📔설명
데이터 분석 환경, 데이터 분석 도구 R의 특성을 알아보자.
그리고 R을 설치하고, GUI를 알아보고 R Studio를 설치하고 GUI를 알아보자!
데이터 분석을 위한 분석 도구
: SPSS, SAS, R, Python, Stata 등
🎈R 소개
데이터 분석 도구의 현황
R의 탄생
R:오픈소스 프로그램,통계/데이터마이닝과그래프를 위한 언어- 최신
통계분석과마이닝기능 제공 - 세계적으로 많은 사용자들이 다양한
예제공유 - 다양한 기능을 지원하는 많은
패키지가 수시로 업데이트
분석도구의 비교
| SAS | SPSS | 오픈소스 R | |
|---|---|---|---|
| 프로그램 비용 | 유료, 고가 | 유료, 고가 | 오픈소스 |
| 설치용량 | 대용량 | 대용량 | 모듈화로 간단 |
| 다양한 모듈 지원 및 비용 | 별도구매 | 별도구매 | 오픈소스 |
| 최근 알고리즘 및 기술반영 | 느림 | 다소느림 | 매우빠름 |
| 학습자료 입수의 편의성 | 유료 도서 위주 | 유료 도서 위주 | 공개 논문 및 자료 많음 |
| 질의를 위한 공개 커뮤니티 | NA | NA | 매우 활발 |
R의 특징
오픈소스 프로그램
사용자 커뮤니티에도움요청이 쉬움많은 패키지가 수시로 업데이트
그래픽및성능
프로그래밍이나그래픽측면 등 대부분의 주요 특징들에서상용 프로그램과 대등하거나월등
시스템 데이터 저장 방식
- 각
세션 사이마다시스템에데이터셋을 저장하므로 매번 데이터를로딩할 필요가 없고명령어 스토리도 저장가능
모든 운영체제
- 윈도우, 맥, 리눅스 운영체제에서 사용 가능
표준 플랫폼
S 통계 언어기반 구현R/S 플랫폼은 통계전문가들의 사실상의 표준 플랫폼
객체지향언어이며함수형 언어
통계 기능뿐만 아니라 일반 프로그래밍 언어처럼자동화하거나새로운 함수를 생성하여 사용 가능객체지향 언어 특징SAS, SPSS에서 회귀분석 시 화면에 결과가 산더미로 나옴- 분석 결과 활용을 위해서는
추가로 프로그래밍 하거나 별도 작업 필요 R은 추정계수, 표준오차, 잔차 등 결과값을객체에 저장하여 필요한 부분 호출 가능
함수형 언어 특징깔끔하고단축된 코드- 매우
빠른 코드 수행 속도 - 단순한 코드로
디버깅 노력 감소 병렬 프로그래밍으로의 전환 용이

