Prepaging
- pure demand paging에서는 프로세스의 시작 때 initial locality를 위해 상당한 수의 page fault가 이루어진다.
- prepaging : initial paging에서 앞선 문제를 해결하기 위해 매 page fault마다 하나의 page를 할당하는 것 대신, 미리 여러 page를 할당하는 것이다.
- working set model에서, working set에 맞는 page수를 프로세스마다 할당해 주었다. 그런데 만약 할당해 줄 frame이 부족해질 경우, 특정 프로세스가 suspend하게 된다. 이 프로세스의 working set을 기억해 두었다가, 다음에 다시 resume될 때 프로세스 시작 전에 미리 메모리를 할당하는 것이다.
- 효율? -> prepaging을 했을 때의 cost와 page fault를 service하는 데에 필요한 cost를 비교해 보면 된다. (특히 prepaging이 되었지만 실제로 사용되지 않는 경우가 해당)
- s개의 page가 prepaged 되었고, 실제 s중 fraction의 page가 실제로 사용되었다고 가정. (0 1)
- 여기서 개의 saved page fault의 비용과 개의 사용되지 않은 prepaging의 비용을 비교해 보면 된다.
- 가 0에 가까우면 prepaging을 안 하는 것이, 가 1에 가까우면 prepaging을 하는 것이 유리하다.
Page size
- page table의 사이즈 : page가 클 때가 page table이 더 작아진다.
- average internal fragmentation : page가 작을 때가 더 작아진다.
- HDD의 I/O : seek, latency, transfer times에 영향을 받음.
- transfer times : 당연히 page크기가 클 수록 더 길어진다.
- seek, latency time >> transfer time.
- 같은 사이즈만큼을 I/O 했을 때, 큰 페이지의 경우 작은 페이지보다 seek, latency가 적게 일어남 -> page가 클 수록 시간이 적게 걸린다.
- 대신, page가 작을 수록 필요한 부분만 가져올 때 더 유리함. (쓸모 없는 부분까지 가져올 필요가 없다.) -> I/O가 적게 일어나고 할당된 메모리도 줄어든다. -> but page가 작은만큼 page fault가 음청나게 많이 발생할 것임.
- 최신 동향 : 더 큰 page size로 가고 있다.
TLB Reach
- TLB hit ratio를 높이는 방법 : TLB entry를 많이 만들면 된다! -> 비싸고 파워가 많이 든다..
- TLB reach : TLB로부터 접근 가능한 메모리의 양. (page size * entry 수)
- 이론적으로 working set은 TLB에 존재한다.
- TLB reach를 늘리는 방법 : 그냥 entry를 두배로 늘린다. (memory intensive application의 경우 별 도움이 안된다.)
- 또 다른 방법 : 그냥 page 사이즈를 늘린다.
- 단점 : 당연히 fragmentation이 늘어나겠지?
- 개선방안 : 여러 page size를 지원한다.
Inverted Page Tables
- 방법 자체는 메모리를 줄이는 데 굉장히 많은 도움을 준다.
- 하지만 만약 referenced page가 memory에 있지 않을 때 어떻게 됨?? (뇌피셜 : invalid range인지 그냥 page가 할당되지 않은 것인지 구별이 불가능..) -> 각 프로세스 별로 이에 대한 정보를 담은 external page table이 필요하다.
- 그러면 결국 똑같은거 아님? inverted page table 왜씀?
-> 어차피 page fault가 일어났을 때에만 external page table을 쓰니까 얘를 항상 메모리에 놓지 말고 일반 reference처럼 paging의 대상으로 쓰자.
-> 단점 : page fault가 발생해서 external page table을 참고하려고 했더니 얘도 메모리에 있지 않아서 page fault가 발생 가능.. -> cafeful handling이 필요.
Program Structure
- 일반적으로 paging은 유저입장에서 모르게끔 작동한다.
- 하지만 user나 compiler가 알면 더 좋은 경우가 존재함.
- 예시)

- 가정 : page의 사이즈 = 128 words, 이 프로세스에 할당된 page 수 = 128 이하, data 2차원 배열이 사실은 row별로 하나의 page로 묶여있다고 생각하자.
- 그러면 위의 코드는 각 page 별로 하나씩의 word를 번갈아가면서 수정함.
- 결국 총 128 * 128 = 16384 번의 page fault가 발생.

