Basic Hardware
프로세스로 하여금 자신의 정해진 메모리 영역에만 접근하도록 해야 한다.
- base register : smallest legal physical memory address
- limit register : size of the range
만약 위 두 개의 레지스터로 제한된 메모리 영역 이외에 접근하게 된다면, OS에 trap을 발생시켜 fatal error로 처리하게 된다.
두 레지스터의 값을 바꾸는 것은 privileged instruction으로, OS만 바꿀 수 있다.
Address Binding
코드를 어느 시점에 physical memory에 bind 시킬 것인가?
-
Compile time
컴파일 시점에 bind 시킨다.
각 명령어가 가리키는 주소가 실제 physical memory의 값에 해당한다.
concurrent programming에서는 메모리 상에 여러 프로세스가 존재하기 때문에 어느 프로세스가 어느 메모리 영역을 사용할지 다 알 수 있는 아두이노같은 경우( 및 임베디드)를 제외하고는 쓰이지 않는다. -
Load time
compile time에 relocatable code로 컴파일된다.
실제 load time에 base address가 결정되고, 각 명령어가 접근하는 메모리 주소의 값을 업데이트 해준다.
load time에 모든 계산을 다 해주어야 하기 때문에 로딩시간이 매우 오래 걸려 잘 쓰이지 않음. -
Execution time
load time에 미리 base address를 더해주는 방식이 아닌, run time에 base address + offset을 계속 계산해 메모리 주소를 bind한다.
MMU(Memory Management Unit)를 통해 메모리 계산이 이루어져서 overhead가 거의 들지 않는다.
운영체제들이 이 방식을 대부분 사용한다. -
Execution time 계속 이어서..
compile time, load time : logical address == physical address
execution time : logical(virtual) address != physical address- base register (relocation register)에 있는 값이 메모리 계산마다 더해진다.
- user process의 경우 항상 logical address에만 접근할 수 있고, 그 중간 과정을 MMU가 처리해서 실제 physical memory에 매핑해 준다.
Dynamic Loading
로딩되어 있지 않고 디스크에 존재하다가, 프로세스가 필요 시에 메모리에 로딩되는 방법이다.
error handling과 같은 평상시에는 잘 일어나지 않는 코드의 경우 굉장히 유용하다.
Dynamic Linking and Shared Libraries
- Dynamic Linking : Dynamic Loading과 비슷하게, 링크 과정이 execution time에 일어나게 된다.
static libraries vs dynamic linked libraries
- static libraries
- 각 바이너리 파일에 속해 있다.
- 컴파일 시에 링크된다.
- 바이너리 파일의 크기가 크다.
- dynamic linked libraries
- 바이너리 파일과 별개로 존재
- execution time에 링크됨
- 바이너리 파일의 크기가 작다.
- 메모리에 따로 매핑되어 있음 -> 여러 프로세스가 공유 가능 -> "Shared Library"
Contiguous Memory Allocation
하나의 프로세스는 single section of memory에 속하고, 서로 다른 프로세스들의 section들은 연속해서 존재한다.
Memory Protection
-
하나의 프로세스는 다른 프로세스의 메모리 영역 (혹은 OS의 메모리 영역) 을 침범해서는 안 된다.
-
그러기 위한 방법 : 앞서 이야기 했던 relocation register, limit register를 이용 -> logical address < limit 이면 OK, 그렇지 않으면 trap을 보낸다. 그 후에 relocation register값을 더해서 physical memory에 매핑한다.
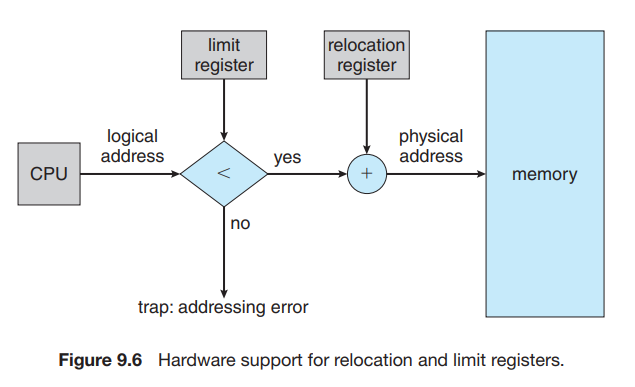
-
CPU 스케줄러에 의해 프로세스가 스케줄링 될 때, context switch의 일환으로 limit register, relocation register 모두 바뀌게 된다.