R Studio
오픈소스- 다양한
운영체제지원 - 메모리에
변수가 어떻게 되어 있는지와타입이 무엇인지 볼 수 있음 스크립트관리 및도큐먼테이션편리코딩을 해야하는 부담이 있으나스크립트용 프로그래밍으로 어렵지 않게자동화가능래틀(Rattle)-무료 마이닝 툴은 GUI가 패키지와 긴밀하게 결합돼 정해진 기능만 사용 가능해 업그레이드가 제대로 되지 않으면통합성에 문제 발생
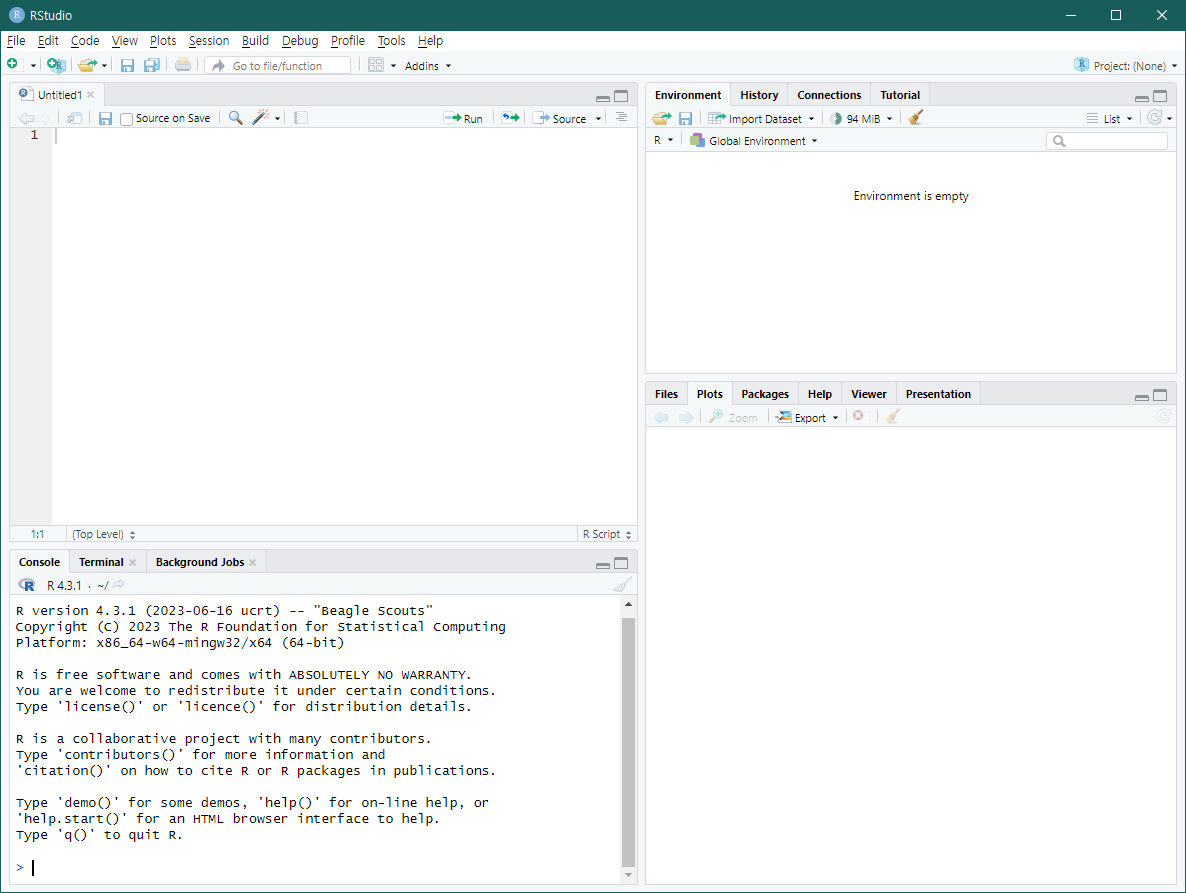
R기반 작업환경
업무 규모와본인에게익숙한 환경이 무엇인지를 기준으로 선택- 기업환경에서는 64bit 듀얼코어, 32GB RAM, 2TB 디스크, 리눅스 운영체제 추전
R의 메모리- 64bit 유닉스 : 메모리 무제한
- x86 64bit 환경 : 128TB 까지 지원
- 64bit 윈도우 환경 : 8TB 까지 지원
🎨R 기초
통계 패키지 R
R Studio 구성화면
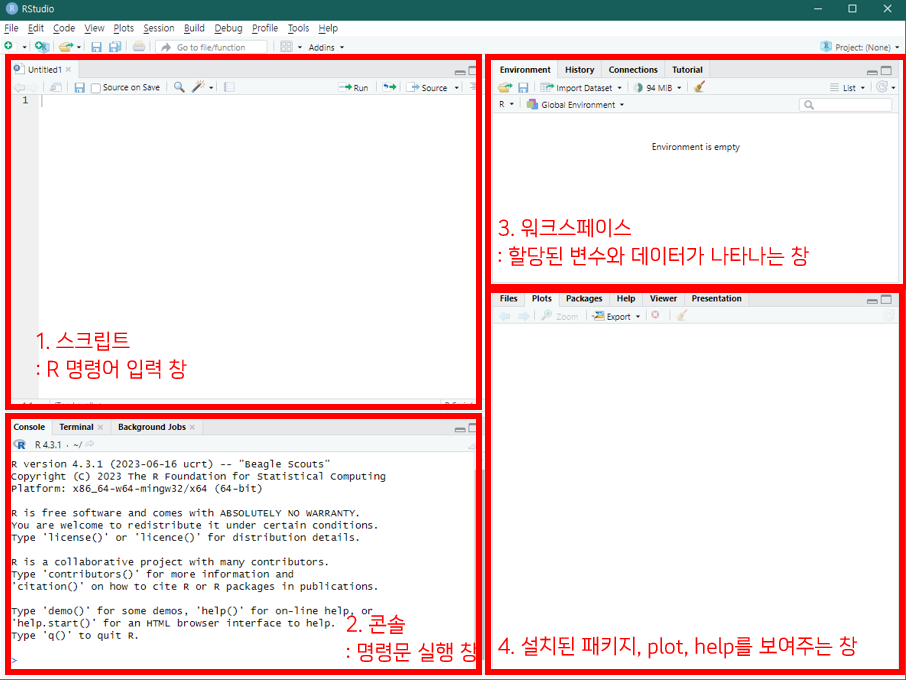
R GUI의 화면구성
패키지(Package)
패키지란?
:R함수와데이터및컴파일된 코드의 모임
패키지 불러들이기하드디스크:R 설치또는업데이트를 통해 설치웹:CRAN 저장소에 약 5000개의 유용한 패키지 자동 설치
install.packages("AID") install.packages("AID","D:\\R\\R-4.3.1\\library") #수동설치패키지 도움말library(help=AID) #다운로드 된 AID 패키지의 help 다큐먼트 보여줌 help(package=AID) #웹을 통해 AID 패키지의 다큐먼트 보여줌 ?함수 RSiteSearch("함수명")
프로그램 파일 실행
스크립트로 프로그래밍 된 파일 실행
source("파일명")
#한 줄 실행 : Ctrl+R
#여러줄 실행 : 드래그 후 Ctrl+R
#주석 처리 : #-
프로그램 파일-
sink 함수-R코드 실행 결과를 특정 파일에서 출력sink(file, append, split) # file : 출력할 파일명(디렉터리 포함/디폴트 디렉터리) # append : 파일에 결과를 덮어쓰거나 추가해서 출력(디폴트 값(false)는 덮어쓰기) # split : 출력파일에만 출력하거나 콘솔창에 출력(디폴트 값(false)는 파일에만 실행 결과 출력) #ex sink("a_out.pdf") sink("d:/study/r/a_out.pdf")
-
pdf 함수-그래픽 출력을 pdf파일로 지정pdf("a_out.pdf") pdf("d:/study/r/a_out.pdf")
-
파일 닫기 함수dev.off()
-
배치모드 기능
-
배치모드
: 사용자와인터렉션이 필요하지 않는 방식.
매일 돌아가야 하는 시스템에서프로세스를 자동화할 때 유용 -
배치파일 실행 명령-DOS창
$R CMD BATCH batch.R-
Path지정
:환경변수에서 변수명path를 찾아r프로그램의실행파일 위치추가 -
배치파일 실행-batch.R 위치에서
R CMD BATCH batch.R변수와 벡터 생성
R 데이터 유형과 객체
| 기능 | R코드 |
|---|---|
| 숫자(Number) | integer, double |
| 논리값(Logical) | True(T), False(F) |
| 문자(Character) | "a","abc" |
R 기초 중 기초
출력하기
print() #출력형식을 지정할 필요 없음. 한번에 하나의 객체만 출력
cat() # 여러 항목을 묶어서 연결된 결과로 출력. 복합적 데이터 구조(행렬, list) 출력 불가
#ex
print(a)
cat("a","b","c")
# a b c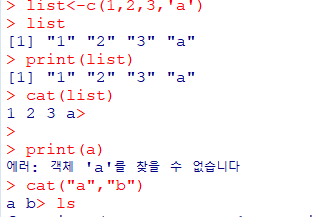
변수에 값 할당하기(대입 연산자)
<-
<<-
=
->변수 목록보기
ls()
# "hi"
ls.str()
# hi : num[1:3] 1 2 3
변수 삭제하기
rm()
rm(list=ls()) #모든 변수 삭제시 사용
벡터 생성하기
c()
#벡터 원소 중 하나라도 문자가 있으면 모든 원소의 모드는 문자 형태로 변환
R 함수 정의하기
function(매개변수1, 매개변수2 ,..., 매개변수 n){
expr 1,
expr 2, ...,
expr m
}
#expr 특징
#지역변수 : 단순히 값을 대입하기만 하면 지역변수로 생성, 함수 종료시 지역변수 삭제
#조건부 실행 : if문
#반복 실행 : for, while repeat 문
#전역변수 : <<-를 사용하여 지정 가능하나 추천X
R 프로그램 소개
데이터 할당
a<-1
a=1화면 프린트
a
print(a)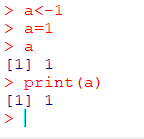
결합
c 함수는문자, 숫자, 논리값, 변수를 모두 결합 가능하며벡터와데이터셋생성 가능

