Operating system
1.[Operating systems] Computer-System Architecture
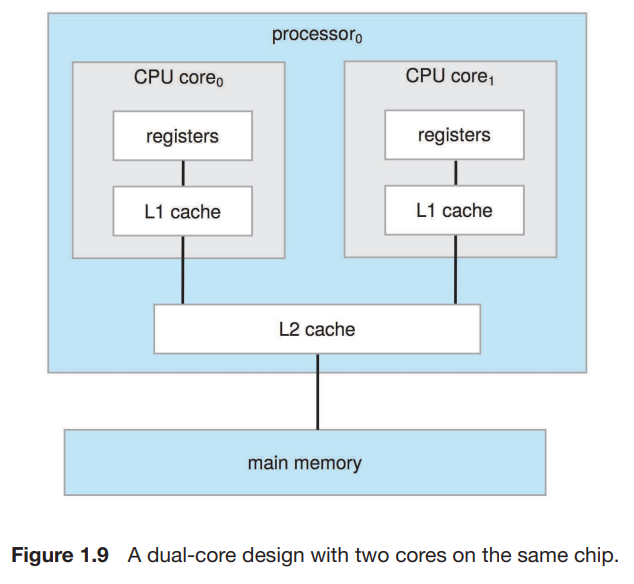
one main CPU with its core : capable of executing a general-purpose instruction set.device-specific processors(special-purpose processors) : run a lim
2.[Operating Systems] Operating-System Operations
처음 컴퓨터가 부팅될 때initial(bootstrap) program이 먼저 실행된다.프로그램이 firmware 안의 computer hardware에 존재함.bootstrap program이 operating-system kernel을 memory에 올림으로써 Op
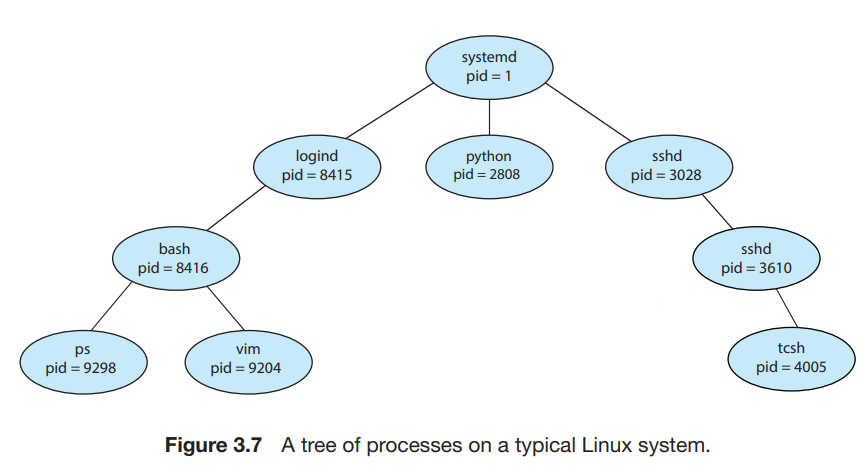
3.[Operating Systems] Resource Management
process는 resource들을 필요로 한다. 뿐만 아니라 다양한 초기화 데이터들도 필요로 한다.program : disk 안에 담긴 파일같은 passive entity 이다.process : active entity.program counter : 다음에 실행할
4.[Operating Systems] Kernel Data Structures
array : 각 원소들에 직접적으로 접근할 수 있는 간단한 자료구조.사이즈가 바뀔 수 있는 경우, 데이터를 삭제해야 하는 경우 문제가 생긴다.list : array와 달리 순서대로 접근할 수 있다. 가장 간단한게 linked list인데, 종류는 아래와 같다 : si
5.[Operating Systems] Process (1)
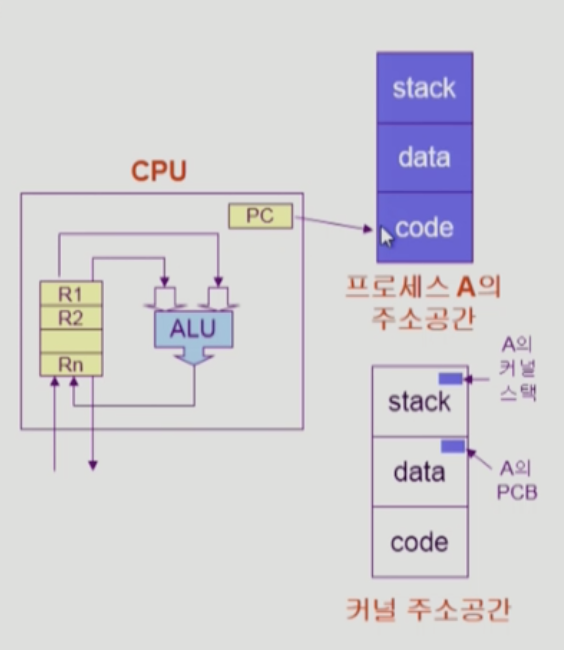
