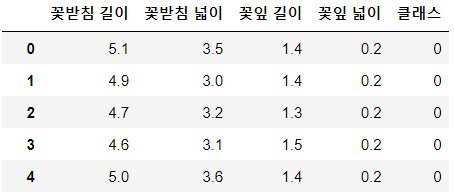
이번 실습에서는 분류 문제 해결을 위해 Iris 데이터를 사용합니다. Iris 데이터는 아래와 같이 꽃받침 길이, 꽃받침 넓이, 꽃잎 길이, 꽃잎 넓이 네 가지 변수와 세 종류의 붓꽃 클래스로 구성되어 있습니다.꽃받침 길이, 꽃받침 넓이, 꽃잎 길이, 꽃잎 넓이 네 가
15.분류 평가 지표
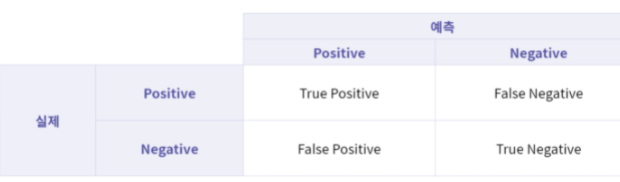
True Positive TP: 실제 Positive인 값을 Positive라고 예측(정답)True Negative TN: 실제 Negative인 값을 Negative라고 예측(정답)False Positive FP: 실제 Negative인 값을 Positive라고 예측
16.딥러닝 시작하기(딥러닝 개론)