수열
콜론(:),seq함수를 사용하여시작값에서최종값까지 연속적인 숫자 생성seq함수는 간격과결과값의 길이 제한가능
seq(from=0, to=20, by=2) # 시작, 끝, 간격
seq(from=0,to=20,length.out=5) #결과가 5개 나오도록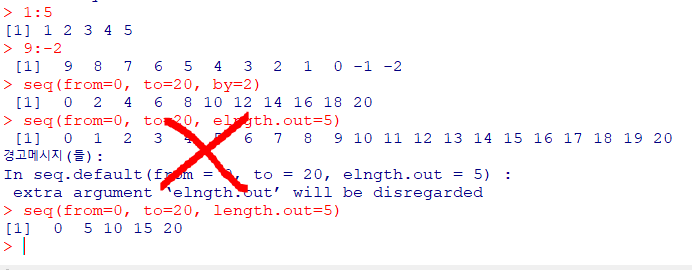
반복
rep함수는 숫자나 변수의 값들을 time인자에지정한 횟수만큼 반복
rep(1,time=5) #5번 출력
rep(1:4, each=2) # 1~4를 각각 2개씩 출력
문자 붙이기
paste 함수는 문자열을sep인자에 지정한구분자로 연결

문자열 추출
substr(문자열, 시작점, 끝점)함수는문자열의특정부분을 추출 가능처음 시작은1
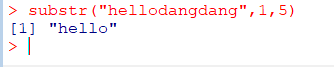
논리값

논리 연산자
같다: ==같지 않다: !=작다, 작거나 같다: <, <=크다, 크거나 같다: >, >=
벡터의 원소 선택하기
V[n]: 선택하고자 하는 자리수V[-n]: 제외하고자 하는 자리수n:원소의 자리수V:벡터 이름