program in executionCPU 수행 상태를 나타내는 하드웨어 문맥Program Counter : 다음 실행될 명령을 가리키는 register. (instruction pointer, IP라고도 함.) 각종 register프로세스의 주소 공간code, dat
6.[Operating Systems] System call

System call은 hardware를 직접적으로 접근해야 하는 low-level task들의 경우 함수 형태로 C나 C++에서 사용할 수 있는 interface를 제공한다. Application developers는 application programming in
7.[Operating System] Process (2)
CPU Scheduling CPU scheduler : ready queue에 있는 process 중에서 하나를 선택해서 CPU core를 할당해 준다. I/O-bound process의 경우 I/O 요청 전에 아주 잠깐동안만 CPU를 사용하게 된다. CPU
8.[Operating System] Process (3)
Interprocess Communication independent process :system에서 실행중인 어떠한 process와도 데이터를 공유하지 않는 프로세스 cooperating process : 시스템에서 실행되는 다른 프로세스에게 영향을 끼치거나 받을 수
9.Memory Mapping
파일을 virtual memory에 매핑해서 프로세스가 접근할 수 있게 한다.필요한 파일의 내용을 메모리에 매핑함으로써 메모리에 직접 접근하는 방식을 통해 빠르게 내용을 읽고 쓸 수 있다. (기존의 방법은 read(), write() system call을 계속해서 사
10.[Operating System] Threads (1)
Thread? Basic information CPU 사용의 기본 단위. 스레드 ID, program counter, register set, stack으로 이루어져 있다. 같은 프로세스 내의 다른 스레드들과 code section, data section, and