-
장점 : 필요 없는 메모리는 쫓아내고, 다시 재할당하는 방법을 통해 효율적으로 사용 가능. (어느 위치에든 load가 가능하고, 다른 메모리를 침범하지 않음이 보장 되므로)
Memory Allocation
일단 제일 간단한 방법 : 가변적인 크기의 partition으로 각 프로세스가 사용할 수 있게 한다.
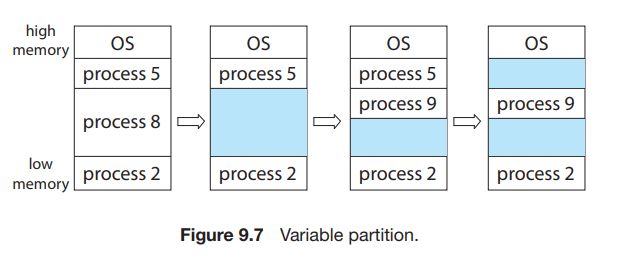
할당 / 해제 / 할당 / 해제 / ...가 반복되면 위의 그림처럼 연속되지 않은 hole이 생기게 된다.
이 hole을 얼마나 효율적으로 할당해 주는가?
- first-fit
처음으로 발견한 충분히 큰 hole을 할당해줌. - best-fit
big hole들 중에 가장 작은 hole을 선택함. 탐색하는 데에 시간이 오래 걸린다. 대신 남은 hole이 제일 작다. - worst-fit
largest hole을 할당해줌. 물론 탐색하는 데에 시간이 오래 걸린다. 남은 hole의 크기가 제일 크지만, 그만큼 이 남은 hole을 할당하는데에 유리하다.
first-fit, best-fit > worst-fit (속도, storage utilization)
일반적으로 first-fit > best-fit이다.
Memory Fragmentation
- external fragmentation
새 프로세스가 메모리에 들어오고자 할 때, hole들의 메모리를 다 더하면 새 프로세스의 필요 메모리보다 많은데도 불구하고 hole들이 불연속적으로 분포해 있어서 할당하지 못하는 상황을 말한다. - internal fragmentation
external fragmentation을 줄이기 위해, 혹은 hole을 관리하는 데에 드는 overhead를 줄이기 위해 실제 프로세스가 필요로 하는 것 보다 더 많은 메모리를 프로세스에게 할당했을 때 그 프로세스에서 사용하지 않고 놀고 있는 메모리를 의미한다.
해결 방법?
- Compaction
메모리를 정렬해서 한쪽으로만 hole을 모아놓는다.
compile time, load time binding의 경우 불가능. 이미 메모리가 정해져 버림.
execution time binding의 경우만 가능.
또한, 해당 메모리를 전부 옮겨야 하므로 비용이 굉장히 크다. - logical address space가 noncontiguous하게 만든다. -> paging 기법.
Paging
Basic Method
- frame : physical memory를 fixed-sized block으로 나눈 것.
- page : logical memory를 fixed-sized block으로 나눈 것.
logical memory와 physical memory는 완전히 다른 메모리 체계를 가지기 때문에 logical memory에서는 바이트의 메모리를 사용가능하다.
