Basic Concepts
- multiprogramming의 목표 : 항상 어떠한 프로세스가 동작해서 CPU utilization을 최대화시킨다.
- 그래서 I/O 같은 일을 process가 요청했을 때, 가만히 기다리지 않고 그 process를 대기 상태로 냅두고 CPU를 다른 프로세스에 할당시킨다.
- 다중 코어 시스템의 경우, 이 과정이 모든 코어에 대해 확장된다.
CPU-I/O Burst Cycle
-
process의 execution은 CPU execution과 I/O wait의 사이클로 이루어진다.
-
Process execution은 CPU burst로 시작하고, 그 이후에는 I/O burst, CPU burst, ...의 과정이 반복된다. 마지막으로 system이 execution terminate을 요청하면 final CPU burst가 끝난다.
-
CPU burst의 지속시간은 케바케이지만, frequency curve는 아래 그림을 따라가는 경향이 있다.
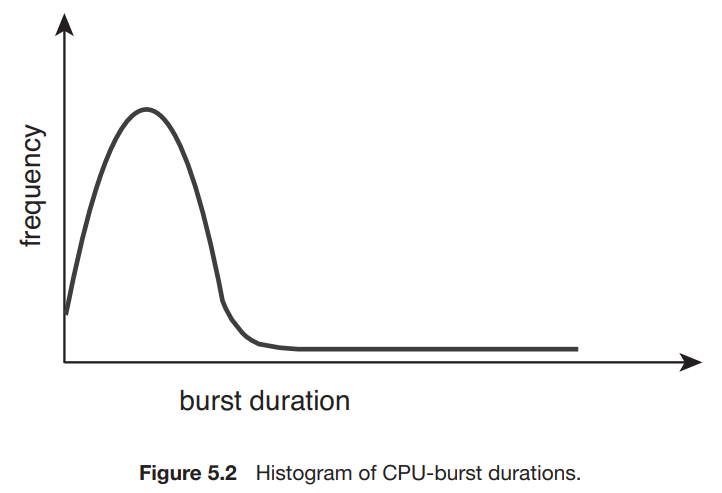
-
즉, 긴 CPU burst는 적고, 짧은 CPU burst는 많은 것을 알 수 있다.
-
예를 들어, I/O-bound program은 많은 short CPU burst를 가지고, CPU-bound program은 적은 long CPU burst를 가질 것이다.
CPU Scheduler
- CPU가 휴식상태가 되면, 운영체제는 ready queue에서 프로세스를 하나 선택해서 실행되게 한다. -> CPU scheduler에 의해 이루어짐.
- 항상 ready queue가 FIFO queue인 것은 아니다.
- queue는 프로세스들의 PCB를 통해 관리한다.
Preemptive and Nonpreemptive Scheduling
- CPU-스케줄링 선택은 4가지 환경에서 이루어질 수 있다.
- running state -> waiting state로 옮겨갈 때 (I/O request나 wait() 호출했을 경우)
- running state -> ready state로 옮겨갈 때 (interrupt 발생)
- waiting state -> ready state로 옮겨갈 때 (I/O 종료)
- process가 terminate 할 때
- 1, 4의 경우 : nonpreemptive or cooperative
- 2, 3의 경우 : preemptive
- nonpreemptive scheduling : CPU가 process에게 할당되었을 때, process가 terminate 혹은 waiting state로 switch 되기 전까지 CPU를 가지고 있는다.
- 모든 현대 운영체제들은 preemptive scheduling algorithm을 사용한다.
- 단점 : preemptive scheduling은 여러 프로세스 간에 데이터 공유가 이루어질 때 race condition을 만들 수 있다. 예시 : 두 프로세스가 한 데이터를 공유할 때, 1번 프로세스가 데이터를 바꾸는 과정에서 중간에 2번 프로세스가 실행되서 바뀌는 상태의 data를 읽게 된다. -> 나중에 다룸.
- Preemption : 운영체제 커널의 디자인에도 영향을 끼친다.
- system call의 과정 동안, kernel은 중요한 커널 데이터를 수정중인 경우가 있는데, 만약 이 도중에 process가 preempted 되어서 수정중인 데이터에 접근을 하는 경우가 발생하면? Chaos ensues.