11.[Operating System] Thread (2)
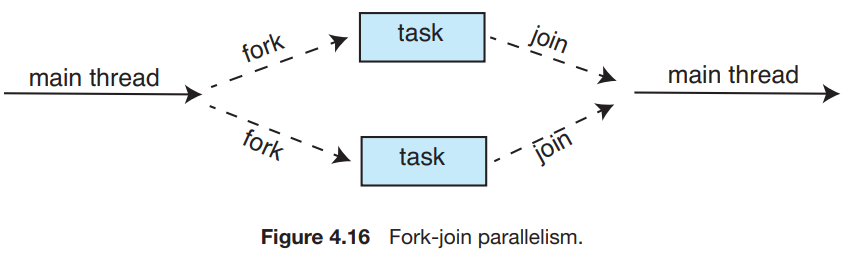
Thread Libraries thread library가 thread를 만들고 관리하는 API를 제공해 준다. thread를 구현하는 두 가지 방법 kernel의 도움 없이 전적으로 user space에서만 library를 제공 : library 내부 함수들을 사
12.[Operating System] Thread Local Storage (TLS)
메모리 할당은 process 단위로 이루어지기 때문에 thread는 동일한 메모리 주소를 공유하게 된다. -> Data 영역도 공유 -> 전역변수를 모든 스레드가 공유.Process와 마찬가지로 스레드의 경우에도 각자의 고유한 전역변수가 필요한 경우가 존재한다.Thre
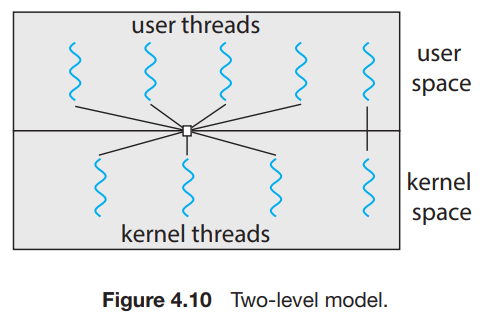
13.[Operating System] Thread (3)
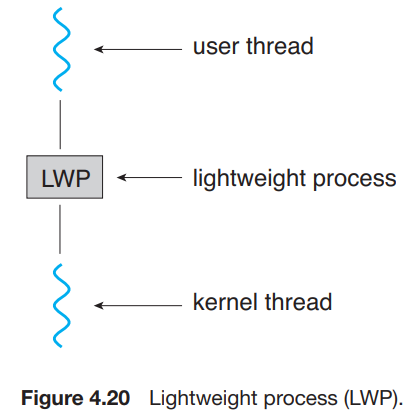
Scheduler Activations many-to-many와 two-level models에서 communication between kernel and the thread library는 어떻게 이루어지는가? many-to-many와 two-level models
14.[Operating System] CPU Scheduling (1)
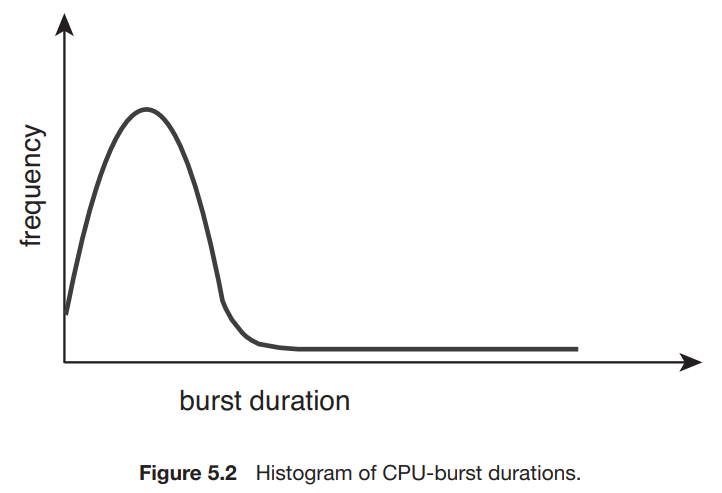
multiprogramming의 목표 : 항상 어떠한 프로세스가 동작해서 CPU utilization을 최대화시킨다.그래서 I/O 같은 일을 process가 요청했을 때, 가만히 기다리지 않고 그 process를 대기 상태로 냅두고 CPU를 다른 프로세스에 할당시킨다.
