📔설명
데이터 마트를 구성하는 요약변수와 파생변수를 알아보고 reshape 패키지를 활용하여 데이터마트를 생성해보자.
sqldf패키지와 plyr 패키지를 활용해 데이터를 핸들링하고, data.table 패키지를 이해하고 활용해보자.
모형을 개발할 때 문제를 가장 잘 해석할 수 있는 변수를 찾는 것은 모형 개발에서 가장 중요한 핵심단계다.
요약변수
- 데이터를 특정 기준에 따라
사칙연산을 통해 만들어낸 변수
파생변수
사용자의 노하우를 기반으로 새롭게 만들어 낸 변수
reshape
데이터 마트를 생성할 수 있도록데이터를 녹이고(melt)다시형상화(cast)할 수 있는 R패키지분석용 마트 설계에 활용
sqldf
SAS에서SQL을 활용할 수 있듯,R에서도SQL을 사용하기 위한 패키지
data.table
dataframe과 같은 구조를 가지고 있으나key를 활용해서훨씬 빠른 연산가능
🪀데이터 변경 및 요약
R reshape를 이용한 데이터 마트 개발
데이터 마트
데이터 웨어하우스와사용자사이의중간층에 위치하나의 주제또는하나의 부서 중심의데이터 웨어하우스데이터 마트내 대부분의데이터는데이터 웨어하우스로부터복제또는자체적으로 수집 가능관계형 데이터 베이스나다차원 데이터 베이스를 이용하여 구축
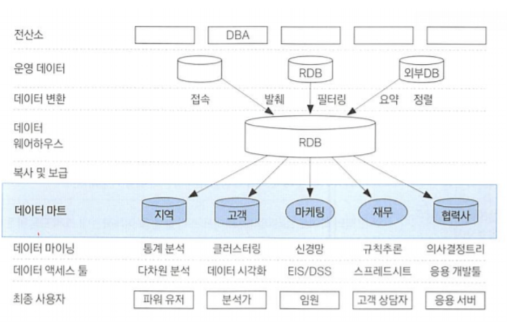
CRM관련 업무 중핵심-고객데이터 마트 구축- 동일한 데이터 셋을 활용할 경우, 최신 분석기법 이용시 분석가의 역량에서 분석 효과가 크게 차이 나지 않음
->데이터 마트를 어떻게 구축하느냐에 따라분석 효과 차이
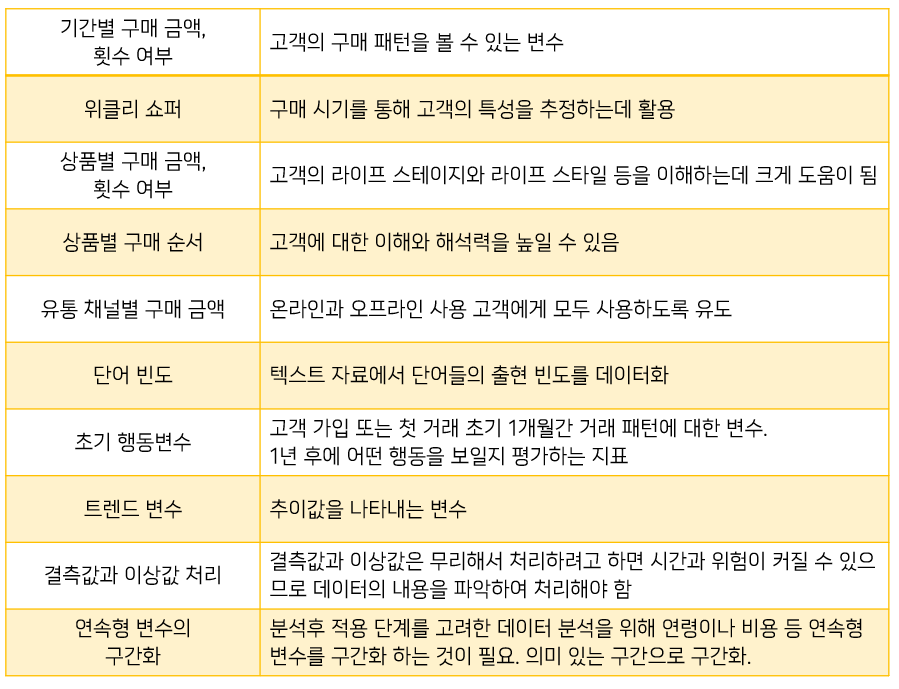
요약변수
수집된 정보를분석에 맞게종합한 변수- 데이터 마트에서
가장 기본적인 변수
ex)총 구매 금액,금액,횟수,구매 여부등데이터 분석을 위해 만들어지는 변수 - 많은 모델에 공통으로 사용되어
재활용성이 높음 - 합계, 횟수와 같이
간단한 구조이므로자동화하여 상황에 맞게일반적인 자동화 프로그램으로구축 가능 단점:얼마 이상이면 구매하더라도기준값의 의미 해석이애매
->연속형 변수를그룹핑해서 사용하면 좋음.