- 운영체제 커널은 nonpreemptive 또는 preemptive 두 가지로 만들어질 수 있다.
- nonpreemptive kernel : system call이 끝나거나 I/O로 인해 block되기 전까지 기다렸다가 context switch를 실행한다. -> 커널 구조가 간단하다. 하지만 단점도 존재하는데, real-time computing에서는 주어진 시간 안에 task를 완료해야 하는데, 이 경우에는 잘 작동하지 않는다. (poor)
- preemptive kernel : race condition을 막기 위해 mutex lock과 같은 방법이 필요하다. 현대의 대부분의 운영체제가 preemptive kernel이다.
- interrupts는 언제나 일어날 수 있고, kernel에 의해 무시되면 안 된다..? 여기 부분은 아직 잘 모르겠음.
Dispatcher
-
CPU-scheduling function에 포함된 또 다른 요소로 dispatcher가 있다.
-
dispatcher : CPU scheduler로 인해 선택된 프로세스에 CPU의 core를 할당해 주는 module이다. 기능은 다음과 같다 :
- 한 프로세스에서 다른 프로세스로 switch context
- user mode로 switching
- user program을 재개하기 위해서 user program의 적당한 위치로 jump하기
-
dispatcher는 매 context switch마다 실행되므로 가능한 한 빨라야 한다. 한 process를 멈추고 다른 프로세스를 실행시키는 데 까지 걸리는 시간을 dispatch latency라고 부른다.
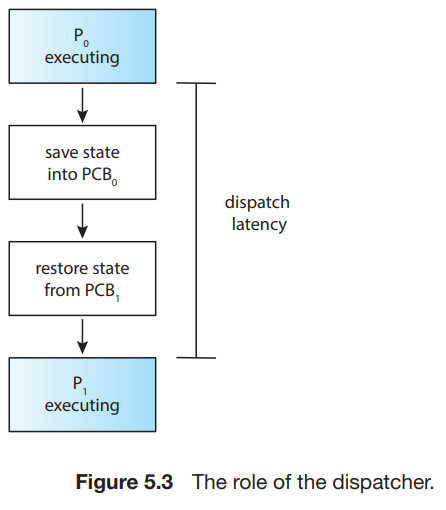
-
리눅스에서는 vmstat 명령어를 통해서 context switch의 수를 확인할 수 있다. cat /proc/{process_num}/status를 통해서도 알 수 있다.
Scheduling Criteria
- Scheduling Criteria
- CPU utilization : CPU는 바쁠수록 좋다. 이론상 CPU utilization은 0 ~ 100퍼센트 가능하지만, 실제로는 40 ~ 90퍼센트정도 된다.
- Throughput : work의 양을 재는 방법은 단위 시간당 complete된 프로세스의 수인 throughput을 통해 잰다. 긴 프로세스의 경우 몇 초동안 하나의 프로세스일 것이고, 짧은 프로세스의 경우 초당 여러 프로세스일 것이다.
- Turnaround time : 특정한 프로세스의 기준에서 보았을 때, 그 프로세스를 실행시키는 데에 얼마나 오래걸리는지가 중요하다. 프로세스의 시작시간부터 끝나는 시간까지의 interval이 turnaround time이다. Turnaround time = waiting in the ready queue + executing on the CPU + doing I/O.
- Waiting time : CPU scheduling algorithm은 process의 실행시간이나 I/O시간에는 영향을 끼치지 않고, ready queue에서의 대기시간에만 영향을 끼친다. waiting time = ready queue에서 기다린 시간들의 총 합이다.
- Response time : Interactive system에서, turnaround time은 가장 중요한 기준이 아닐 수 있다. 이전 작업이 진행되는 도중에 새로운 작업을 해서 빨리 결과를 내야하는 경우가 있다. 그래서 request의 제출로부터 첫 response가 만들어지기까지의 시간이 중요하게 되었고, 이를 response time 이라고 부른다.