인공 신경망으로 알려진 딥러닝의 개념을 이해하고 신경망의 가장 기본 단위인 퍼셉트론에 대하여 학습합니다.가장 많이 사용되고 있는 딥러닝 프레임워크인 텐서플로우 사용법을 익히고 신경망을 구현하는 것을 학습합니다.이미지 및 자연어 처리에서 사용하는 CNN, RNN 모델에
17.딥러닝 개론 - 퍼셉트론
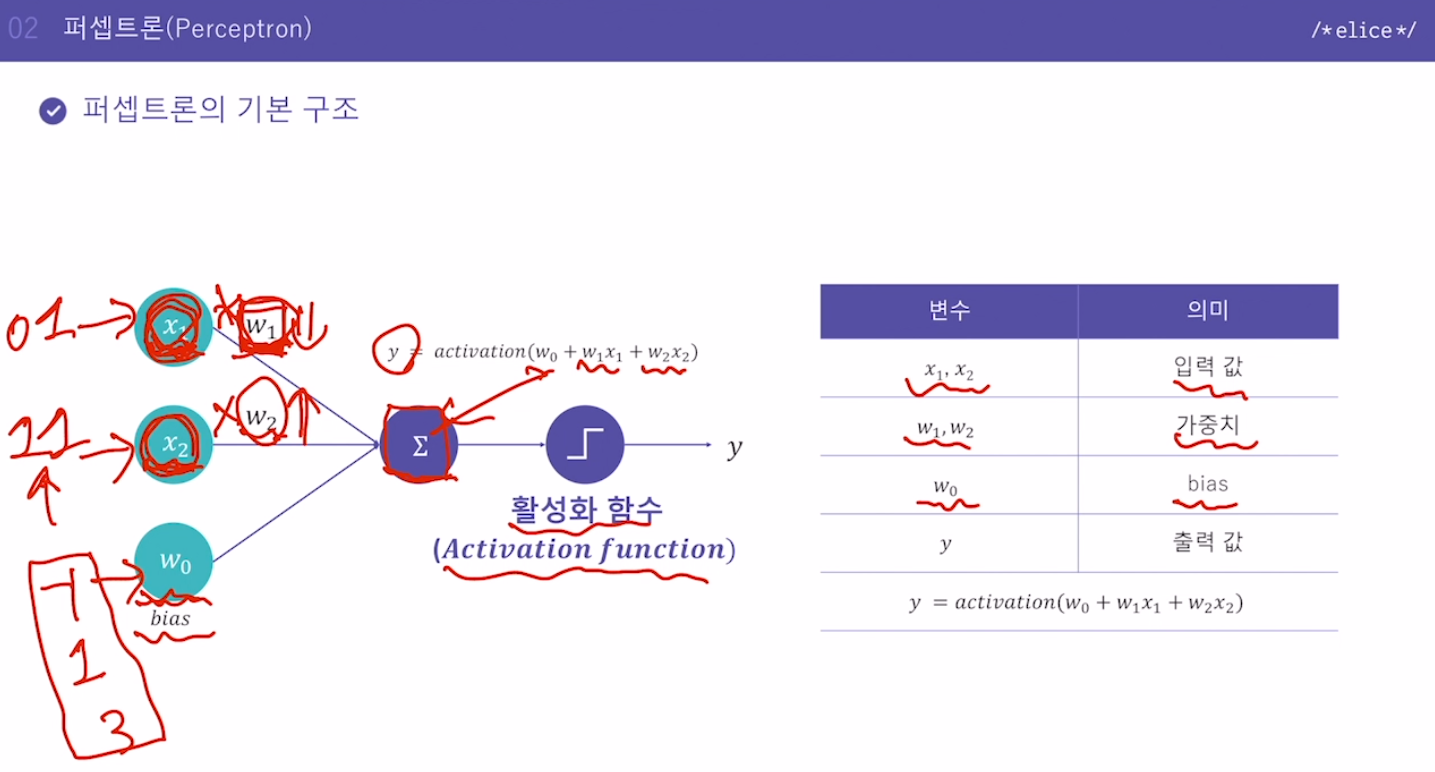
얼굴 인식, 숫자 및 문자 인식(몇가지 패턴을 정해서 맞는지 안맞는지 검사)이 '인식을 위한 특정한 패턴'을 사람이 직접 파악, 결정어떤 패턴이 있어야 얼굴이냐, 어떤 패턴이 있어야 숫자 '9'이냐 같은 것.신경망은 이 패턴 파악을 신경망이 하게 됨딥러닝의 가장 기본적
18.딥러닝 개론 - 다층퍼셉트론
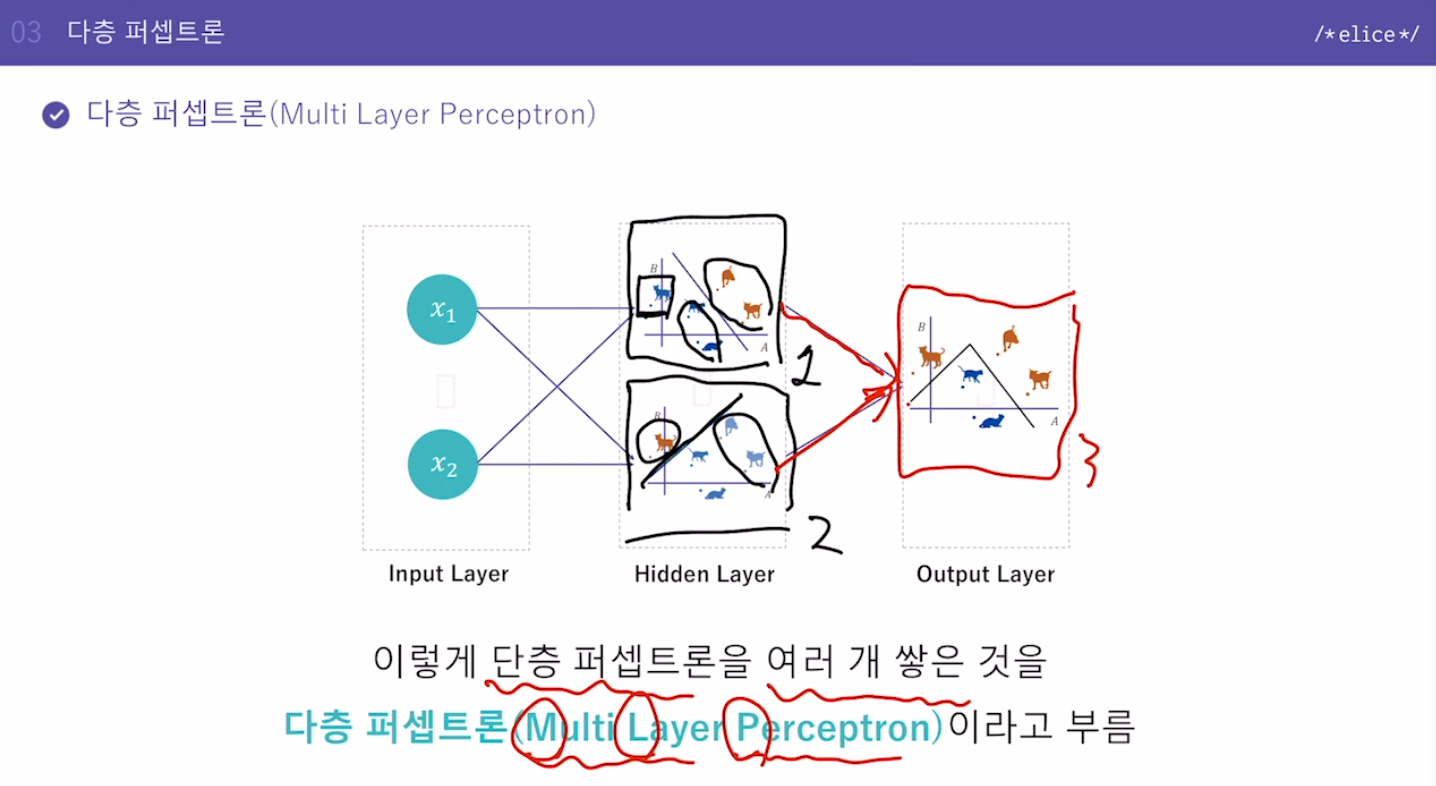