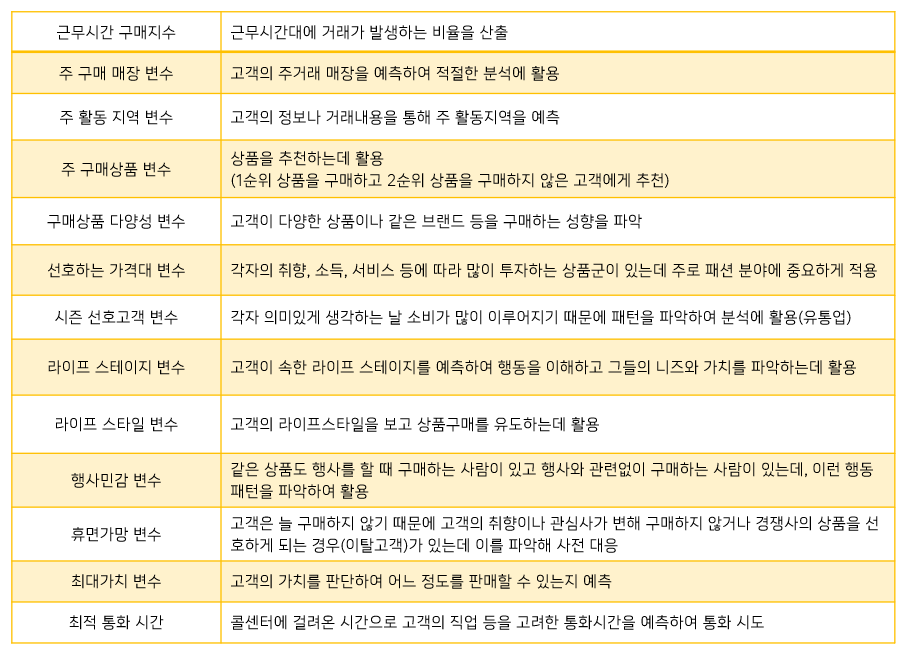
파생변수
사용자(분석자)가특정 조건을만족하거나특정 함수에 의해값을 만들어 의미를 부여한 변수- 매우
주관적일 수 있으므로논리적 타당성을 갖추어 개발 세분화,고객행동 예측,캠페인 반응 예측에 활용특정 상황에만유의미하지 않게대표성을 나타나게해야함
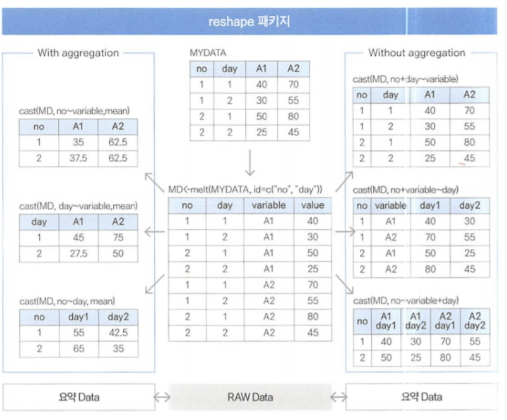
reshape의 활용
melt()-원데이터 형태로 만드는 함수와cast()-요약 형태로 만드는 함수라는 2개의 핵심 함수
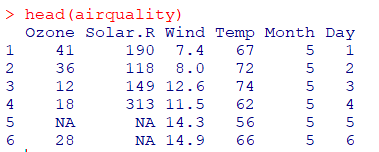
ex)melt를 이용해 airquality 데이터의 month, id를 기준으로 모든 데이터를표준 형식으로 변환변수를 조합해변수명을 만들고, 변수들을시간,상품등의 차원에 결합해 다양한요약변수와파생변수를 쉽게 생성하여데이터마트구성
- ex)
airquality data
melt함수 : 쉬운 casting을 위해 적당한 형태로 만들어주는 함수melt(data,id=...)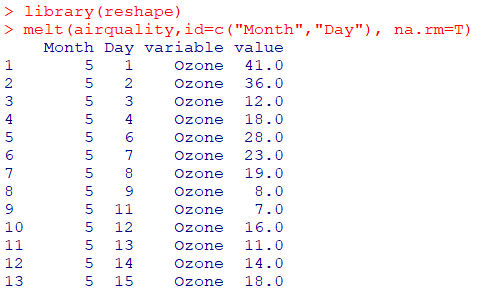
cast 함수 : 데이터를 원하는 형태로 계산 또는 변형 시켜주는 함수cast(data, formula=...~variable,fun) cast(aqm,Day~Month~variable) #Day : 행, Month : 열, variable : 값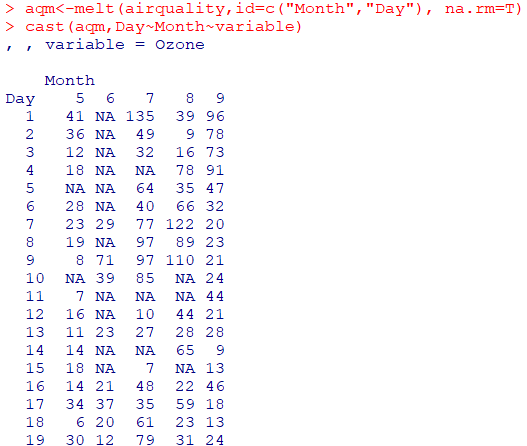
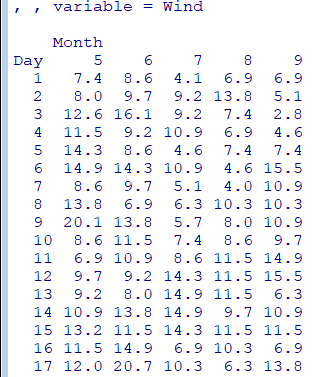
