Thread?
Basic information
- CPU 사용의 기본 단위. 스레드 ID, program counter, register set, stack으로 이루어져 있다.
- 같은 프로세스 내의 다른 스레드들과 code section, data section, and operating-systemd의 자원(open file이나 signal)을 공유한다.
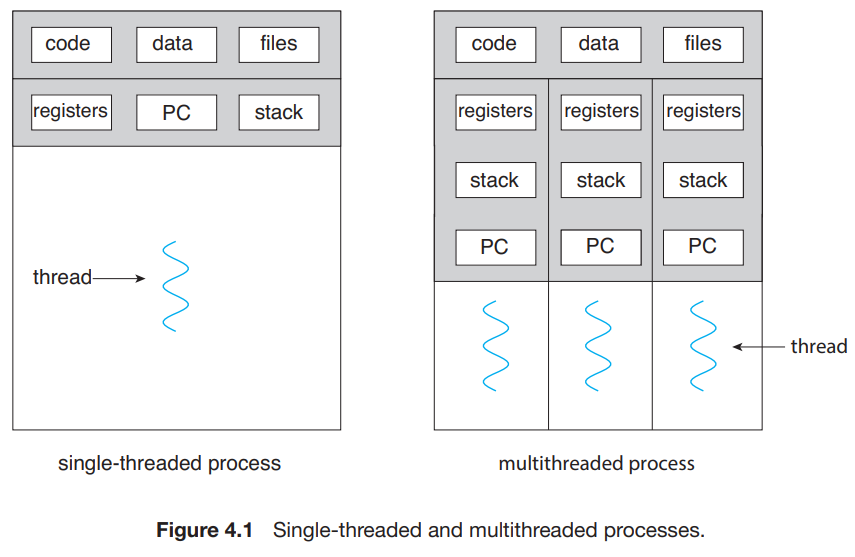
- 대부분의 운영체제에서 커널 또한 multithreaded이다.
Benefits
- multithreaded programming에는 4가지 이점들이 있다.
- Responsiveness : 프로그램의 일부가 block되거나 오래 걸리는 작업들을 하는 도중에도 사용자의 입력에 대해 반응할 수 있다. 예를 들어, single-threaded application의 경우 데이터를 로딩하는데에 너무 오래 걸려버리면 유저의 입력에 반응할 수 없다.(응답없음) 하지만 multi-threaded application의 경우 한 스레드가 데이터 로딩 담당을 맡게 되면 다른 스레드가 여전히 유저의 입력에 반응할 수 있게 된다.
- Resource sharing : 프로세스의 경우 resource sharing을 위해서는 shared memory나 message passing을 통해서 가능했다. 하지만 스레드의 경우 스레드가 속한 프로세스의 자원은 기본적으로 공유하게 된다.
- Economy : process를 만들 때에 메모리와 자원을 할당하는 것은 비용이 많이 든다. 스레드의 경우 속해있는 프로세스의 자원은 기본적으로 공유하므로, 만들 때, 그리고 context-switch를 하는 데에 더 경제적이다. 일반적으로 thread creation이 process creation보다 시간과 메모리가 덜 들고, context switching 또한 프로세스들 간보다 thread간이 더 빠르다.
- Scalability(확장성) : multiprocessor architecture에서 multithreading의 장점이 더 부각된다. 동시에 여러 processing core를 사용할 수 있기 때문.
Multicore Programming
- 하나의 processing chip 안에 여러 CPU core가 존재 -> multicore system
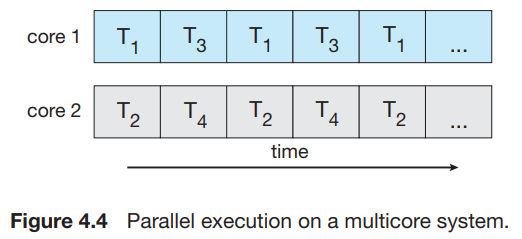
- 하나의 core만 존재할 경우 multithread application의 경우 하나의 코어에 여러 스레드들이 번갈아 가면서 실행됨. -> 여러 코어가 존재할 경우 실제로 여러 스레드가 동시에 실행될 수 있다.