- 일반적으로 위 기준들의 평균값을 최적화하고자 하지만, 예를들어 모든 user들이 좋은 서비스를 받게 하기 위해서 다른 기준들 보다 maximum response time을 최소화하는 것을 우선시할 수 있다. (결국 케바케라는 뜻)
Scheduling Algorithms
- single CPU with single-core의 경우에 대해서 살펴볼 것이다.
First-Come, First-Served Scheduling
- 가장 간단한 알고리즘. first-come, first-serve (FCFS)
- 그냥 FIFO queue에 의해 간단히 구현된다.
- 단점 : average waiting time이 꽤 길다. 예시 :
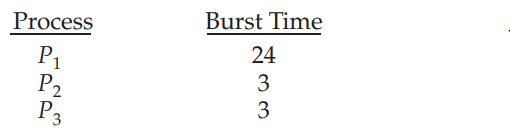
- 의 순서로 오게 되면 아래의 Gantt chart(스케줄을 설명하는 바 차트인데, 각 프로세스의 시작과 끝 시간을 나타낸다.)를 얻게 된다.

- 의 경우 waiting time = 0ms, 의 경우 24ms, 의 경우 27ms이고, 평균 waiting time은 17ms가 된다. 하지만 순서를 으로 바꾼다면 Gantt chart는 아래와 같게 된다.

- 이 경우 average waiting time = 3ms가 된다. 상당한 차이이다. 그러므로 FCFS policy의 평균 waiting time은 일반적으로 최소가 아니며, 프로세스들의 CPU burst time이 달라질수록 평균 waiting time도 달라질 것이다.
- 동적인 상황에서 고려를 해보자. 만약 하나의 CPU-bound process와 여러 I/O-bound processes가 존재한다면, CPU-bound process가 CPU에서 동작을 하는 동안, 나머지 프로세스들이 I/O를 끝내고 ready queue에 있는 상황이 올 수 있다. 이 경우 I/O device는 idle 상태이다. 또한 CPU-bound process가 CPU 사용을 끝내고 I/O device로 움직였을 때, 어차피 나머지 프로세스들은 I/O-bound 이므로 금방 CPU 사용을 끝내고 I/O device로 갈 것이다. 그러면 CPU가 idle 상태가 된다. 이렇게 하나의 큰 프로세스가 CPU를 차지하는 동안 나머지 프로세스들이 대기하게 되는 상황을 convoy(호위) effect라고 한다. -> shorter processes가 더 먼저 가는 것 보다 더 낮은 CPU와 device utilization을 초래할 수 있다. - FCFS scheduling algorithm은 nonpreemptive하다. 그래서 interactive system에서 특히나 좋지 않다.
Shortest-Job-First Scheduling
-
shortest-job-first(SJF) scheduling algorithm : 각 프로세스의 다음 CPU burst와 associate한다.
-
CPU가 available할 때, next CPU burst가 가장 작은 프로세스에게 할당된다. 만약 next CPU burst가 동일하다면 FCFS를 이용하여 처리한다.
-
SJF 스케줄링의 예시

- Gantt chart는 다음과 같다.

- waiting time : -> 3ms, -> 16ms, -> 9ms, -> 0ms
- average waiting time : 7ms
- average waiting time by FCFS : 10.25ms -
확실히 average waiting time을 minimize시킨다. 하지만 실제 CPU scheduling에서는 다음 CPU burst가 얼마나 길지 모르기 때문에 구현할 수 없다.
-
해결 방법? 시도?
-
approximate SJF scheduling : next CPU burst를 이전 CPU burst의 길이들을 이용해서 예측한다. -> 그것을 바탕으로 예측된 가장 적은 CPU burst를 가진 프로세스를 선택하면 된다.
-
예측하는 방법 : 이전 CPU bursts의 측정된 길이의 exponential average를 사용한다.
-
예측 공식
- 이 n번째 CPU burst의 길이라고 하자.(n이 현재 시점이 된다.)
- 이 다음 CPU burst의 예측 값이라고 하자.
- 를 만족하는 에 대해서 이라고 정의하자.