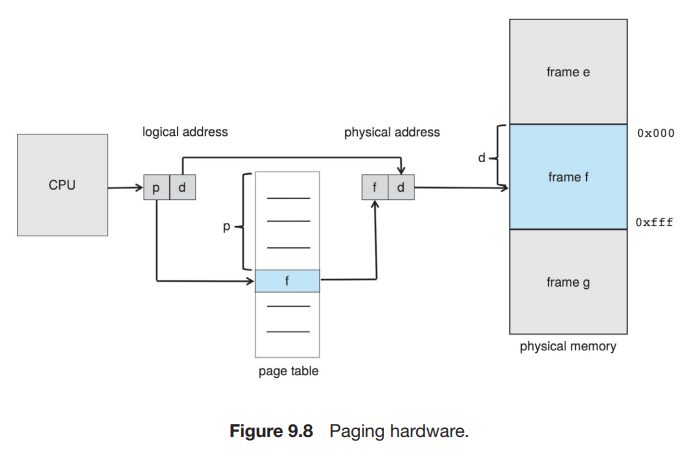
-
CPU에 의해 만들어진 주소
- page number(p)
- page offset(d)
page number는 per-process page table의 index로 쓰인다.
즉, page table의 각 index에는 해당하는 frame의 base address가 적혀있고, 그 base address에다가 page offset을 더한 값이 실제 physical memory 상에서의 값이 된다. -
MMU에서의 동작 순서
- page number p를 구해서 page table의 index로 사용한다.
- page table에서 해당하는 frame number를 구한다.
- page number p를 frame number f로 바꾼다.
-
page size
- 2의 제곱수를 쓴다.
-> logical memory의 크기 = 이라고 하자.
page size = 이라고 하면, 레지스터에서 n바이트 만큼을 page offset으로 쓸 수 있고, 나머지 m - n 바이트 만큼을 page number로 쓸 수 있다.
또한, (이거는 개인적인 생각) 의미적으로는 page number + page offset의 조합이지만, 하나를 통으로 보았을 때는 그냥 logical address의 의미로도 해석할 수 있다.
- 2의 제곱수를 쓴다.
-
일종의 Dynamic relocation이라고도 할 수 있다. (각 page table의 값이 결국 각 page의 relocation register로서의 기능을 한다고도 볼 수 있음.)
-
External Fragmentation이 아예 존재하지 않는다.
-
Frame table : 할당되어 있는 frame, 해제되어 있는 frame, 등등 여러 frame에 대한 정보가 담겨있는 table. 운영체제가 사용한다.
-
위 frame table을 이용하여 운영체제는 user level에서 의미하는 logical address를 physical address로 변환할 수 있다.
-
dispatch 시에 frame table을 만들어 주거나 바꿔주어야 하므로 context-switch 비용이 커진다.
Hardware Support
- page table로의 포인터는 PCB에 저장된다.
- page table은 Main Memory에 존재하며(entry가 너무 많아서 register로 하기 힘듬), page-table base register(PTBR)가 page table을 가리킨다. -> context switch시에 PTBR만 바뀌면 됨 -> context switch overhead 줄어듬.
Translation Look-aside Buffer(TLB)
-
메모리 접근 시 -> PTBR에서 page table base address 얻어옴 -> Main memory에서 page table을 참조하여 frame number 알아옴 -> Main memory에서 frame number를 이용해서 실제 physical memory에 접근함
=> 결국 메모리에 있는 값을 읽어오기 위해서는 두 번 메모리에 접근해야 한다. -> 너무 느려짐. -
해결 방법 : TLB 사용.
TLB : 작지만 빠른 cache memory
TLB의 각 entry : key (tag) & value
32 ~ 1024 entries 까지 가능. (a pipeline step 안에 동작 가능) -> 사실상 no overhead이다. -
동작 원리
- TLB에는 page table의 몇몇 entry들이 들어있다.
- logical address가 CPU에 의해 만들어짐 -> MMU가 TLB에서 해당 page table entry가 있는지 확인
- 있으면? 바로 frame number 값 가져옴. -> 바로 physical memory에 접근.
- 없으면? (TLB miss) 앞에서 언급한 TLB가 없을때와 동일하게 작동, 그리고 TLB에 해당 page table과 frame number를 추가한다.
-
만약 TLB에 내용을 추가하려는데 꽉 차 있다?
- Least Recently Used(LRU), RR, random ... 등 다양한 기법이 있음.
- TLB에는 wired down이라는 기능이 있는데, 해당 entry는 바뀌지 않게 할 수 있다. 예를 들면 핵심 커널 코드가 존재하는 부분이라던지 이런 쪽에 사용 가능.