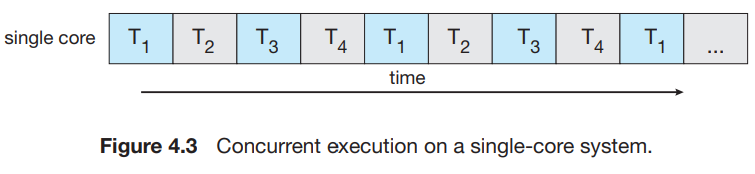
- concurrency와 parallelism의 구분
- concurrent system : 둘 이상의 task의 경우 모두를 진행시킬 수 있는 시스템.
- parallel system : 동시에 둘 이상의 task를 진행할 수 있다.
-> parallelism 없이 concurrency를 만족하는 것이 가능하다.
- 과거 single core system : ㄹㅇ 동시에 진행하는 것이 불가능 -> process간의 빠른 스위칭을 통해 동시에 실행되는 것 '처럼' 동작했다.
Programming Challenges
-
multicore system이 점점 발전하면서 여러 코어를 사용할 수 있게 scheduling algorithm을 짤 필요성이 증가되었다.
-
multicore system에서 programming을 하기 위한 5가지 challenges
- Identifying tasks : application을 분석해서 어떤 영역을 separate, concurrent task로 나누어 동작시킬 것인지를 찾아야 한다.
- Balance : 1번 작업 중, 동시에 수행할 task들 끼리 작업량을 동등하게 해야한다. 그렇지 않으면 비용이 더 발생할 수도 있음.
- Data splitting : application이 separate tasks로 나누어진 것 처럼, tasks에 의해 접근되고 실행되는 data들도 각각의 core에서 동작하게끔 나누어져야 한다.
- Data dependency : task들에 의해 접근되는 데이터는 둘 이상의 tasks의 dependencies가 확인되어야 한다. 그니까 한 task가 다른 task의 데이터에 의존적일 때, task가 제대로 서순을 맞춰서 synchronized되어야 한다.
- testing and debugging : 여러 코어에서 프로그램이 동시에 동작하므로, testing과 debugging이 굉장히 힘들어진다.
Types of Parallelism
- 두 가지 종류의 parallelism이 존재한다.
- Data parallelism
- 각 코어에서 어떻게 데이터를 나누어서 같은 operation을 동작시킬 건지에 대한 내용이다.
- 예를 들어, N의 사이즈를 갖는 array의 contents를 다 더한다고 생각해보자. 그러면 single-core system에서는 [0] ~ [N - 1]을 다 더할 것이지만, dual-core system에서는 core 0에서 thread A가 실행되고 [0] ~ [N / 2 - 1]까지의 값을 더하고, core 1에서 thread B가 실행되고 [N / 2] ~ [N - 1]까지의 값을 더할 것이다.
- Task parallelism
- data가 아니라 tasks(threads)를 다수의 computing core에 나눈다.
- 각 스레드는 unique operation을 수행한다.
- 서로 다른 스레드는 같은 데이터에서 작업할 수도, 다른 데이터에서 작업할 수도 있음.
- 위의 예시를 다시 보면, task parallelism의 경우 두 스레드가 같은 array를 보면서 unique한 통계작업 (하나는 다 더하고, 나머지 하나는 다 곱하고와 같은 작업)을 수행하는 경우가 이에 해당한다.
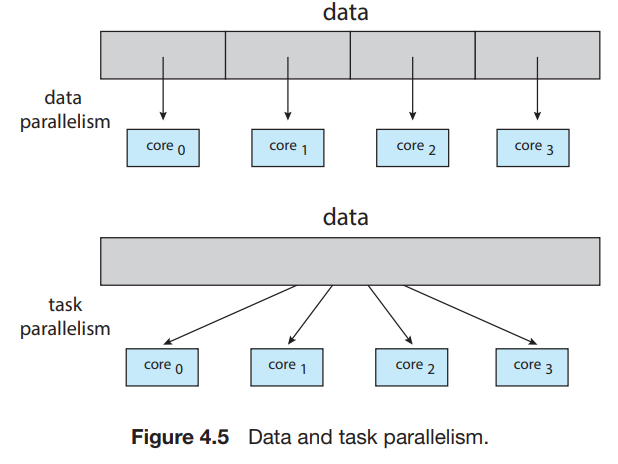
- 당연히 둘을 섞어서 써도 된다.