벡터의 연산
| 연산자 우선순위 | 뜻 | 표현방법 |
|---|---|---|
| [ [[ | 인덱스 | a[1] |
| $ | 요소 뽑아내기, 슬롯 뽑아내기 | a$coef |
| ^ | 지수 | 5^2 |
| - + | 단항 마이너스, 플러스 부호 | -3, +5 |
| : | 수열 생성 | 1:10 |
| %any% | 특수 연산자 | %/% : 나눗셈 몫 %% : 나눗셈 나머지 %*% : 행렬 곱 |
| * / | 곱하기, 나누기 | 3*5, 3/5 |
| + - | 더하기, 빼기 | 3+5 |
| == != <> <= >= | 비교 | 3==5 |
| ! | 논리 부정 | !(3==5) |
| & | 논리 and, 단축 and | TRUE & TRUE |
| | | 논리 or, 단축 or | TRUE|TRUE |
| ~ | 식(formula) | lm(log(brain)~log(body),data=Animals) |
| -> ->> | 대입(왼쪽을 오른쪽으로) | 3->a |
| = | 대입(오른쪽을 왼쪽으로) | a=3 |
| <- <<- | 대입(오른쪽을 왼쪽으로) | a<-3 |
| ? | 도움말 | ?lm |
벡터의 기초통계
| 기능 | R코드 | 비고 |
|---|---|---|
| 평균 | mean(변수) | 변수의 평균 |
| 합계 | sum(변수) | 변수의 합계 |
| 중앙값 | median(변수) | 변수의 중앙값 |
| 로그 | log(변수) | 변수의 로그값 |
| 표준편차 | sd(변수) | 변수의 표준편차 |
| 분산 | var(변수) | 변수의 분산 |
| 공분산 | cov(변수1, 변수2) | 변수간 공분산 |
| 상관계수 | cor(변수1, 변수2) | 변수간 상관계수 |
| 변수의 길이 값 | length(변수) | 변수간 길이 |
*공분산 : 두개의 확률변수의 선형관계
*상관계수 : 두 변수간 선형관계의 정도를 수량화하는 측도
a<-c(1,2,3)
length(a)
3R프로그래밍시 자주하는 실수
| 기능 | R코드 | 비고 |
|---|---|---|
| 함수를 불러오고 괄호 닫기 | function 함수의 {}, 함수의 () | ex) 선언시 {}, 호출시 () |
| 윈도우 파일 경로에서 역슬래시 두 번씩 쓰기 | D:\study\r\test.csv (D:studyrtest.csv로 인식) | \를 2번 쓰거나 /를 1번 |
| <-사이를 붙여쓰기 | x< -pi | 에러: 객체 'x'를 찾을 수 없습니다. |
| 여러줄을 넘어서 식을 계속 이어갈 때 | > sum<-1+2+3 > +4+5 [1] 9 >sum [1] 6 | |
| ==대신 =를 사용하지 말 것 | == : 비교 연산자 = : 대입 연산자 | |
| 1:(n+1) 대신 1:n+1로 쓰지 말 것 | >n<-5; >1:n+1; [1] 2 3 4 5 6 >1:(n+1); [1] 1 2 3 4 5 6 | 1. 1:n 한 값에 1을 더한 것이 출력 2. 1부터 n+1까지 출력 |
| 패키지를 불러오고 library()나 require()를 수행할 것 | ||
| 2번 써야할 것과 1번 써야할 것을 혼돈하지 말 것 | aList[[a]] vs aList[a], && vs &, || vs | 등 | |
| 인자의 개수를 정확히 사용할 것 | mean(9,10,11) | 원래는 10인데, 이렇게 하면 9만 나옴 |
👝입력과 출력
데이터 분석 과정
분석자가분석목적에 맞는 적절한분석방법론을 선택해서 정확한 분석을 통해 얻은 결과를통찰력을 가지고해석함으로써 분석 과정 마침데이터 분석을 위해서는분석자가 분석을 위해설계된 방향으로 데이터를 정확하게입력받는 것에서부터 시작데이터 핸들링:입력된 데이터를 다양한전처리 작업을 거쳐분석이 가능한 형태로 재정리데이터 출력:분석된 결과를 이해하기 쉽고 잘 해석될 수 있도록 생산출력된 결과는보고서의 형태로 정리되어최종 의사결정자와고객에게 전달됨으로써 통계분석 과정 종료
R에서의 데이터 입력과 출력
*R에서 다룰 수 있는 파일 타입
- Tab-delimited text
- Comma-separated text
- Excel file
- JSON file
- HTML/XML file
- Database
- (Other) Statistical SW's file
키보드로 데이터를 입력
- 데이터 양이 적어
직접 입력c() : combine 함수
- 데이터 편집기 활용
빈 데이터 프레임 생성->편집기를 불러와 편집하고데이터 프레임에덮어 씌우기
출력할 내용의 자리수 정의
R의 부동소수점표현 :7자리

*digits : 전체 숫자 자리수
파일에 출력하기
cat("출력할 내용", 변수,"\n",file="파일이름",append=T)
sink("파일이름")
...출력할 내용
sink()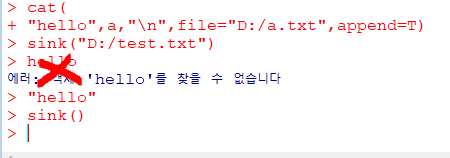