-
TLB에는 address-space identifier (ASID)가 있는 경우도 있음.
- 각 entry마다 ASID를 쓸 수 있게 해서 각 프로세스가 TLB를 search할 때에 ASID값이 일치할 경우에만 entry 값을 쓰게 함.
- 장점
- memory protection
- 다양한 프로세스가 동시에 TLB를 사용할 수 있다. (원래는 context-switch 마다 TLB를 flush 해 주어 잘못된 access를 막아야 했었다. -> high-overhead)
-
hit ratio
TLB hit을 할 확률.
memory access time의 기댓값
대충 이런 식으로 계산한다.
Protection
read, write, execute 권한을 frame마다 부여할 수 있다.
page table에 valid-invalid bit을 추가할 수 있다.
- valid
해당 page는 프로세스의 logical address space에 속하고, legal page이다. - invalid
프로세스의 logical address space에 속하지 않는다.
예) logical space는 14비트만 사용 (0 ~ 16383)
하지만 프로세스는 실제로 0 ~ 12287만 사용
logical address register도 마찬가지로 14비트짜리를 사용할 것이므로 분명히 나머지 영역에 속하는 메모리에 해당하는 entry도 존재할 것임.
-> 나머지 12288 ~ 16383은 invalid page로 구분해야 한다.
logical address space를 모두 사용하는 프로세스는 거의 없기 때문에, 대부분의 entry들은 메모리 낭비가 된다. -> page-table length register(PTLR)로 page table의 길이를 나타내는 경우도 있다.
Shared Pages
- reentrant code : non-self-modifying code; 실행 도중에 절대로 바뀌지 않는다. -> shared memory로 쓰일 수 있다.
- 페이징 기법은 shared memory 구현에도 굉장히 적합하다. 그냥 같은 physical memory 영역을 서로 다른 page table entry에 놓기만 하면 됨.
Structure of the Page Table
Hierarchical Paging
현대의 컴퓨터 시스템은 32 / 64비트로 구성되어 있음.
만약 32비트, page size = 4KB (B) 라면, entry table은 개의 entry를 가진다. -> 항상 main memory에 load 시켜놓기에는 너무 큼.
-
해결 방법
page table들의 page table을 만들어서 관리한다.
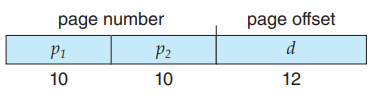

"forward-mapped" page table. 이라고도 불림.
-
단점
page table을 여러 개 거쳐야 하므로, memory access 횟수가 많아짐 -> 결국 너무 느려지게 된다. -
개인적인 생각
어차피 page table을 여러 계층으로 나눈다고 해도, 결국 모든 entry는 존재해야 하는 것이 아닐까? 라고 생각함.
-> 필요 없는 logical memory 영역에 대해서는 outer page table에서 index와 invalid bit만 주어지면 해당 inner page table은 존재할 필요가 없으니까 이쪽에서 메모리 절약이 일어난다고 생각해도 될 것 같은데..? 확실하지는 않음.
근데 어차피 그러면 앞에서 언급했던 page table은 필요한 만큼만 할당하고, 크기를 따로 저장하는 방법을 사용하는 것과 별반 다를 바가 없는데, 이는 어떻게 되는거임? 몰?루
참고 자료: https://pages.cs.wisc.edu/~remzi/OSTEP/vm-smalltables.pdf
Hashed Page Tables
-
virtual page number를 hash value로 하여 hashed page table을 구성한다.
-
충돌을 방지하기 위해 각 entry는 linked list로 구성한다.