Multithreading Models
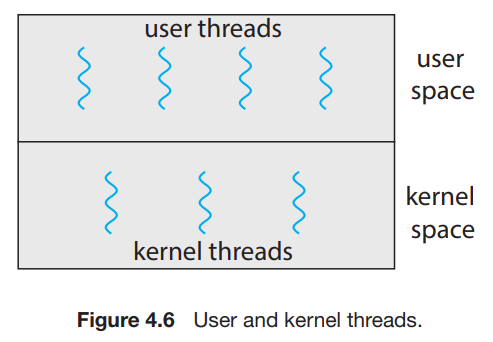
- user level에서 제공되는 user thread와, kernel에서 사용되는 kernel thread가 존재한다.
- user thread : kernel 위에서 제공되고 kernel의 지원 없이 관리될 수 있다.
- kernel thread : 운영체제에 의해 직접적으로 지원되고 관리된다.
- virtually(?) 현대의 운영체제들은 kernel thread를 지원한다.
User-level Threading vs Kernel-level Threading
여기 부분은 개인적 생각이 많이 들어간 부분이다.
-
user-level thread : kernel mode로 들어가지 않고 user mode에서만 구현되는 스레드.
- 그러다 보니 system call을 사용하지 않고 구현된다.
- 그러니까 user 입장에서는 CPU에 스레드가 번갈아가면서 실행되는 것이라고 생각하지만, kernel 입장에서는 그냥 단일 스레드 프로세스 하나가 쭉~ 실행되는 것 처럼 생각한다.(논리적 다중 스레드라고 생각하면 편할듯) -> 그러므로 당연히 직접 스레드/프로세스에 CPU를 할당하게 만드는 주체인 kernel이 개입하지 않으므로 실제로 여러 core를 각 스레드에 분배하지 않게 되고, 하나의 core만 이용해서 다중 스레드가 구현되게 된다. (concurrency는 만족하지만, parallelism은 만족하지 않게 됨.)
- TCB(Thread Control Block)를 user-level에서 관리하게 된다.
- blocking operation을 하게 되면 전체 process가 block 된다.(blocking system call 같은 거)
-
kernel-level thread : 실제 스레드를 kernel에서 생성하고 관리한다.
중요한 점 : 커널에서 사용하기 위한 스레드 X, 스레드를 만들기는 하는데 그 생성과 관리를 커널에서 해주는 것이다..! 그래서 운영체제가 개입할 수 있는 것임.- 여러 processor에 각 스레드가 할당될 수 있다.
- 커널 routine 또한 multithread될 수 있다.
- kernel-level thread가 block된다면, kernel에 의해 다른 thread가 스케줄 될 수 있다.
- kernel mode로의 switch가 필요하다.
- user-level thread보다 생성 및 관리하는데 더 느리다.
-
user-level threads는 kernel-level threads보다 더 작고 빠르다(context switch 입장에서 보면 user-level thread는 PC, register, stack 등을 바꿔가며 실행하면 되는데 kernel-level에서는 kernel이 thread 뿐만이 아니고 process단위로도 관리하기 때문에 더 오래걸린다.)
-
program counter, stack, registers, small PCB로 나타내어진다.
- user thread와 kernel thread간의 relationship이 존재해야만 한다. -> 3가지 모델에 대해서 알아보자.
user-level과 kernel-level에서의 blocking system call 호출 시 동작 차이
- 주목해야 할 점은 커널은 항상 동일한 행동을 한다는 것이다. : 프로세스/스레드가 blocking system call을 호출하면 그 프러세스/스레드를 block시킨 후에 그 CPU를 다른 프로세스/스레드에 할당시킨다.
- 이 관점에서 보았을 때, user level의 경우 시스템 콜을 호출하면 커널은 그 스레드(사실상 단일 스레드 프로세스라고 본다고 했으므로 그 프로세스 자체를 대상으로 할 것이다.)를 block 시키고, 다른 스레드나 프로세스를 실행시킬 것이다. 그래서 다시 user level 관점으로 넘어가면 하나의 스레드가 blocking system call을 호출하면 전체 프로세스가 block된다고 여겨지게 된다.
- kernel level에서 보았을 때에는 애초에 스레드를 별개로 구분하기 때문에 한 스레드가 blocking system call을 호출하면 바로 block 시킨 후 다른 스레드로 흐름을 넘길 것이다.