- 반면에 코드를 위와 같이 바꾸면, page fault는 128번밖에 발생하지 않게 된다.
- 좋은 예시
- locality를 증가시키는 프로그래밍 구조와 자료 구조를 사용하면 좋다.
- ex)
- stack : 항상 top에서만 access가 이루어짐 -> good locality.
- hash table : scatter references -> bad locality.
- search speed, total number of memory references, total number of pages touched 등 여러 요소가 있다.
- compiler, loader -> clean pages가 유리함 -> 자주 불려지는 명령어들끼리 하나의 page에 할당시킴 -> 물론 page가 클수록 유리하다.
I/O Interlock and Page Locking
- page를 memory에 lock해야하는 경우도 있다.
- ex) USB storage device controller는 buffer의 memory address, 전송할 byte를 전달받고 I/O를 수행함. 프로세스가 USB에 I/O를 요청했을 경우, CPU 스케줄링에 의해 다른 프로세스가 할당 될 것이다. 새 프로세스가 기존에 존재하던 프로세스의 buffer가 포함된 page를 replace 해버린다면, I/O는 엉뚱한 주소에 이루어질 것이다.
- 해결 방법?
- I/O를 user memory에 행하지 않는다.(never) 대신, system memory와 user memory간에 데이터를 복사한다. I/O장치는 system memory와 I/O device간에만 이루어진다.
- ex) tape에 block을 쓰기 위해 system memory에 우선 복사를 하고 그 후 I/O장치에 쓴다. -> overhead 굉장하다!
- pages를 메모리에 고정시킨다. -> 매 frame 마다 lock bit이 존재한다. -> lock bit이 설정되면, 그 frame은 replacement에 선택될 수 없다.
- ex) I/O쓰기 전에 해당 page를 lock 시키고, I/O가 끝나면 page를 unlock시킨다.
- I/O를 user memory에 행하지 않는다.(never) 대신, system memory와 user memory간에 데이터를 복사한다. I/O장치는 system memory와 I/O device간에만 이루어진다.
- Lock bit가 사용되는 경우?
- operating-system kernel : 대부분이 locked into memory.
- database : 자기가 제일 효율적이다 -> pinned 상태를 시스템 콜을 통해 요청.
- normal page replacement : low-priority process의 경우, 다음과 같은 상황 발생 가능.
- page fault 발생 -> 다른 frame을 갖고옴 -> ready queue에 들어가서 기다림 -> ... -> 애초에 low-priority니까 오래 기다림 -> ... -> 그 다음에 high-priority process가 page fault 발생시킴 -> replacement를 위한 page를 찾는데 이전의 low-priority process의 page를 너무 선택하고 싶어진다.(안 쓰인지 오래됨 + clean상태) -> 빼앗아버림 -> 도대체 low-priority process는 언제 실행함..? ㅠㅠ
- 그래서 새로 가져온 page의 경우 lock bit을 이용해서 적어도 한 번 사용될 때 까지 보장해준다.
- 문제점 : 만약에 오류가 발생해서 lock bit이 꺼지지 않으면 그냥 해당 페이지는 못쓰게 된다.
Operating System Examples
Linux
- demand paging 이용.
- LRU-approximation clock algorithm과 유사한 global page-replacement policy 사용.
- Linux에서는 두 종류의 page list를 사용한다.
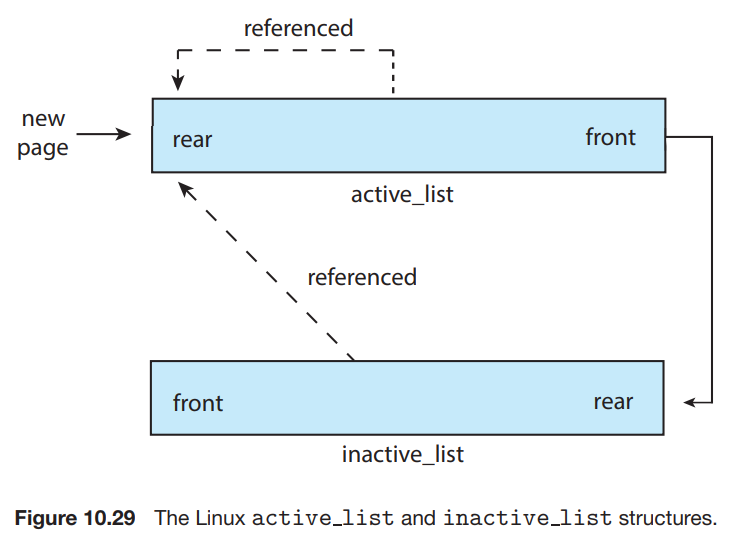
- active_list
- 사용중인 pages로 구성된다.
- inactive_list
- 최근에 한동안 사용되지 않았고 reclaim될 수 있는 pages.
- 각 page는 accessed bit이 존재 -> reference될 때마다 bit가 set된다.
- active_list에 있는 page가 reference되면, 그 page는 active_list의 rear로 옮겨진다. 처음 allocate되는 page의 경우도 마찬가지.
- 주기적으로 active_list에 있는 accessed bit은 reset된다.
- 시간이 지나면, active_list의 제일 앞에는 사용한 지 가장 오래된 page가 존재하게 된다.
- 그 page는 inactive_list의 rear로 갈 수 있다.
- 물론 inactive_list의 page가 referenced되면 다시 active_list로 간다.
- 만약 active_list가 inactive_list보다 훨씬 커지면, active_list의 제일 앞은 inactive_list로 움직이게 되어 그들은 reclaim될 수 있다.
- Linux kernel은 page-out daemon process인 'kswapd'을 가지고 있어서 주기적으로 system의 free memory를 체크한다.
- free memory가 threshold 아래로 떨어짐 -> kswapd가 inactive_list를 스캔하면서 free list에 page를 추가시킨다.
- active_list
- 나머지는 귀찮...
- 어쨌든 이걸로 Virtual Memory는 끝났다.
참고 자료
- Abraham Silberschatz - Operating System Concepts, 10th edition

공부 내용 저장소