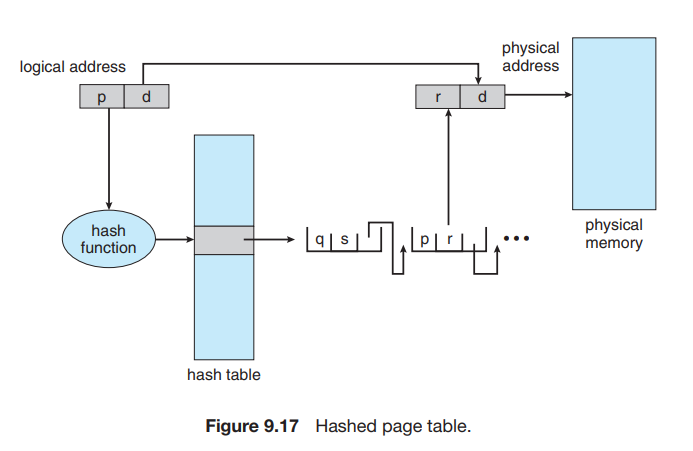
-
clustered page tables?
hash table의 하나의 entry가 여러 pages를 가리킨다. -> 자세히는 모르겠음.
장점
- 메모리 절약 : 사용중인 page에 대한 정보만 기입하면 된다. (ex: 극단적인 케이스 : 10개의 page만 사용해도 기존의 방법은 개의 entry가 있었어야 했지만, hash table의 경우 10개의 hash table entry만 만들어서 필요한 page만 사용하게 하여 메모리를 아낄 수 있음)
Inverted Page Tables
기존의 page table은 프로세스의 page 하나 당 entry가 하나 존재했지만, inverted page table의 경우에는 physical memory의 frame 하나 당 하나의 entry가 존재한다. (어차피 실제로 사용되는 것은 physical memory니까)
또한, 각 entry에는 해당 프로세스의 pid값(ASID), 매핑된 그 프로세스의 page가 저장되어 있다.
그러므로, system에 하나의 page table만 있으면 된다.

- 단점
- 탐색은 virtual memory 기준으로 이루어지므로 결국 physical memory 기준으로 정렬된 inverted page table은 선형탐색을 할 수 밖에 없다. -> 오래 걸림.
hash table과 결합해서 동작하면 선형탐색을 피할 수 있다. -> 하지만 hash table에 추가적으로 접근해야함 -> 메모리 접근이 2번.. - Shared memory 구현..
기존의 방식은 process마다 page table이 존재했기 때문에 physical memory에 다대일로 매핑이 가능했다. 하지만 inverted page table의 경우 일대일 매핑밖에 안 되므로 shared memory는 불가능함.
- 탐색은 virtual memory 기준으로 이루어지므로 결국 physical memory 기준으로 정렬된 inverted page table은 선형탐색을 할 수 밖에 없다. -> 오래 걸림.
Swapping
backing store : fast secondary storage
Standard Swapping
process 전체를 main memory에서 backing store로, 또 그 반대 방향으로 옮기는 것을 의미한다.
idle process의 경우 swapped되기 딱 좋은 프로세스이다.
전체 메모리보다 더 큰 메모리 영역이 필요할 지라도 사용하지 않는 프로세스를 swapping을 통해 내보냄으로써 degree of multiprogramming(?)을 높일 수 있다.
Swapping with Paging
앞선 standard swapping과는 다르게, page 단위로 swapping을 수행해서 전체 프로세스를 왔다갔다 해야하는 overhead는 줄일 수 있다.
장점은 그대로 유지 가능.
Segmentation 기법
사실 정리하기가 귀찮다. 밑에 참고 자료로 들어가 보셈.
참고 자료
- https://pages.cs.wisc.edu/~remzi/OSTEP/vm-smalltables.pdf
- Operating System Concepts - 10th edition
- https://velog.io/@chappi/OS%EB%8A%94-%ED%95%A0%EA%BB%80%EB%8D%B0-%ED%95%B5%EC%8B%AC%EB%A7%8C-%ED%95%A9%EB%8B%88%EB%8B%A4.-15%ED%8E%B8-%EA%B0%80%EC%83%81-%EB%A9%94%EB%AA%A8%EB%A6%AC-%EC%84%B8%EA%B7%B8%EB%A8%BC%ED%85%8C%EC%9D%B4%EC%85%98-%EC%84%B8%EA%B7%B8%EB%A8%BC%ED%85%8C%EC%9D%B4%EC%85%98-%ED%8E%98%EC%9D%B4%EC%A7%95-%ED%98%BC%EC%9A%A9-%EA%B8%B0%EB%B2%95