sqldf를 이용한 데이터 분석
R에서sql명령어를 사용 가능하게 해주는 패키지SAS에서PROC SQL과 같은 역할
select * from [data frame]
sqldf("select * from [data frame]")
select * from [data frame] numrows 10
sqldf("select * from [data frame] limit 10")
select * from [data frame] where [col]='char%'
sqldf ("select * from [data frame] where [col] like 'char%'")head([df]) :
sqldf("select * from [df] limit6")
subset([df],grep1("qn%",[col]) :
sqldf("select * from [df] where [col] like 'qn%'")
subset([df],[col] %in% c("BF","HF") :
sqldf("select * from [df] where [col] in ('BF','HF')")
rbind([df1],[df2]) :
sqldf("select * from [df1] union all select * from [df2]")
merge([df1],[df2]) :
sqldf("select * from [df1],[df2]")
df[order([df]$[col], decreasing=T),] :
sqldf("select * from [df] order by [col] desc")iris데이터 예시
plyr을 이용한 데이터 분석
apply함수에 기반해데이터와출력변수를동시에 배열로 치환하여 처리하는 패키지split-apply-combine: 데이터를분리하고처리한 다음, 다시결합하는 등 필수적인 데이터 처리 기능 제공
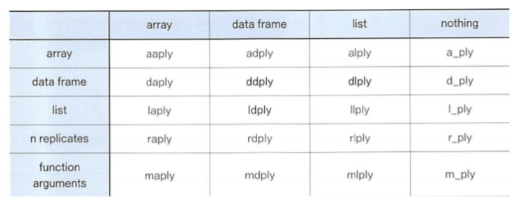
- ex)
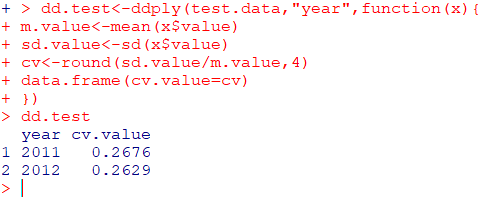
test.data생성
test.data를 이용해sd와mean의 비율인변동계수 CV산출
데이터 테이블
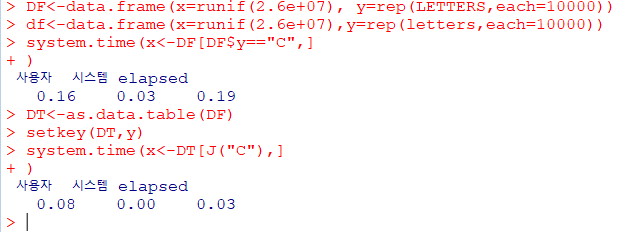
data.table패키지는R에서가장 많이 사용하는데이터 핸들링 패키지큰 데이터를탐색, 연산, 병합하는 데 아주 유용- 기존
data.frame보다월등히 빠른 속도 - 특정 Column을
Key값으로색인을 지정한 후 데이터 처리 빠른 그룹핑과Ordering,짧은 문장 지원측면에서 데이터 프레임보다 유용
rep(LETTERS, each=10000)): 대문자 알파벳을 A부터 각각 10000번씩 출력rep(letters, each=10000)): 소문자 알파벳을 a부터 각각 10000번씩출력
🧶데이터 가공
Data Exploration
데이터 분석을 위해 구성된데이터의변수들의상태 파악
종류
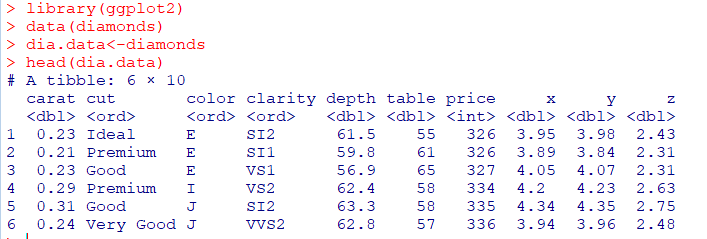
head(데이터셋),tail(데이터셋)
:시작또는마지막 6개record만 조회
summary(데이터셋)수치형 변수:최댓값,최솟값,평균,1사분위수,2사분위수(중앙값),3사분위수명목형 변수(변수 값이 고유한 순위가 없는 범주를 나타내는 경우. ex)성별(남,녀)/혈액형(AB,A,B,O):명목값,데이터 개수