다층퍼셉트론의 발견으로 첫번째 빙하기의 끝비 선형적인 문제 해결정확하진 않지만: 선 하나로 분류할 수 없는 문제 라고 단순화해서 일단 이해(비선형적인 문제)단층 퍼셉트론은 입력층과 출력층만 존재.단층 퍼셉트론을 여러 층으로 쌓아보기\-> 다층 퍼셉트론(Multi Lay
19.딥러닝 모델의 학습 방법
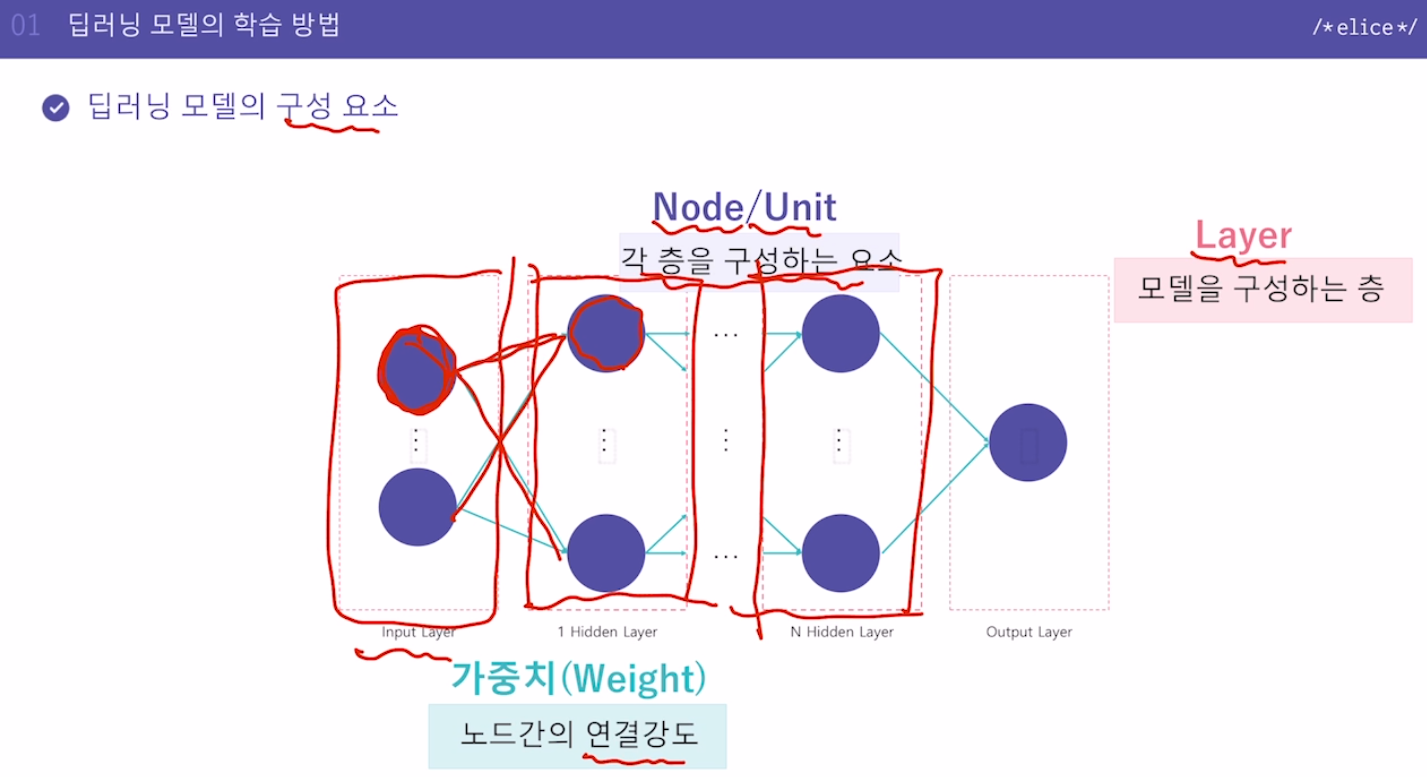
입력층과 출력층 사이 히든층이 많아진다면 깊은 신경망이라는 의미로 딥러닝이라는 단어 사용보라색원형요소(각 층을 구성하는 요소) - Node/Unit붉은색박스 - Layer(입력단, 출력단, 히든레이어)연결하는 녹색선 - 가중치Weight(노드간의 연결강도)예측값과 실제
20.텐서플로우로 딥러닝 구현하기 - 데이터 전처리
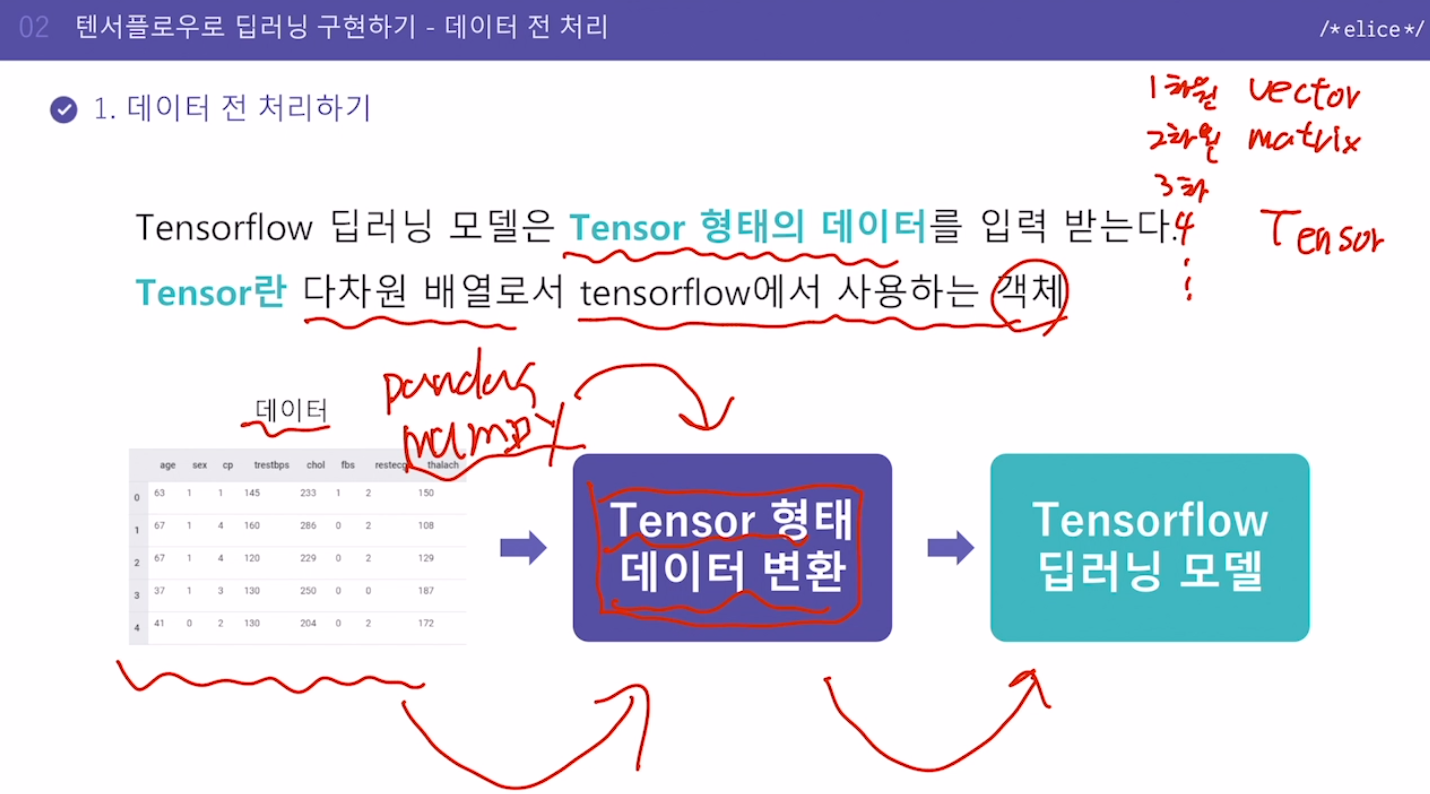