파일 목록 보기

고정자리수 데이터 파일(fixed-width file) 읽기
read.fwf("파일이름", widths=c(w1,w2,...,wn))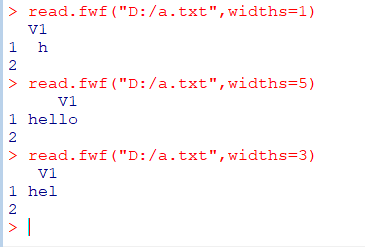
테이블로 된 데이터 파일 읽기(변수 구분자 포함)
read.table("파일이름",sep="구분자")
#주소, 이름, 성, 등의 텍스트를 요인으로 인식시
read.table("파일이름",sep="구분자",stringsASFactor=F)
#결측치를 NA가 아닌 다른 문자열로 표현시
read.table("파일이름",sep="구분자",na.strings=".")
#파일의 첫행을 변수명으로 인식하고자 할 때
read.table("파일이름",sep="구분자",header=T)CSV 데이터 파일 읽기(변수 구분자는 쉼표)
read.csv("파일이름",header=T)
#주소, 이름, 성 등의 텍스트를 요인으로 인식시
read.csv"파일이름",header=T,as.is=T)csv 데이터 파일로 출력(변수 구분자는 쉼표)
write.csv(행렬/데이터프레임,"파일이름",row.names=F)
#1행을 변수명으로 자동 인식하지만 변수명이 아닐 경우
write.csv(dfm,"파일이름",col.names=F)
#1열에 레코드 번호를 자동 생성하지만 레코드 번호를 생성하지 않을 경우
write.csv(dfm,"파일이름",row.names=F)웹에서 데이터 파일을 읽어 올 때(변수 구분자는 쉼표)
read.csv("http://www.example.com/download/data.csv")
read.table("http://www.example.com/download/data.txt")HTML에서 테이블 읽어 올 때
library(XML)
url<-'http://www.example.com/data/table.html'
t<-readHTMLTable(url)복잡한 구조의 파일(웹 테이블) 읽기
lines<-readLines("a.txt",n=num)
token<-scan("a.txt",what=numeric(0))
token<-scan("a.txt",what=list(v1=character(0),v2=numeric(0))
token<-scan("a.txt",what=list(v1=character(0),v2=numeric(0),n=num,nlines=num,skip=num,na.strings=list)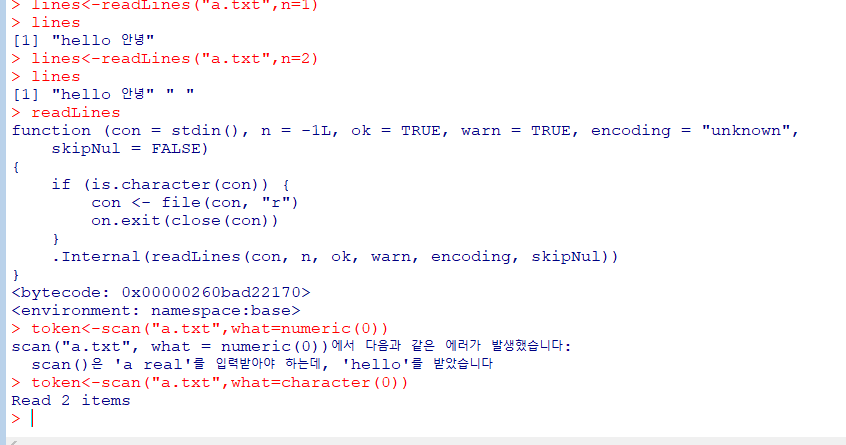
🎩데이터 구조와 데이터 프레임
벡터(Vector)
여러 개의 원소를 가지는 하나의 변수
동질적
: 한 벡터의 모든 원소는 같은 자료형 또는 같은 모드(mode)
위치로 인덱스
: V[2]는 v벡터의 2번째 원소

인덱스를 통해 여러 개의 원소로 구성된 하위 벡터 반환
: V[c(2,3)]은 V벡터의 2번째, 3번째 원소로 구성된 하위 벡터
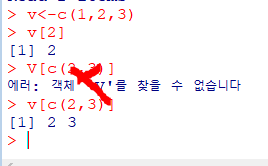
원소들은 이름을 가질 수 있음
V<-c(10,20,30);
names(V)<-c("dang","bam","cucu")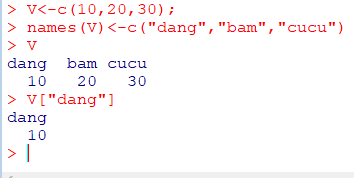
리스트(List)
사전(Dictonary),해시(Hash),탐색표(Lookup Table)과 유사
이질적
: 여러 자료형의 원소들 포함
위치로 인덱스
: L[[2]]는 L리스트의 2번째 원소
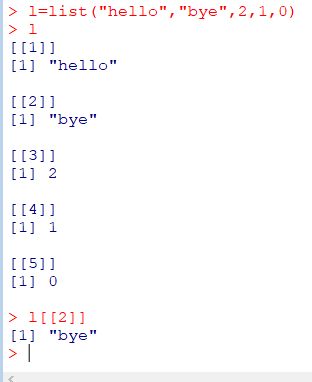
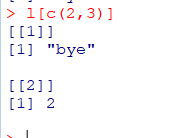
하위 리스트를 추출
: L[c(2,3)]는 L리스트의 2번째, 3번째 원소로 이루어진 하위 리스트
원소들은 이름을 가질 수 있음
: L[["Dang"]]와 L$Dang는 둘다 Moe라는 이름의 원소 지칭

R에서의 자료형태(Mode)
| 객체 | 예시 | 모드(Mode) |
|---|---|---|
| 숫자 | 3.1415 | 수치형(Numeric) |
| 숫자 벡터 | c(2,3,4,5.5) | 수치형(Numeric) |
| 문자열 | "dang" | 문자형(Character) |
| 문자열 벡터 | c("Tom","dang","good") | 문자형(Character) |
| 요인 | factor(c("A","B","C")) | 수치형(Numeric) |
| 리스트 | list("Tom","dang","good") | 리스트(List) |
| 데이터 프레임 | data.frame(x=1:3,y=c("Tom","Dang","Good")) | 리스트(List) |
| 함수 | 함수(Function) |

데이터 프레임(Dataframe)
특징
강력하고유연한 구조.SAS의데이터셋을 모방해서 만들어짐- 데이터 프레임의
리스트의 원소는벡터또는요인 - 그
벡터와요인은데이터 프레임의열 벡터와요인들은동일한 길이표 형태의 데이터 구조- 각
열은 서로 다른데이터 형식을 가질 수 있음 열에는이름이 있어야 함
데이터 프레임 원소 접근방법

그 밖의 데이터 구조들
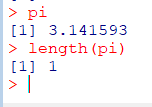
단일값(Scalar)
R에서는원소가하나인 벡터로 인식/처리
행렬(Matrix)
차원을 가진벡터로 인식
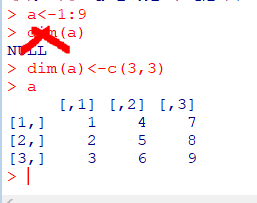
배열(Array)
행렬에3차원또는n차원까지 확장된 형태- 주어진
벡터에더 많은 차원을 부여하여 배열 생성