- 값은 가장 최근 information을 포함하고, 은 과거 기록을 저장한다.(이 과거 기록인 이유 : 또한 n - 1번째의 정보들로 이루어졌고, 도 마찬가지로 n - 2번째 정보로 이루어 졌고, 이런식으로 recursive하게 구성되었으므로 자체는 과거의 정보(1 ~ n - 1모두 포함됨)에 해당한다. 반면에 은 현재 시점의 CPU burst 길이에 해당하므로 단순히 현재의 정보에 해당한다.)
- parameter 는 예측에서 사용될 recent and past history 간의 상대적 weight을 조절한다. 예를 들면, 과거의 정보가 더 중요하다고 판단되면 의 값을 낮추면 되고, 현재의 정보가 더 중요하다고 판단되면 의 값을 높이면 된다.
- 의 값은 상수값, 혹은 overall system average 값으로 정의할 수 있다.
-
아래는 = 1/2, = 10인 경우이다.
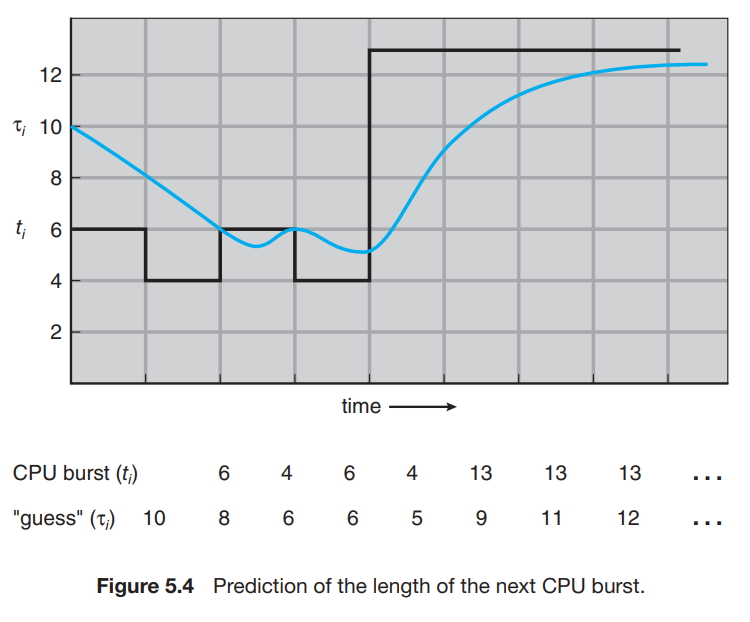
-
모든 들을 전개해서 값을 구할 수 있다.
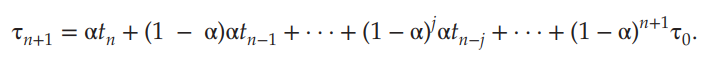
-
당연히 는 1보다 작고, 그러면 결국 (1 - )또한 1보다 작으므로 항이 이어질수록 계수는 점점 작아지게 된다.
-
-
-
SJF 알고리즘은 preemptive일 수도, nonpreemptive일 수도 있다.
-
이전 process가 실행되는 도중에 새로운 프로세스가 ready queue에 추가되었을 경우 둘 중에 어느방식으로 할 것인지 선택해야 한다.
-
새로 추가된 process의 next CPU burst값이 현재 실행중인 프로세스의 남은 시간보다 더 짧은 경우가 생긴다. 이 때, preemptive SJF algorithm은 preempt할것이고, nonpreemptive SJF algorithm은 현재 프로세스가 CPU burst가 끝나기까지 기다릴 것이다.
-
Preemptive SJF scheduling : shortest-remaining-time-first scheduling이라고도 불린다.
-
예시)
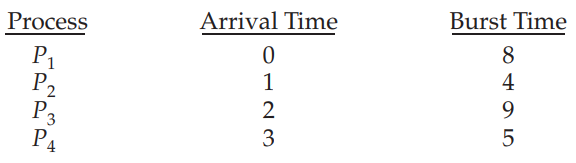
- Gantt chart는 다음과 같다 :

- 프로세스 별 waiting time : = 9ms, = 0ms, = 15ms, = 2ms
- 평균 waiting time : 6.5ms
- Nonpreemptive SJF scheduling : 7.75ms
나머지는 이어서....
참고 자료
- Abraham Silberschatz, Operating System Concepts, 10th edition