15.[Operating System] CPU Scheduling (2)
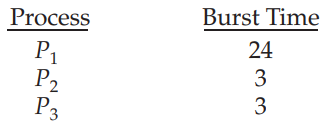
FCFS 스케줄링과 비슷하지만 preemption이 추가되었다.A small unit of time, called a time quantum or time slice, is defined.time quantum : 일반적으로 10 ~ 100msready queue는 c
16.[Operating System] CPU Scheduling (3)
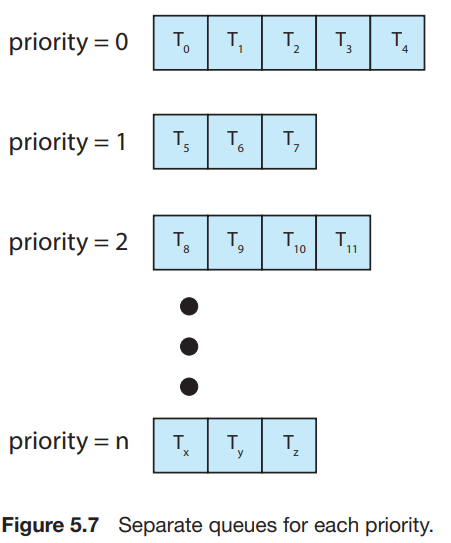
highest-priority access를 위해서는 O(n) search를 필요로 한다.multilevel queue각각의 priority에 대해서 큐를 만들게 되면 priority scheduling이 highest-priority queue에 있는 프로세스만 스케
17.[Operating System] CPU Scheduling (4)
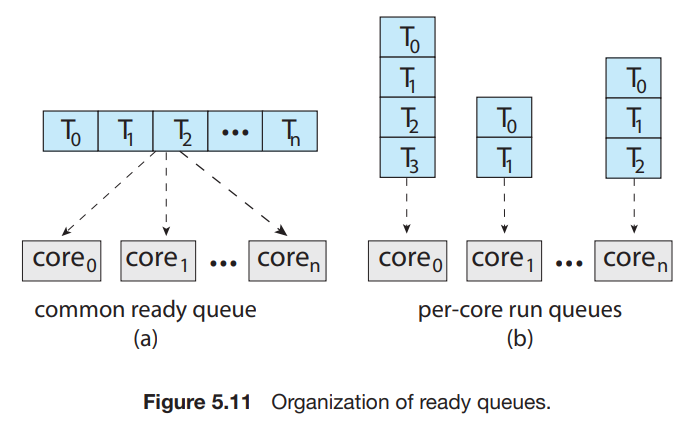
process-contention scope(PCS)user-level thread가 scheduled될 때, 한 process 내부에서 CPU 점유를 위한 경쟁이 일어나기 때문에, process-contention scope라고 부른다.특히나 user-level th
18.[Operating System] CPU Scheduling (5)
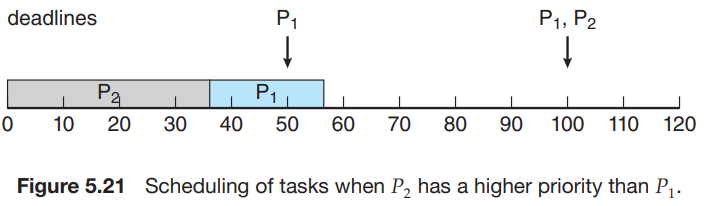
Real-Time CPU Scheduling Soft real-time systems : critical real-time process는 noncritical process에 비해 더 높은 preference만 가지게 될 뿐 언제 시작할지는 보장되지 않는다. Hard
19.[Operating System] CPU Scheduling (6)

Operating-System Examples Example: Linux Scheduling 커널 버전 2.5 이전 : traditional UNIX scheduling algorithm SMP시스템 지원이 되지 않아서 multiple processor의 경우 제대로
20.[Operating System] Synchronization Tools - Background