유연하고, 효율적이며, 확장성 있는 딥러닝 프레임워크대형 클러스터 컴퓨터부터 스마트폰까지 다양한 디바이스에서 동작 가능가장 많이 쓰이는 딥러닝프레임워크텐서플로우, 파이토치데이터 전처리하기딥러닝 모델 구축하기모델 학습시키기평가 및 예측하기Tensorflow 딥러닝 모델은
21.텐서플로우로 딥러닝 구현하기 - 모델 구현
Keras - 텐서플로우의 패키지로 제공되는 고수준API 딥러닝 모델을 간단하고 빠르게 구현 가능케라스를 사용하지 않고도 할 수 있지만, 처음 배우는 사용자에게는 매우 어려우므로 케라스를 활용해서 구현하는 법부터 학습모델 클래스 객체 생성tf.keras.models.S
22.이미지 처리를 위한 데이터 전처리
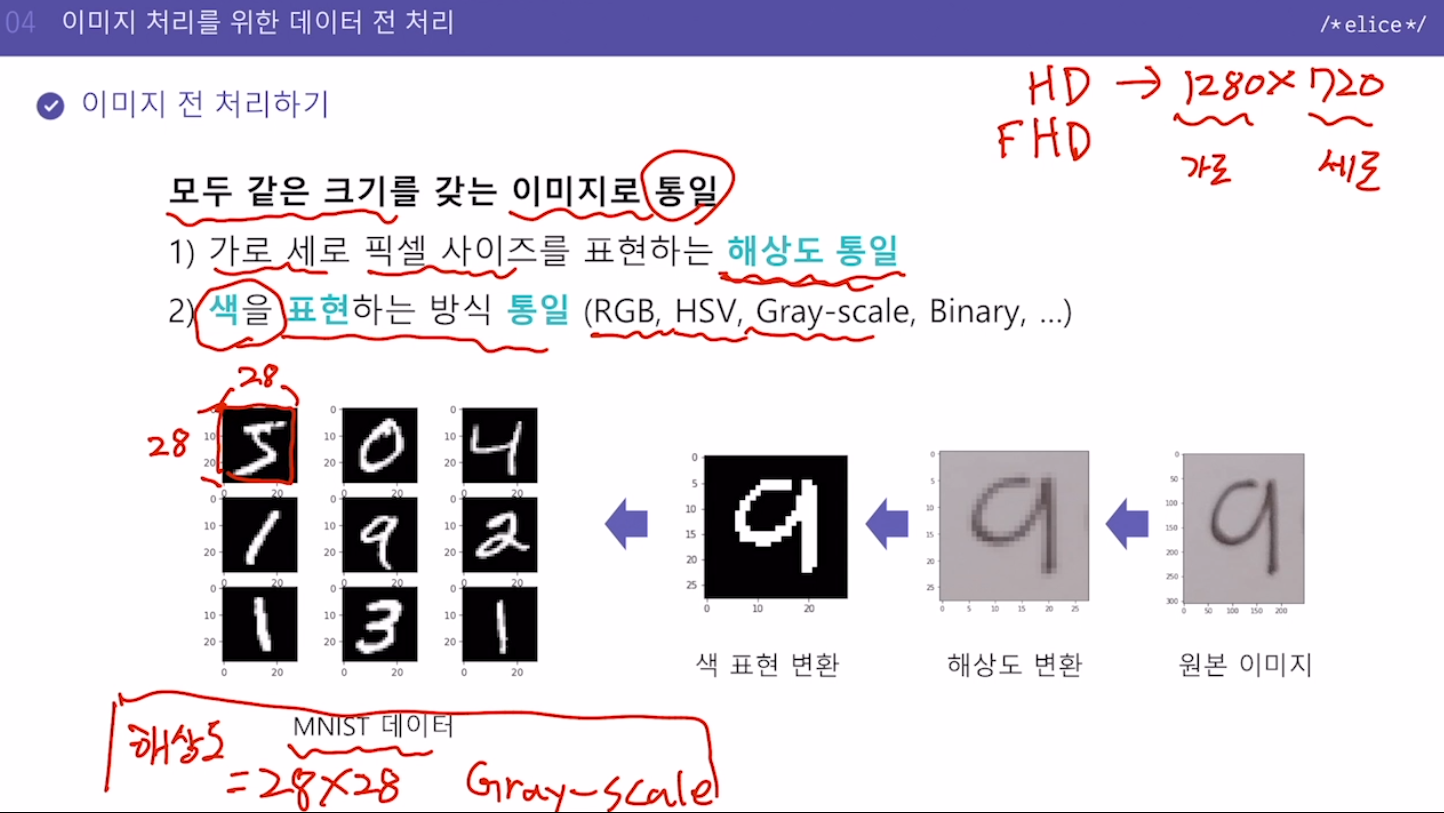
얼굴 인식 카메라화질 개선(Super Resolution)\*이미지 자동 태깅기존에 다루던 데이터들: 정형데이터 DataFrame형태로 정리되어있던.이미지 데이터는 그렇지 않음컴퓨터에게 이미지는 각 픽셀 값을 가진 숫자 배열로 인식픽셀당 갖고 있는 값은 해당 픽셀을 채