Many-to-One Models(Green Threads)
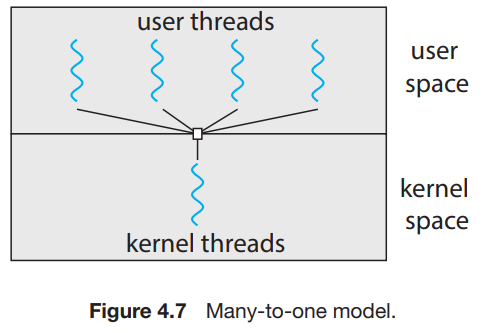
- 여러 user-level threads를 하나의 kernel thread에 매핑한다.
- thread management가 user space에서 thread library를 통해 이루어지기 때문에 효율적이다.
- 만약 스레드가 blocking system call을 호출하면 전체 process는 block될 것이다.
- 오직 한 번에 하나의 스레드만 kernel에 access할 수 있으므로, 여러 스레드들은 multicore system에서 동시에 작동할 수 없다.
- 위의 이유로, 현대의 많은 컴퓨터 시스템에서는 이 모델을 사용하지 않는다.
One-to-One Model
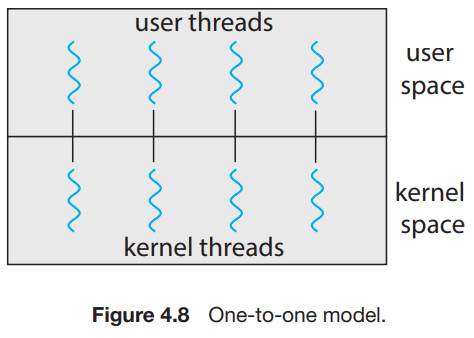
- 각각의 user thread를 kernel thread와 mapping시킨다.
- 만약 thread가 blocking system call을 호출했을 때 다른 thread가 실행될 수 있으므로 many-to-one model에 비해서 더 많은 concurrency를 제공한다.
- 단점은 다수의 커널 스레드가 있기에 커널이 관리할 자원이 많아져서 퍼포먼스가 저하될 수 있다. (커널 스레드 많아짐 -> 커널이 관리해야 할 자원이 많아짐 / 혹은 / 너무 할 일이 적은데 스레드 개수만 많이 나눠 놓게 되면 context switching 비용이 실제 동작에 비해 너무 커지게 됨)
- Windows, Linux가 이 모델을 사용한다.
Many-to-Many Model
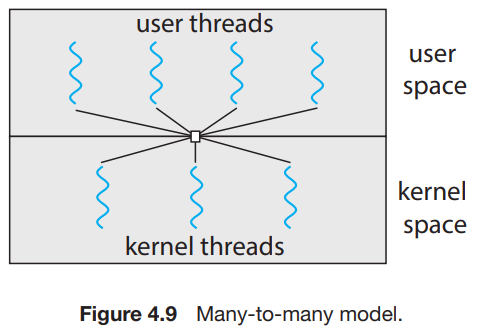
- 다수의 user-level thread를 그보다 작거나 같은 수의 kernel thread와 연결한다.
- kernel thread의 수는 application이나 machine에 따라 달라진다.
- many-to-one과 one-to-one 모델의 단점들을 모두 극복할 수 있다.
- 구현하기가 힘들다.
- 최근 컴퓨터들의 코어 수가 늘어남에 따라서 one-to-one을 그냥 사용하고 있다. (부담이 부담이 아니게 되어버림)
자매품 : Two-Level Model
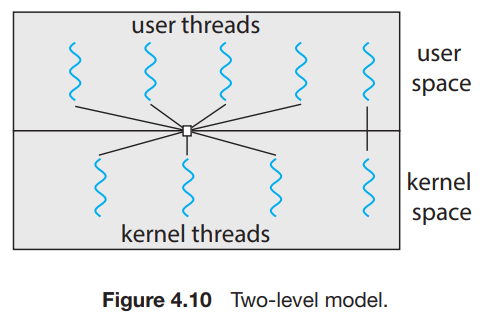
- Many-to-Many model을 채택하되, 몇몇 중요하다고 생각되는 작업들에 대해서는 one-to-one으로 kernel thread를 부여해주는 방식.
참고 자료
- Abraham Silberschatz, Operating SYstem Concepts, 10th edition

공부 내용 저장소