2행 3열,2개의 배열로 나뉨
요인(Factor)
벡터처럼 생겼으나, R에서는벡터에 있는유일값의 정보를 얻어내는데, 이유일값들을요인의 수준(Level)이라고 함범주형 변수,집단분류

벡터, 리스트, 행렬 다루기
행렬은 R에서차원을 가진벡터,텍스트마이닝,소셜네트워크분석에 활용재활용 규칙(Recycling Rule):길이가서로 다른두벡터에 대해연산을 할 때, R은짧은 벡터의처음으로 돌아가연산이 끝날 때까지원소들을재활용

벡터에 데이터 추가
v<-c(v,newItems)
v[length(v)+1<-newItem
벡터에 데이터 삽입
append(vec,newvalues,after=n)
요인 생성
f<-factor(v)
# v: 문자열 또는 정수 벡터
f<-factor(v,levels)
여러 벡터를 합쳐 하나의 벡터와 요인으로 만들기
comb<-stack(list(v1=v1,v2=,v2,v3=v3))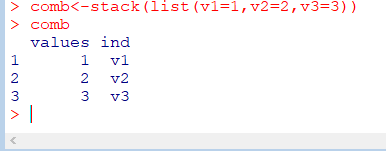
벡터 내 값 조회
# 벡터 내 1,3,5,7번째 값 조회
벡터[c(1,3,5,7)]
#벡터 내 2,4번째 값 제외 조회
벡터[-c(2,4)]리스트
list(숫자, 문자, 함수)리스트 생성하기
L<-list(x,y,z)
L<-list(valuename1=data, valuename2=data,valuename3=data)
L<-list(valuename1=vec,valuename2=vec,valuename3=vec)리스트 원소 선택
#n번째 원소
L[[n]]
#목록
L[c(n1,n2,...,nk)]이름으로 리스트 원소 선택
L[["name"]], L$name리스트에서 원소 제거
L[["name"]]<-NULL
NULL원소를 리스트에서 제거
L[sapply(L,is.null)]<-NULL
L[is.na(L)]<-NULL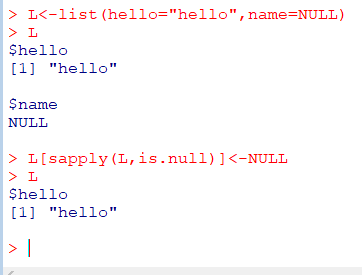