23.이미지 처리를 위한 딥러닝 모델
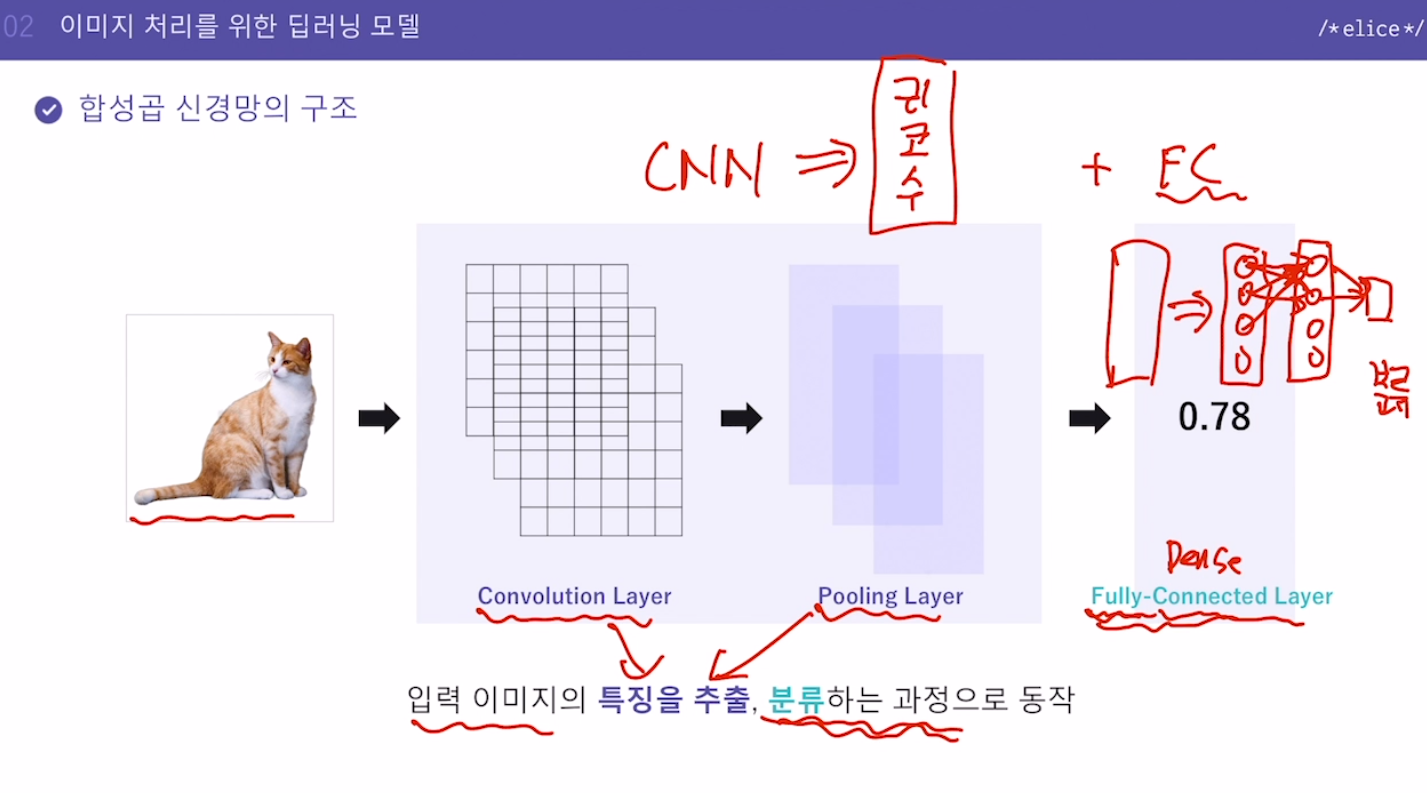
우선 이미지의 픽셀값 배열은 2차원 데이터 -> 2차원배열을 입력값으로 넣을 수 없으므로 1차원배열로 변환해야함변환방법: 6X6 배열이라면, row 1의 데이터 6개를 순서대로 넣고, row 2의 데이터 6개를 그 다음 순서대로 넣고, 총 36개 데이터가 있는 1차원
24.자연어 처리를 위한 데이터 전처리
기계번역모델 - 구글번역, 유튜브 자동자막 등음성인식 - 아이폰 시리, 네이버 클로바 등자연어 전 처리Preprocessing단어 표현Word Embedding모델 적용하기Modeling (딥러닝 모델 적용)원 상태 그대로의 자연어는 전처리 과정이 필요함굉장히 여러가지
25.자연어 처리를 위한 딥러닝 모델