변수 중요도
변수 선택법과 유사한 개념모형을 생성하여사용된 변수의중요도를 살피는 과정
종류
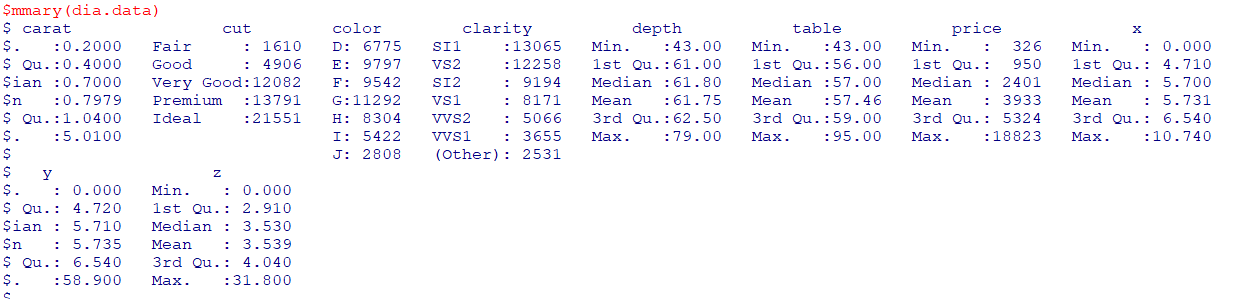
klaR 패키지특정 변수가 주어졌을 때클래스가어떻게 분류되는지에 대한에러율을 계산해주고,그래픽으로 결과를 보여주는 기능greedy.wilks()
:세분화를 위한stepwise forward 변수선택을 위한 패키지종속변수에가장 영향력을 미치는 변수를wilks lambda를 활용해 변수의중요도 정리(Wilk's Lambda=집단내분산/총분산)

*lda : 선형판별분석
*x=iris[,4] : iris 데이터셋의 4번째 열인 Petal_width
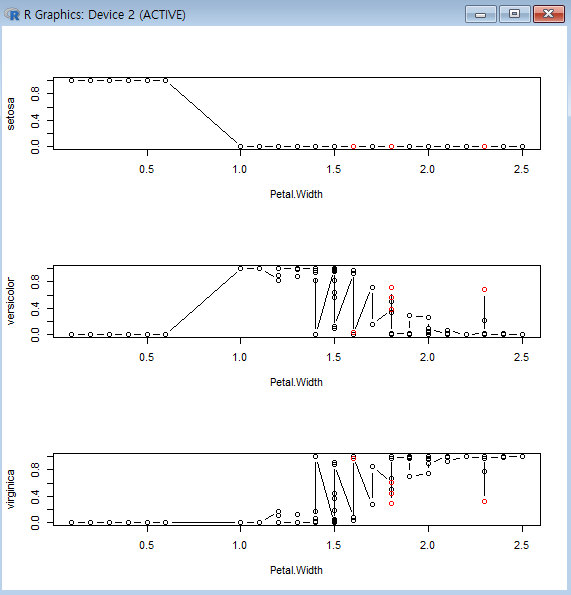
변수의 구간화
연속형 변수를분석 목적에 맞게 활용하기 위해구간화하여 모델링에 적용
-> 일반적으로10진수 단위로 구간화.
-> 구간을5개로 나누는 것이 보통, 7개 이상의 구간 잘 안 만듦
ex)신용평가모형,고객 세분화와 같은시스템에서 모형에 활용하는 각 변수들을구간화해서구간별로점수를 적용하는스코어링 방식으로 활용
구간화 방법
Binning
신용평가모형의 개발에서연속형 변수(부채비율)를범주형 변수로 구간화하는데 활용
ex)연속형 변수를오름차순 정렬후 각각 동일한 개수의 레코드를50개의깡통(bin)에 나누어 담고 각 깡통의부실율을 기준으로 병합해서 최종5~7개의 깡통으로 부실율의 역전이 생기지 않게 합치면서 구간화.