앞선 예시로 원형 큐가 있었는데, BUFFER_SIZE - 1개만 담을 수 있었다. 이 문제를 해결하기 위해 count라는 변수를 사용해서 해결할 수 있다.producer processconsumer process각각은 괜찮아 보이지만, 동시에 실행되었을 때 문제가 발
21.[Operating System] Peterson's Solution

Peterson's Solution Peterson's solution : software-based solution to the critical-section problem. 두 프로세스가 critical section과 remainder section을 왔다갔다하는
22.[Operating System] Synchronization Tools (1)

Hardware Support for Synchronization Memory Barriers Memory model : 컴퓨터 아키텍쳐가 application program에게 메모리를 어떻게 줄 지에 대한 방식. 두 가지 유형이 있다. Strongly ordere
23.[Operating System] Synchronization Tools (2)
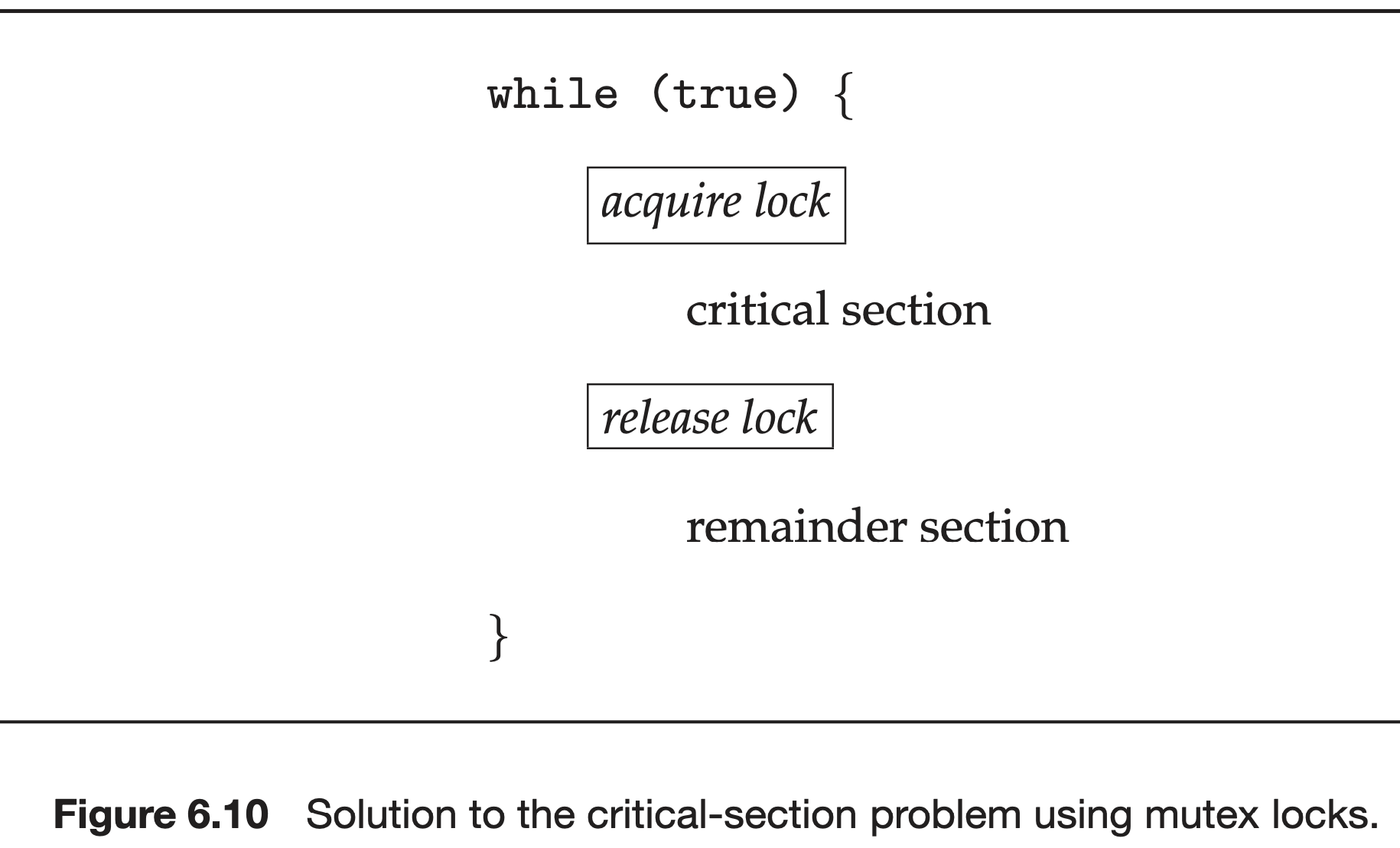
hardware수준에서 구현하는 것 -> application 개발자들에게 너무 어려움. -> operating-system designers build higher-level software tools to solve the critical-section proble
24.[Operating System] Monitors

Semaphore, Mutex는 물론 Synchronization 문제를 해결하는 데에 많은 도움이 되는 도구들이지만, 실제로 프로그래밍 시에 실수를 굉장히 자주하게 되는 부분이기도 하다.간단한 high-level language construct를 이용하는 것이 좋다
25.[Operating System] Liveness

Liveness?프로세스들이 그들의 execution life cycle동안 progress가 있도록 보장하는, 시스템이 가져야 할 특징들을 말한다.프로세스가 무한정 기다리는 상황은 "liveness failure"라고 부른다.busy wait 또한 liveness f