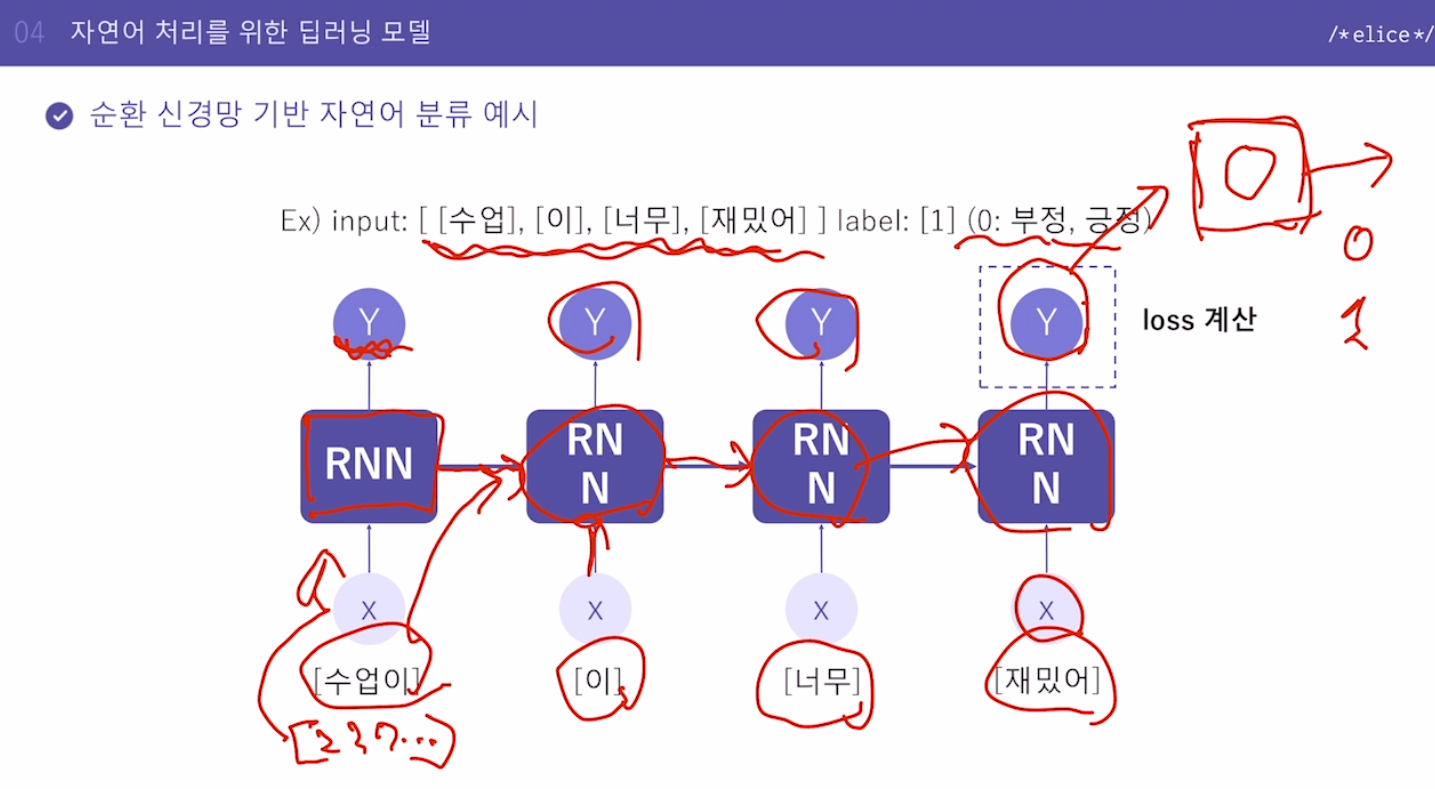
Bag of words의 치명적 단점 -> 토큰의 의미가 숫자에 반영되어있지 않음. (단순 숫자)CNN에서 픽셀별 데이터를 필터를 통해 특징을 추출해냈듯이, 워드 임베딩을 해서 의미를 부여Embedding table을 통해서 변환Bag of word의 인덱스에 따라 해
26.제조/IoT 산업 내 AI혁신과 스마트팩토리
오작동 모니터링제품 성능 모의 실험 digital twin가상의 공장에서 모의 실험데이터 기반 의사결정 최적화공정 효율 증대재고관리 및 물류자동화해당 도메인에서의 확실한 목표 확립데이터 분석 전문가와의 지속적 커뮤니케이션인공지능에 필요한 데이터를 확보할 수 있는 환경
27.이커머스 산업의 AI 혁신
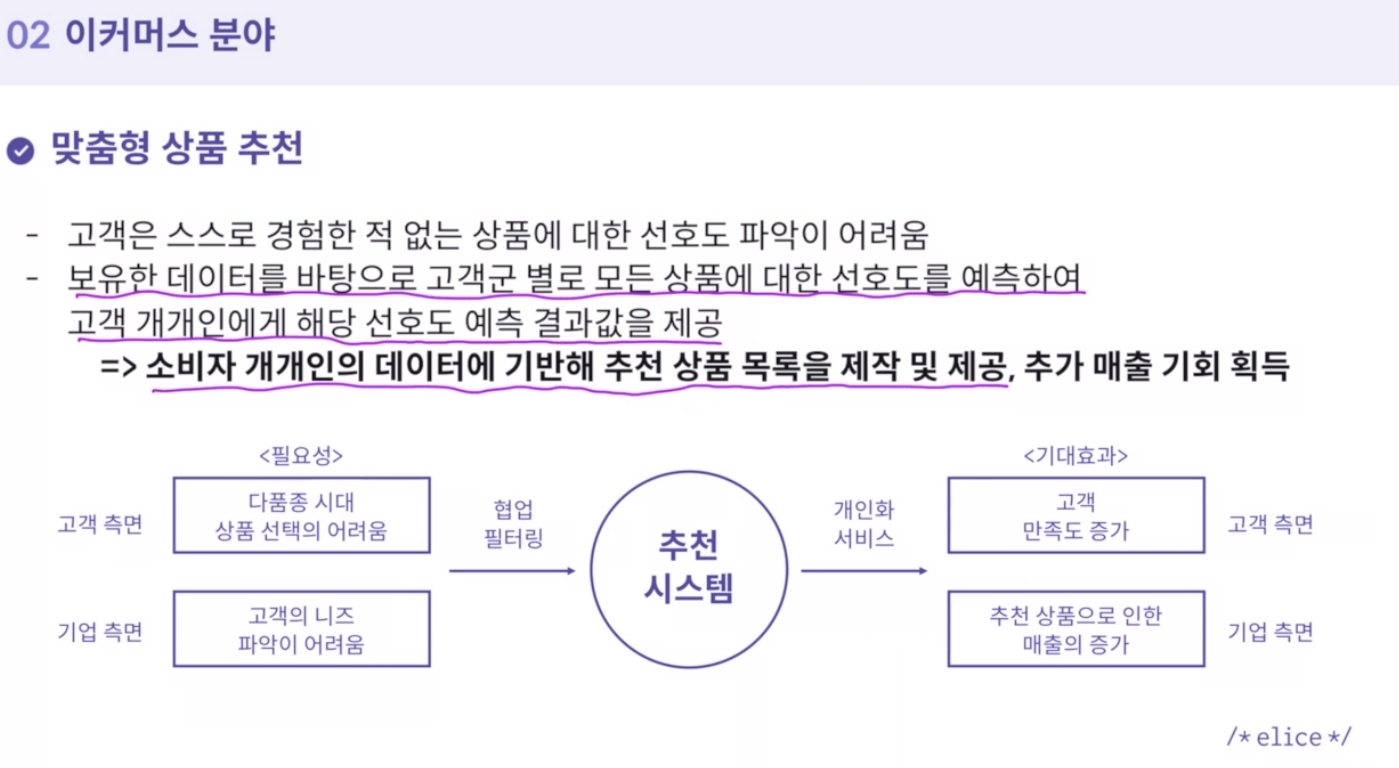
