Lists, Stacks, and Queues
- array : 각 원소들에 직접적으로 접근할 수 있는 간단한 자료구조.
- 사이즈가 바뀔 수 있는 경우, 데이터를 삭제해야 하는 경우 문제가 생긴다.
- list : array와 달리 순서대로 접근할 수 있다. 가장 간단한게 linked list인데, 종류는 아래와 같다 :
- singly linked list : 각 item은 그것의 successor를 가리킨다.
- doubly linked list : 각 item은 그것의 predecessor이나 successor를 가리킨다.
- circularly linked list : 마지막 element는 NULL 대신 첫 번째 element를 가리킨다.
- Linked list들은 가변적인 사이즈를 다루기 좋고, insertion과 deletion에도 용이하다.
- But 원소에 접근할 때마다 O(n)의 시간복잡도가 필요하다는 단점이 있다.
- Lists는 kernel algorithm에 많이 쓰인다. stack이나 queue에도 쓰인다.
- stack : last in, first out(LIFO) 구조. 함수 호출시에 인자, 지역변수, return address가 stack에 push되고, 함수 return 시에 이 값들이 pop된다.
- queue : first in, first out(FIFO) 구조. CPU를 기다리는 작업들은 queue로 동작하게 된다.
Trees
- data를 hierarchically하게 표현할 수 있는 자료구조.
- binary search tree를 사용하는데, worst case의 경우 O(n)의 시간복잡도를 가짐 -> balanced binary search tree를 위해 red-black-tree를 리눅스에서 사용함. -> O(log n)의 시간복잡도를 가진다.
Hash Functions and Maps
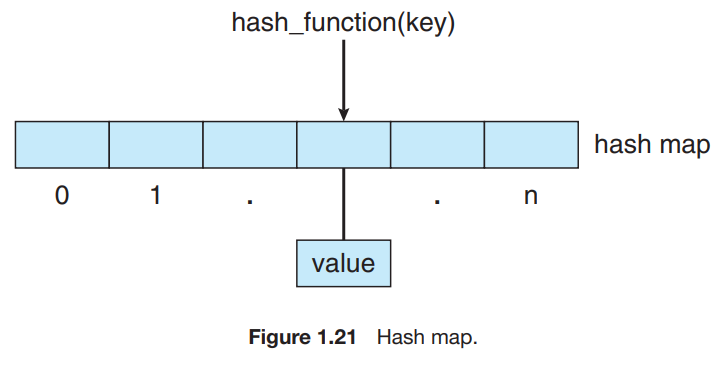
- hash function : data를 input으로 받고 numeric operation을 해서 numeric value를 return 한다.
- 이 numeric value를 table의 index로 사용해서 data에 빨리 접근할 수 있다.
- 기존 list에서 O(n)이 걸렸던 것과는 다르게 hash function을 사용하면 O(1)만에 찾을 수 있다. 그래서 operating system에서 광범위하게 쓰인다.
- 서로 다른 값을 가지는 데에도 불구하고 hash 값을 계산했을 때 같은 index값이 나오는 경우가 있다. (hash collision) 이 경우에는 그 index값에다가 data가 아닌 list를 갖다놓아서 겹치는 문제를 해결할 수 있다. 하지만 결국 이 과정을 통해 느려질 수 있다..
- hash function을 통해 hash map을 구현할 수 있다. hash map은 hash function을 이용해서 [key:value] 페어를 만들어 사용하는 것이다.
Bitmaps
- bitmap : n개의 이진 digit으로 구성된 string이다. n개의 items의 상태를 나타내는데에 사용된다. 예를들어, 여러 자원들이 사용중인지 아닌지에 대한 정보를 0과 1로 나타내서 비트 수만큼 자원의 상태를 나타낼 수 있다. -> space 효율성을 늘려준다.
- Disk drives의 경우 disk blocks라는 단위로 엄청나게 많이 쪼개지는데, 이 각각을 bitmap을 이용해서 사용중인지 아닌지 판별할 수 있다.

공부 내용 저장소