Design of a Lexical-Analyzer Generator
- 이전 Section에서 봤던 방법을 적용해서 lexical-analyzer가 어떻게 만들어지는지 확인해 볼 것이다.
- NFA, DFA 두 가지 관점에서 보자.
The structure of the Generated Analyzer
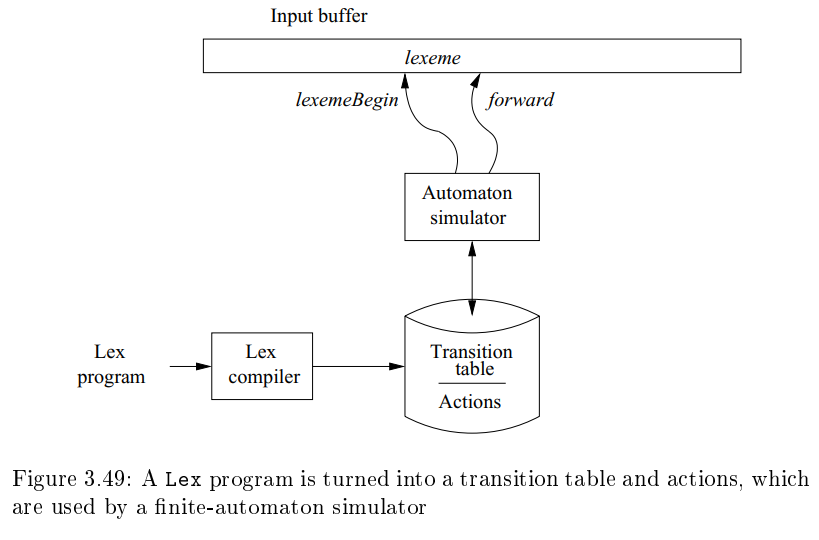
- lexical analyzer를 구성하는 프로그램에는 automaton을 simulate하는 fixed program이 있다.
- 그 외로는 Lex 프로그램 스스로가 만든 요소들로 구성되어 있다.
1. automaton을 위한 transition table
2. Lex를 통과해서 output으로 바로 pass 되는 함수들 (Section 3.5.2 참고)
3. input program으로부터의 action (automaton simulator로 부터 적당한 때에 행해질 코드들)
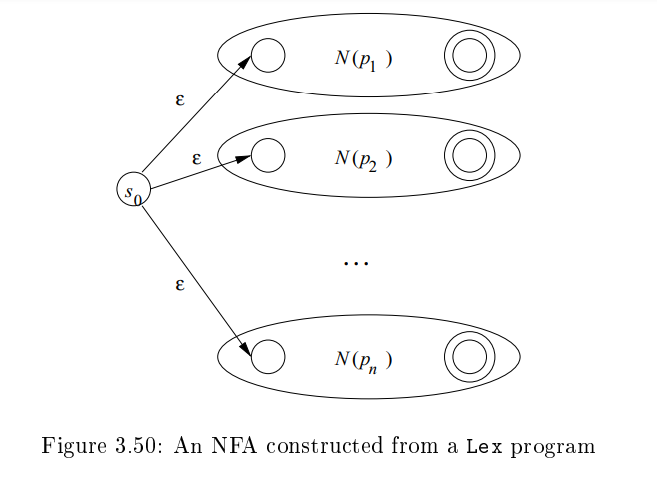
- automaton을 만들기 위해서, Lex program에 있는 regular-expression pattern을 NFA로 바꾼다.
- single automaton이 필요한 것이므로, 하나의 pattern 마다 존재하는 각 NFA 들을 하나로 합쳐야 한다. 아래 그림을 참고하세요.
Pattern Matching Based on NFA's
- lexemeBegin 부터 시작해서 forward 포인터를 옮겨가면서 NFA를 계산한다.
- NFA의 결과를 계산할 때에는 pattern을 만족시키는 가장 긴 prefix를 선택한다.
- 가장 긴 prefix를 만족시키는 accepting pattern이 여러 개인 경우 pattern이 등록된 순서대로 accept시킨다.
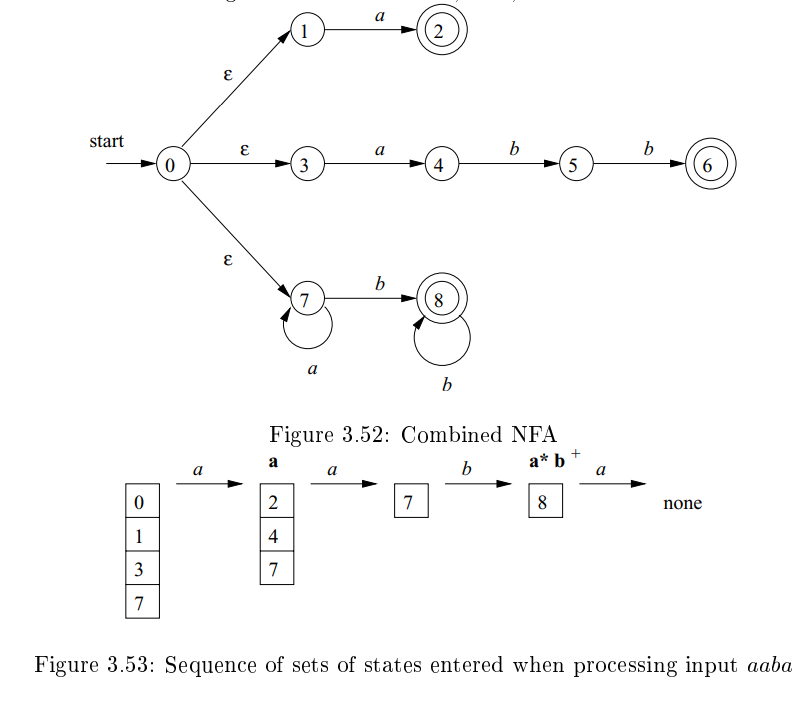
- 위 NFA를 aaba라는 문자열이 통과한다고 가정해보자.