아래는 5개의 Bin으로 구간화
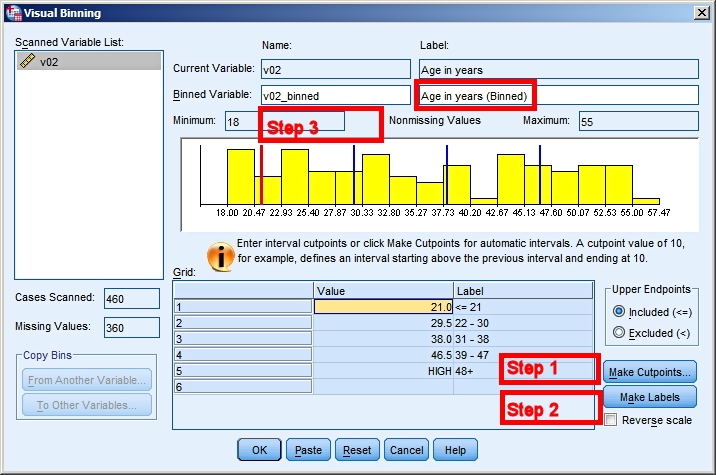
의사결정나무
세분화또는예측에 활용되는의사결정나무 모형을 사용하여입력변수를 구간화동일한 변수를 여러 번의분리 기준으로 사용 가능하여,연속 변수가반복적으로 선택될 경우, 각각의분리 기준값으로연속형 변수를 구간화가능
🎶기초 분석 및 데이터 관리
데이터 EDA(탐색적 자료 분석)
- 데이터의 분석에 앞서
전체적으로데이터의 특징을 파악하고 데이터를다양한 각도로 접근 summary()를 이용하여 데이터의기초통계량확인
결측값 인식
결측값
:NA,99999999,' '(공백),Unknown,Not Answer등으로 표현- 결측값을 처리하기 위해
시간을 많이 사용하는 것은비효율적 결측값 자체가의미있는 경우존재
ex) 쇼핑몰 가입자 중 특정 거래 자체가 존재하지 않는 경우,
인구통계학적 데이터에서 아주 부자이거나 아주 가난한 경우 자신의 정보를 잘 채워넣지 않기 때문에가입자의 특성을 유추하여활용결측값 처리는전체 작업속도에 많은영향na.rm을 이용해NA 제거

결측값 처리 방법
단순 대치법(Simple Imputation)
Completes Analysis
결측값이 존재하는레코드 삭제
평균대치법(Mean Imputation)
관측또는실험을 통해 얻어진데이터의 평균으로 대치비조건부 평균 대치법:관측데이터의평균으로 대치조건부 평균 대치법(Regression Imputation):회귀분석을 활용한 대치법
단순확률 대치법(Single Stochastic Imputation)
평균대치법에서추정량 표준 오차의과소 추정문제를 보완하고자 고안된 방법Hot deck방법,Nearest Neighbor방법
다중 대치법(Multiple Imputation)
단순대치법을한 번만하지 않고m번의 대치를 통해m개의 가상적 완전 자료를 만드는 방법- 1단계 :
대치(Imputation Step)
2단계 :분석(Analysis Step)
3단계 :결합(Combination Step) Amelia
:time series cross sectional data set(여러 국가에서 매년 측정된 자료)에서Bootstrapping Based Algorithm을 활용한다중 대치법
R에서 결측값 처리
complete.cases()
- 데이터 내 레코드에
결측값이 있으면 FALSE,없으면 TRUE

is.na()
- 결측값을
NA로 인식하여결측값이 있으면 TRUE,없으면 FALSE

DMwR 패키지의 centralImputation()
NA 값에가운데 값(Central Value)로 대치숫자는중위수,요인은최빈값으로 대치- 이제 CRAN에서 DMwR 패키지 지원X
DMwR 패키지의 knnImputation()
NA값을KNN알고리즘을 사용해 대치k개 주변 이웃까지 거리를 고려해가중 평균한 값사용
Amelia 패키지의 amelia()
time series cross sectional data set(여러 국가에서 매년 측정된 자료)에서 활용
*랜덤포레스트(Random Forest)모델은 결측값 존재시 바로에러randomForest패키지의rfImpute() 함수를 활용해NA결측값대치 후 알고리즘에 적용
na.omit(데이터프레임)
이상값(Outlier)인식과 처리
이상값이란?