행렬
data대신숫자를 입력시행렬의 값이동일한 수치값부여
matrix(data,행 수, 열 수)
a<-matrix(data,2,3)
d<-maxtirx(0,4,5)
e<-matrix(1:20,4,5)
차원
e행렬의 차원은4행 5열
dim(행렬)
dim(e)
대각(Diagonal)
e행렬의대각선의값반환
diag(행렬)
diag(e)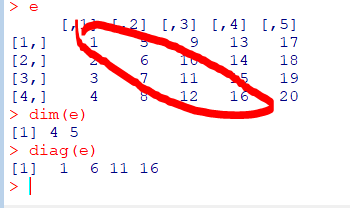
전치(Transpose)
e행렬의전치행렬(행,열 바꿈)을 반환
t(행렬)
t(e)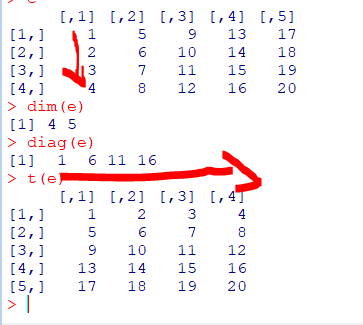
역
solve(matrix)행렬의 곱
행렬%*% t(행렬)
a%*%t(a)
행 이름 부여
rownames(a)<-c("행이름1",..."행이름n")
열 이름 부여
colnames(a)<-c("열이름1",..."열이름n")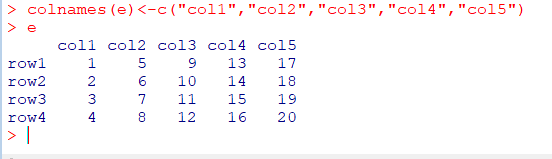
행렬의 연산 +, -
f+f
f-f
f+1
f-1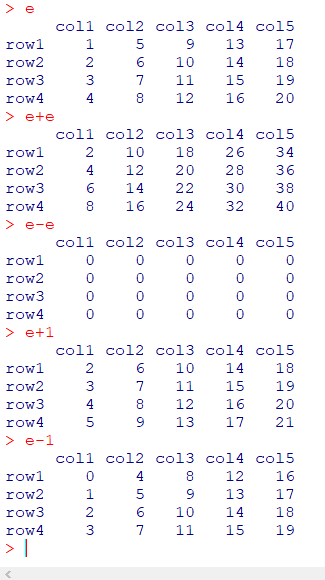
행렬의 연산 *
f%*%f
f*3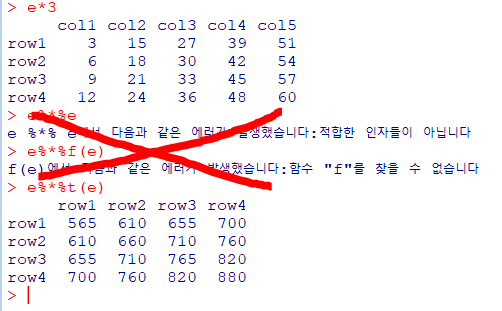
행렬에서 행, 열 선택하기
vec<-matrix[1,] #1행 전체가 vec
vec<-matrix[,3] #3열 전체가 vec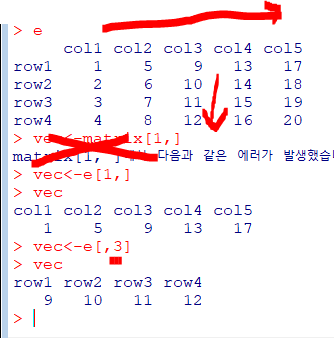
데이터 프레임
다변량 데이터 분석을 위해 가장 많이 활용되는 데이터 구조행과열을추출/제거/수정함으로써데이터를 분석할 수 있는 최적의 상태로자료를 유지해야 하며 이러한 과정은데이터 전처리와데이터 클렌징에서 가장 많이 활용데이터에서각각의 변수에 해당하는열들의 모임
데이터 프레임
벡터들로 데이터셋 생성
#각자 벡터명이 열 이름
data.frame(벡터, 벡터, 벡터)
레코드 생성
new<-data.frame(a=1,b=2,c=3,d="a")
열 데이터(변수)로 데이터 프레임 만들기
dfm<-data.frame(v1,v2,v3,f1,f2)
dfm<-as.data.frame(list.of.vectors)데이터셋 행결합
- 두 데이터프레임을
행으로 결합
rbind(dfrm1, dfrm2)
newdata<-rbind(newdata,new)
데이터셋 열결합
cbind(dfrm1, dfrm2)
cbind(newdata,newcol)
#newcol=1:150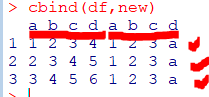
데이터 프레임 할당
n=1000000
dtfm<-data.frame(dosage=numeric(n),lab=character(n),respones=numeric(n))데이터 프레임 조회1
#데이터셋 내 성별이 남성만 조회
dfrm[dfrm$gender="m"]데이터 프레임 조회2
#데이터셋의 변수1과 변수2의 조건에 만족하는 레코드의 변수3과 변수4만을 조회
dfrm[dfrm$변수1>4 & dfrm$변수2>5, c(변수3,변수4)]데이터 프레임 조회3
#데이터셋의 변수1 내 "문자"가 들어있는 케이스들의 변수2, 변수3 값 조회
dfrm[grep("문자",dfrm$변수1, ignore.case=T),c("변수2,변수3")]데이터셋 조회
#데이터셋의 특정변수 값이 조건에 맞는 변수셋 조회.
#subset은 벡터와 리스트에서도 선택 가능
subset(dfrm,select=변수,subset=변수>조건)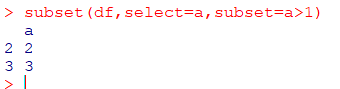
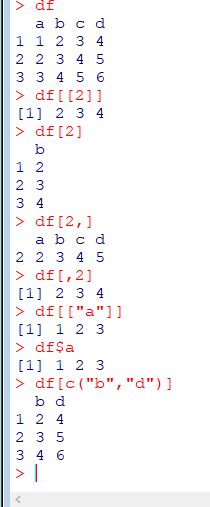
데이터 선택
데이터 병합
#공통변수로 데이터셋 병합
merge(df1, df2, by="df1과 df2의 공통 열 이름")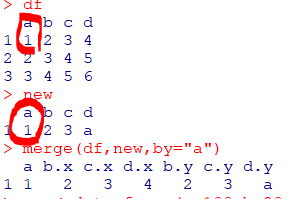
열 네임 조회
# 변수들의 속성 조회
colnames(변수)
행/열 선택
subset(dfrm, select=열이름)
subset(dfrm,select=c(열이름1,...,열이름n))
subset(dfrm, select=열이름, subset=(조건))이름으로 열 제거
subset(dfrm, select=-열이름)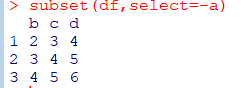
열 이름 바꾸기
colnames(dfrm)<-newnamesNA 있는 행 삭제
NA_cleaning<-na.omit(dfm)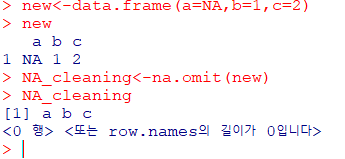
데이터 프레임 두 개 합치기
#열-열로 붙음
cbind_dfm<-cbind(dfm,dmf2)
#행-행으로 붙음
rbind_dfm<-rbind(dfm,dmf2)
# cbind는 행의 개수가 동일해야함 (recycling rule)
# rbind는 열의 개수와 열의 이름이 동일해야 함
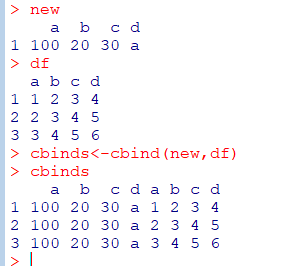

두 개의 데이터 프레임을 동일한 변수 기준으로 합치기
merge(dfm1, dfm2, by="T_name")
merge(dfm1, dfm2, by="T_name",all=T)
자료형 데이터 구조 변환
데이터 프레임의 내용에 쉽게 접근하기
#expr:열 이름
with(dfm,expr)
자료형 변환하기