고객은 스스로 경험한 적 없는 상품에 대한 선호도 파악이 어려움미리 설정한 규칙 기반 추천이 아닌 고객 데이터에 따른 인공지능형 추천 알고리즘대표적: 유튜브 추천 알고리즘대부분의 조회수가 추천 영상으로 발생고객 개개인의 특성을 분석하여 소비자들 각각에 최적화된 서비스를
28.웹/앱 서비스 분야 AI 혁신
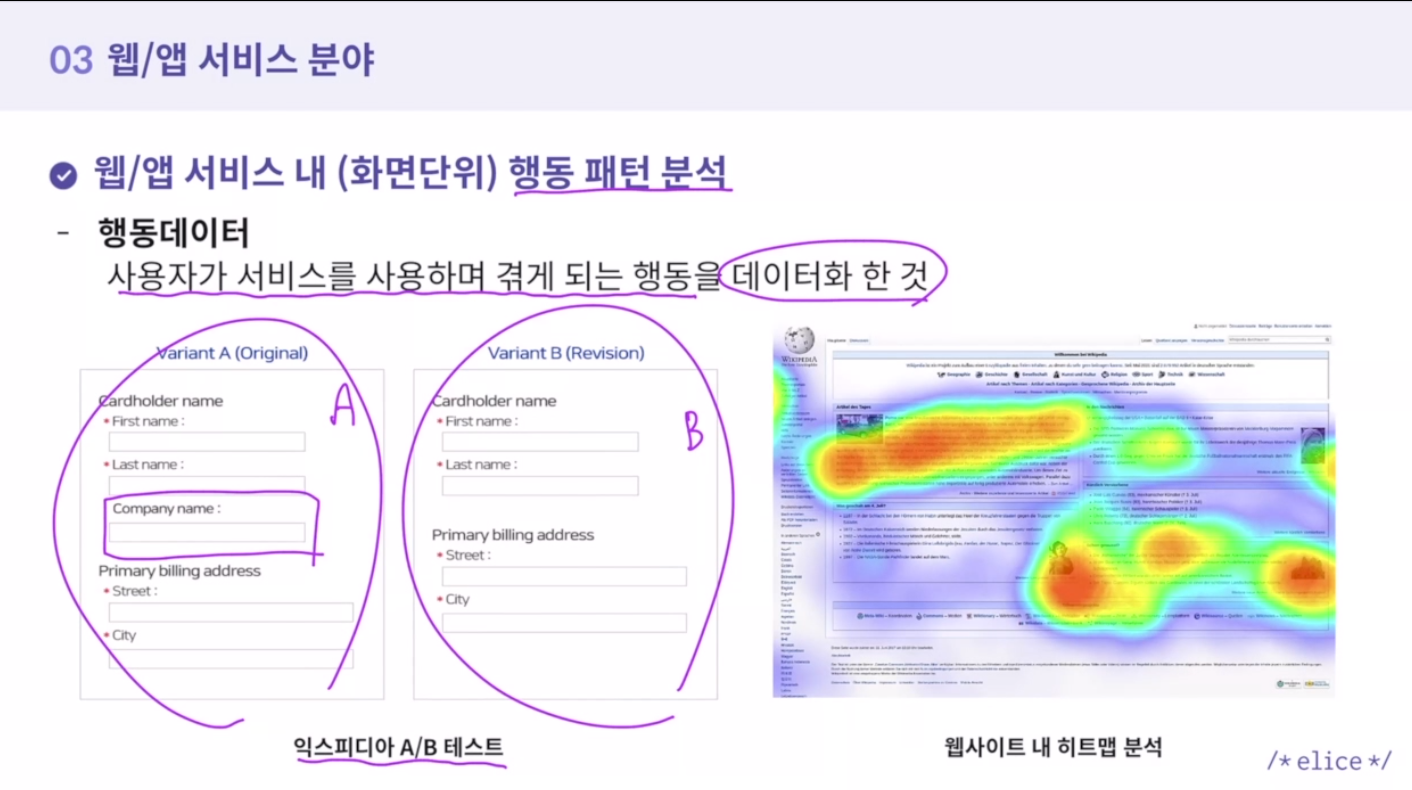
연령/성별, 지역, 트래픽 소스, 방문페이지, 제품 등의 측정 기준을 통해서 사용자의 특성 분석=> 사용자의 유지 이탈, 집단 간 상이한 행동 패턴 분석 가능예) 구글 애널리틱스(웹) / 구글 파이어베이스(앱)행동데이터사용자가 서비스를 사용하며 겪게 되는 행동을 데이터
29.응용과정 시험 - 실습

Fashion-MNIST 데이터 분류하기Fashion-MNIST 데이터란 의류, 가방, 신발 등의 패션 이미지들의 데이터셋으로 60,000개의 학습용 데이터 셋과 10,000개의 테스트 데이터 셋으로 이루어져 있습니다.