의도하지 않게 잘못 입력한 경우(Bad Data)- 의도하지 않게 입력되었으나
분석 목적에 부합되지 않아제거해야하는 경우(Bad Data) 의도하지 않은 현상이지만분석에 포함해야 하는 경우의도된 이상값(Fraud,불량)인 경우- 이상값을 꼭 제거해야 하는 것은 X
분석의 목적이나종류에 따라 적절한 판단 필요
ex)사기 탐지, 의료(특정환자에게 보이는예외적인 증세),네트워크 침입탐지등
이상값의 인식 방법
ESD(Extreme Studentized Deviation)
평균으로부터3 표준편차 떨어진 값(각0.15%)99.7%에서0.3%남으니 0.3%반은 각각0.15%
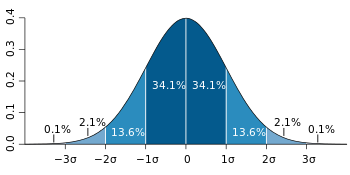
기하평균-2.5x표준편차 < data < 기하평균+2.5x표준편차
기하평균=n√a1xa2x...xan
사분위수이용해 제거(상자그림의outer fence밖에 있는 값 제거)
Q1-1.5(Q3-Q1)<data<Q3+1.5(Q3-Q1)를 벗어나는 데이터IQR(Q3-Q1): 자료 집합의50%에 포함되는 자료의 산포도Q1: 데이터 25%가 이 값보다 작거나 같음Q2: 데이터의 절반(중앙값)Q3: 데이터의 75%가 이 값보다 작거나 같음
극단값 절단(Trimming) 방법
기하평균을 이용한 제거
geo_mean
하단, 상단 % 이용한 제거
10% 절단(상하위 5%데이터 제거)
극단값 조정(Winsorizing) 방법
상한값과하한값을 벗어나는 값들을하한, 상한값으로 바꾸어 활용
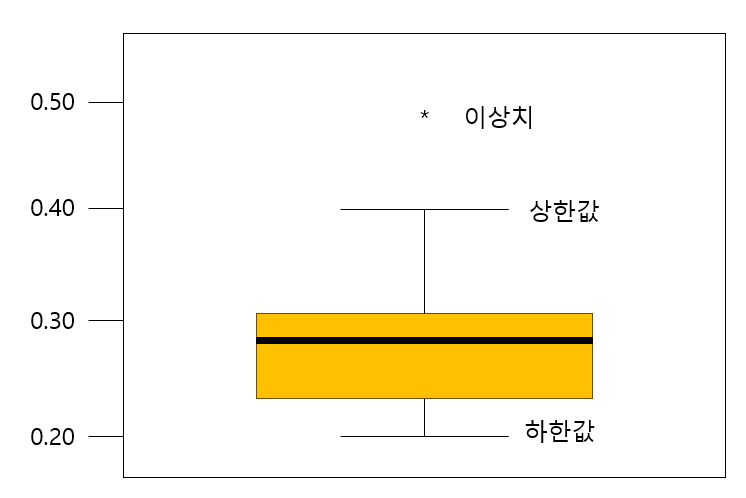
- ex)
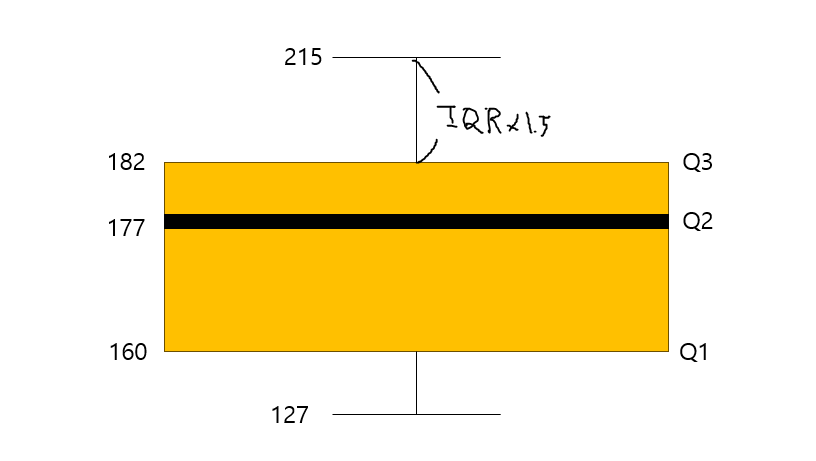
상자수염그림(Box Plot을 통한 예시)
IQR(182-160)은22
IQRx1.5는33이며160-33=127이 하한선,182+33=215가 상한선, 이를 넘어갈 경우 이상점

MSSQL DBA 신입

항상 좋은 글 감사합니다.