26.[Operating System] Synchronization Examples
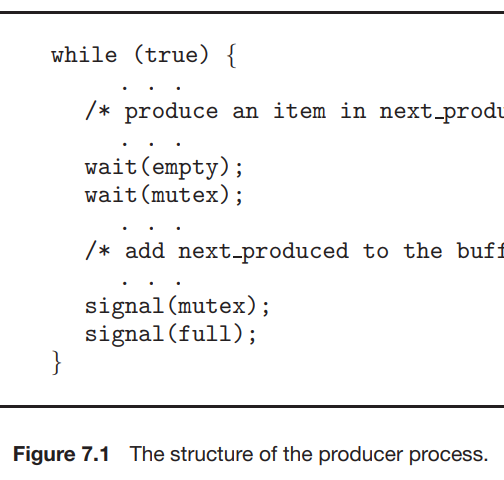
producer and consumer processes가 공유하는 자료 구조들 : \- int n; \- semaphore mutex = 1 : Buffer에 하나의 프로세스만 접근 가능 \- semaphore empty = n, \- semapho
27.[OS] Slab Allocation
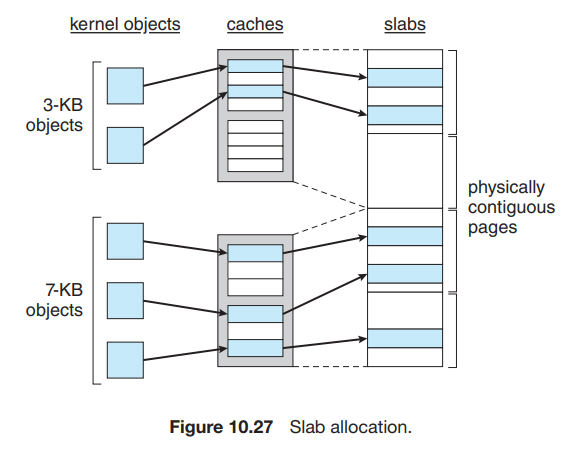
unique kernel data structure마다 cache가 존재cache가 나타내는 자료구조의 instance로 구성되어 있다.할당 원리cache가 만들어짐 -> free 상태인 객체들이 cache에 할당됨. (cache는 slab로 구성되므로 slab의 크기
28.[OS] Other Considerations

pure demand paging에서는 프로세스의 시작 때 initial locality를 위해 상당한 수의 page fault가 이루어진다.prepaging : initial paging에서 앞선 문제를 해결하기 위해 매 page fault마다 하나의 page를 할당
29.[OS] Deadlock

Deadlock? 정의? every process in a set of processes is waiting for an event that can be caused only by another process in the set. Livelock? Deadlock과
30.[OS] Main Memory
Basic Hardware 프로세스로 하여금 자신의 정해진 메모리 영역에만 접근하도록 해야 한다. base register : smallest legal physical memory address limit register : size of the range 만약 위
31.[OS] Virtual Memory
Virtual Memory? 메모리를 가상화하는 기법. 사용자 입장에서는 주소 0x0 ~ 0xFFFFF... 까지의 엄청 큰 공간으로 인식한다. -> 프로그래밍 상에서의 제약 조건이 사라짐. 필요한 부분만 Demand Paging 프로세스의 모든 메모리를 physic