각 이미지들은 28x28 크기의 흑백 이미지로, 총
30.금융/재무 산업에서의 AI혁신

1. 업무자동화 기존의 반복 업무를 자동화하는 SW 기술인 RPA(Robotic Process Automation)에 인공지능을 접목하여 스스로 판단하여 업무 수행을 하는 인지형 RPA 기술이 활용됨 기존-> 설계자가 하나하나 상황 발생에 어떻게 대응할 것인지
31.기본과정 테스트 - 실습
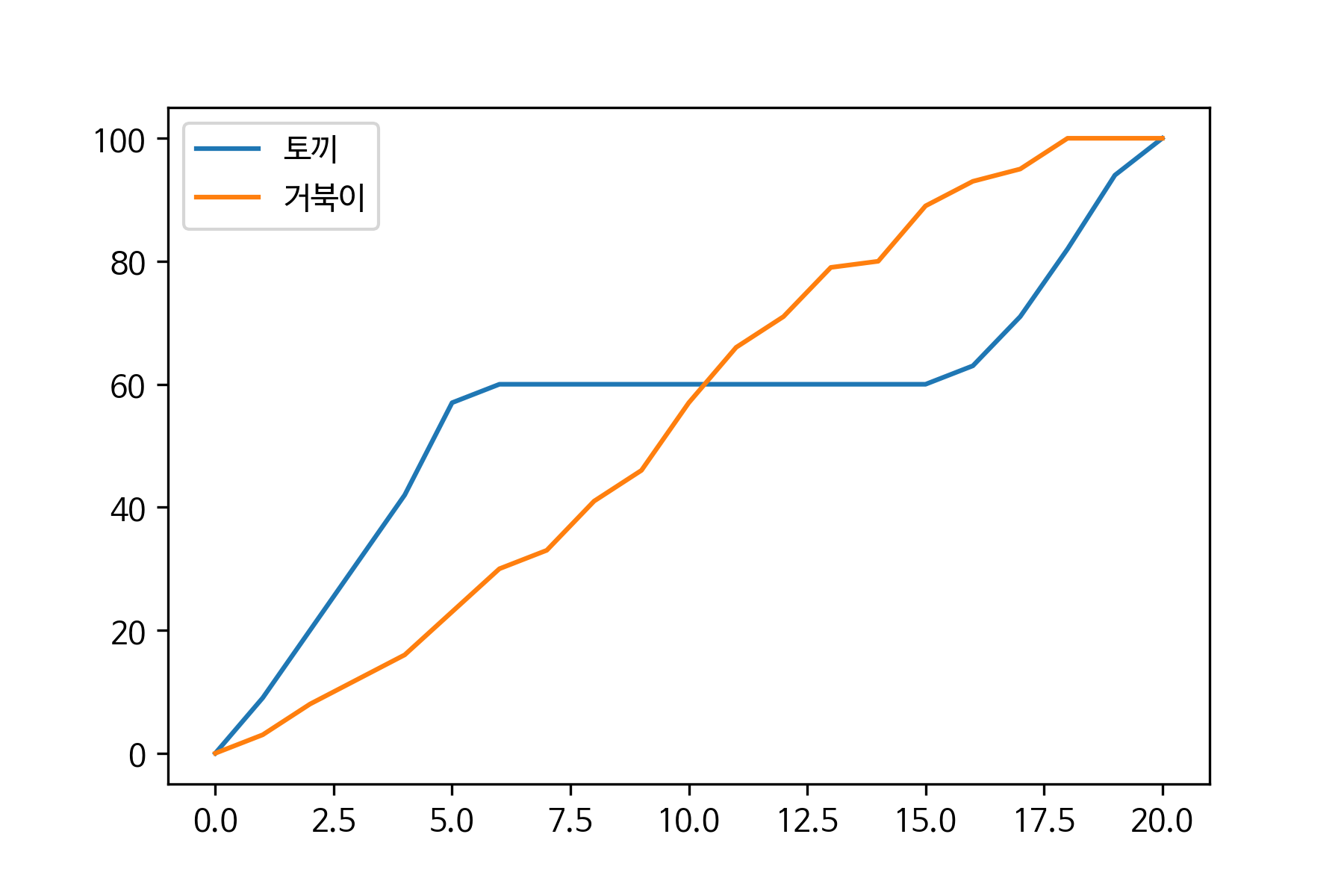
토끼와 거북이 경주 결과“나랑 달리기 시합하지 않을래?”토끼와 거북이가 달리기 시합을 하기로 했어요.공정한 경쟁을 위해서 1초마다 토끼와 거북이의 위치를 다른 동물이 기록하기로 하고 경주를 했네요.그 위치 데이터가 csv파일로 저장되어 있어요. 우리는 csv 파일을 읽