데이터 구조 변환하기
as.data.frame()
as.list()
as.matrix()
as.vector()데이터 구조 변경
| 변환 | R 코드 |
|---|---|
| 벡터->리스트 | as.list(vec) |
| 벡터->행렬 | 1열짜리 행렬 : cbind(vec) 또는 as.matrix(vec) 1행짜리 행렬 : rbind(vec) n x m 행렬 : maxtrix(vec,n,m) |
| 벡터->데이터 프레임 | 1열짜리 데이터프레임 : as.data.frame(vec) 1행짜리 데이터프레임:as.data.frame(rbind(vec)) |
| 리스트->벡터 | unlist(lst) |
| 리스트->행렬 | 1열짜리 행렬 : as.matrix(lst) 1행짜리 행렬 : as.maxtrix(rbind(lst)) n x m 행렬 : maxtrix(lst,n,m) |
| 리스트->데이터 프레임 | 리스트 원소들이 데이터의 열이면 : as.data.frame(lst) 리스트 원소들이 데이터의 행이면 : rbind(obs[[1]],obs[[2]]) |
| 행렬->벡터 | as.vector(mat) |
| 행렬->리스트 | as.list(mat) |
| 행렬->데이터 프레임 | as.data.frame(mat) |
| 데이터 프레임->벡터 | 1열짜리 데이터 프레임 : dfm[[1]] or dfm[,1] 1행짜리 데이터 프레임 : dfm[1,] |
| 데이터 프레임->리스트 | as.list(dfm) |
| 데이터 프레임->행렬 | as.matrix(dfm) |

벡터의 기본 연산
벡터 연산

함수 적용
sapply(변수, 연산함수)
파일 저장
write.csv(변수이름, "파일이름.csv")
write.csv(a,"test.csv")파일 저장2
save(변수이름, file="파일이름.Rdata")
svae(a,file="a.Rdata")파일 읽기
read.csv("파일이름.csv")
read.csv("a.csv")파일 불러오기
load("파일.R")
load("a.R")
source("a.R")데이터 삭제
rm(변수)
rm(list=ls(all=TRUE))그 외에 간단한 함수
데이터 불러오기
data()
data(데이터셋)데이터셋 요약
summary(데이터셋)데이터셋 조회
#상위 6개 레코드까지 조회
head(데이터셋)패키지 설치
install.packages("패키지 명")패키지 불러오기
library(패키지명)작업 종료
q()워킹 디렉토리 지정
#R데이터와 파일 등을 로드하거나 저장 시 지정
setwd("~/")🧵데이터 변형
주요 코드
요인으로 집단 정의

벡터를 여러 집단으로 분할 (길이만 같으면 됨)
모두 벡터로 된리스트반환
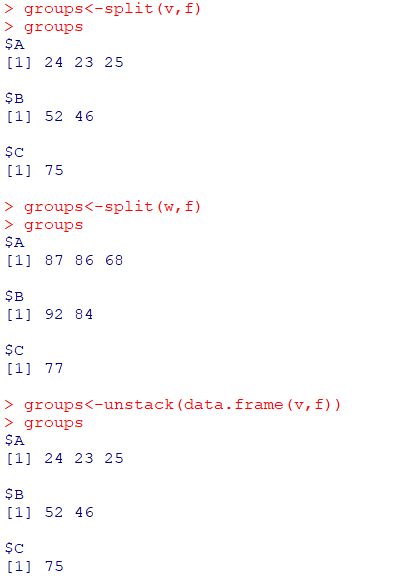
데이터 프레임을 여러 집단으로 분할
MASS패키지,Cars98데이터셋 활용

리스트의 각 원소에 함수 적용
lapply(결과를 리스트 형태로 반환)
list<-lapply(l,func)
sapply(결과를 벡터/행렬로 반환)
vec<-sapply(l,func)행렬에 함수 적용
apply(x,margin,func,...)
m<-apply(mat,1,func)
m<-apply(mat,2,func)데이터프레임에 함수 적용
dfm<-lapply(dfm,func)
dfm<-sapply(dfm,func)
dfm<-apply(dfm,func)
#데이터프레임이 동질적인 경우만(모두 문자/숫자) 활용 가능
#데이터프레임을 행렬로 변환한 후 함수 적용대용량 데이터의 함수 적용
#sapply 이용
cors<-sapply(dfm,cor,y=targetVariable)
mask<-(rank(-abs(cors))<=10)
best.pred<-dfm[,mask]
lm(targetVariable~best.pred)
#많은 변수가 있는 데이터에서 다중회귀분석
#1. 데이터 프레임에서 타켓 변수 정함
#2. 타겟변수와 상관계수 구함
#3. 상관계수가 높은 상위 10개의 변수를 입력변수로 선정
#4. 타겟변수와 입력변수로 다중회귀분석집단별 함수 적용
tapply(vec,factor,func)
#데이터가 집단(factors)에 속해있을 때 합계/평균 구하기행집단 함수 적용
by(drm,factor,func)
#요인별 선형회귀선 구하기
model(dfm,factor,function(df) lm(종속변수~독립변수1+,...,data=df))병렬 벡터, 리스트들 함수 적용
mapply(factor, vec1, ...,vec k)
mapply(factor, list1, ..., list k)문자열, 날짜 다루기
문자열 길이
length()는문자열 길이가 아닌벡터의 길이

문자열 연결


하위문자열 추출

구분자로 문자열 추출
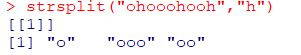
하위 문자열 대체
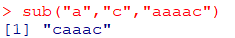

쌍별 조합

날짜 반환1

날짜 변환2

날짜 조회

날짜 일부 추출
yday: day of the year. (한달(30일)+16일=46)