- 일단 start state = 이다.
- 이후에 쭉 따라가면, b까지 가면 8state에 위치해 있을 것이고, 그 이후에는 states의 set이 비어있을 것이다.
- 그러므로 이 때 가장 긴 pattern을 찾는다.
- forward를 한 칸 씩 앞으로 되돌리면서 set of states에 final state가 나올 때까지 확인하고, 처음으로 나온다면 그 곳이 가장 긴 pattern을 찾은 것이다.
- 만약 여러 pattern이 존재한다면, pattern을 선언한 순서에서 앞에 나온 pattern을 택한다.
DFA's for Lexical Analyzers
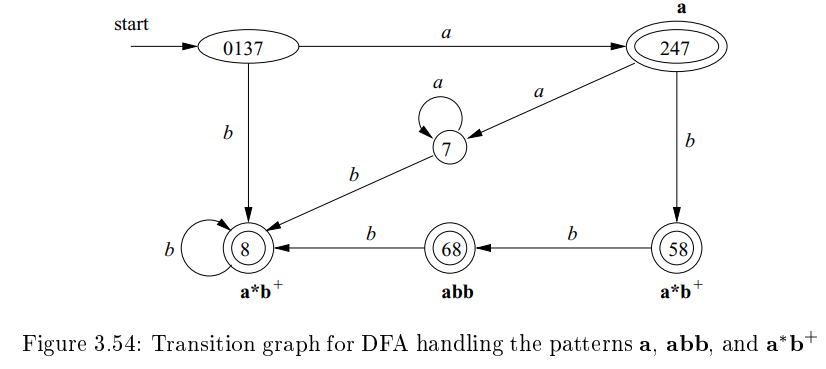
- NFA->DFA로 바꾸는 과정을 보자.
- Algorithm 3.20의 subset construction을 사용한다고 했을 때,
- 각 DFA 상태에 하나 이상의 accepting NFA state가 존재한다면, 그 중 첫 번째 pattern을 찾아서 해당하는 DFA state에 적는다.
- DFA에서도 NFA와 유사한 방식으로 적용한다.
next state가 없을 때 까지 진행 (정확히는, next state는 , , 즉 NFA states들의 공집합) 한다.
그 때, 다시 방문했던 순서를 거꾸로 가서 처음으로 accepting DFA state를 찾으면 그 pattern을 선택한다.
Implementing the Lookahead Operator
- Section 3.5.4에서 Lex lookahead operator / 의 필요성에 대해서 알아보았다.
- 예를 들어 pattern 의 경우, regular expression은 라서 가 제대로 있는지 다 확인해야 하지만, 실제 lexeme은 만 선택해야 하므로 이 경우에는 /가 필요하다.
- NFA에서 pattern을 탐색할 때, /는 으로 해석해서 실제로 / 를 input에서 찾지 않도록 해야 한다.
- 만약 NFA가 prefix 가 이 regular expression을 인식했다고 생각했을 때, lexeme의 끝 부분은 NFA가 accepting state에 들어갔을 때가 아닌, 다음 상태에 해당한다.
- 는 /에 대해 -transition을 가지고 있다.
- NFA의 start state부터 state 까지 를 spells out 하는 경로가 존재한다.
- state 부터 accepting state까지 를 spells out 하는 경로가 존재한다.
- condition 1-3까지를 모두 만족시키는 어떠한 에 대해서 가 가장 길다.
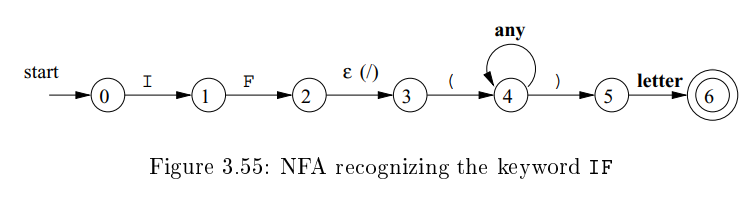
- 만약 NFA에 imaginary / 에 대한 -transition state가 하나만 존재한다면 end of the lexeme은 마지막으로 이 state에 방문한 시점이 된다. (아래 예시처럼)
- 만약 imaginary / 에 대한 -transition state가 하나보다 많다면, 올바른 상태 를 찾기가 어려워진다.


공부 내용 저장소