
📆개발 시기
2021.03.20.-2021.06.01.
📝개발 목적
범죄 예방을 위해 사용하고 있는 CCTV를 관리할 인력이 부족하여
이를 해결하기 위하여 인공지능이 폭력행위를 감지할 수 있도록
인공지능을 모델링 및 학습시키고,
실제 환경에 바로 적용할 수 있는 인공지능 개발하였다
📕이론
이상행동 감지 전체 블록도
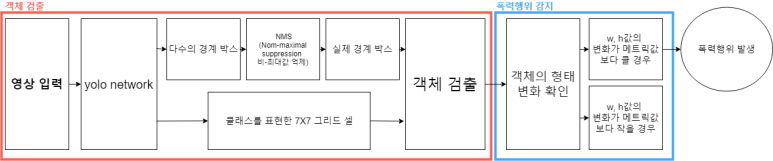
영상이 yolo network로 전달되면 다수의 경계박스와
그리드 셀을 통해서 값을 얻어 이를 객체로 검출한다.
YOLO를 학습시키기 위해 학습과 트레이닝 데이터를 정의하는 data 파일,
CNN 레이어의 구조를 정의하는 cfg파일,
학습시킨 가중치 정보가 들어있는 weights 파일 세 가지가 필요하다.
YOLO에서는 기본적인 객체검출에 대한 cfg파일과 weights 파일을 제공한다.
이를 활용할 수도 있지만 우리는 화질이 낮거나 어두운 골목에서
더 정확한 객체 인식을 원했기에 이에 대한 학습 데이터셋을 통해
객체 인식을 학습한 후 폭력행위에 대한 학습도 진행하였다.
객체 검출 및 폭력행위 인식 블록도

학습된 인공지능에게 영상을 틀어주면 YOLO network가 인식하여
다수의 경계박스와 NMS 실제 경계 박스를 통해 객체 검출과
폭력인식을 하거나 클래스를 표현한 7X7 그리드 셀을 통해 객체 검출 및 폭력인식을 한다.
폭력과 객체는 각각 fight와 person으로 정확도와 함께
영상에 네모 박스로 띄워서 확인이 가능하다.
🔍실험 환경
Windows 10
OpenCV
Visual Studio
Cuda 10.1
NVIDIA GeForce GTX 660📃실험 셋팅
Yolo v3를 이용해 학습시키기 전 세팅해야할 부분이 있다.
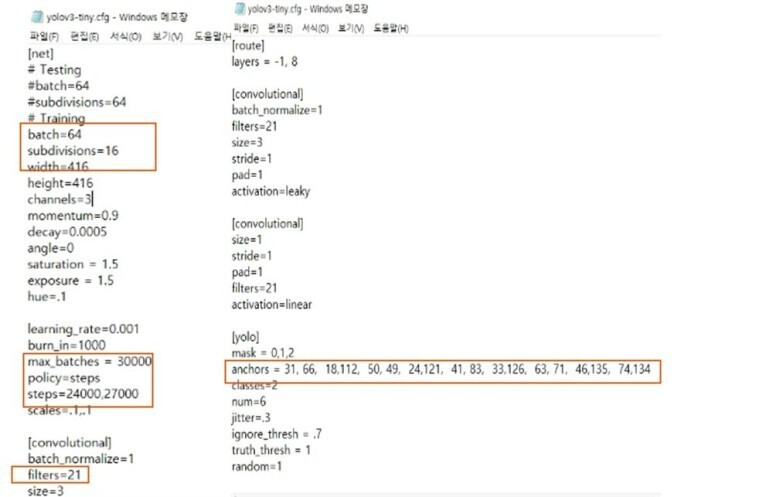
classes : 데이터 종류의 수, fight와 person 2개로 설정
max_batches : 4000 x classes의 개수
steps : 위에서 설정한 max_batches 사이즈의 80%와 90%를 설정
💻라벨링
Yolo-mark 를 이용하여 라벨링을 수행한다.
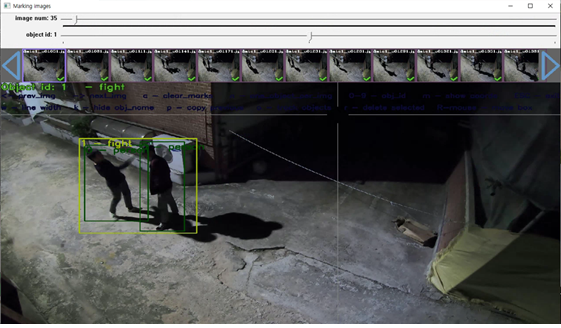
yolo – mark를 통해 실내외 사람 객체와 폭력행위 장면을 라벨링하여
YOLO가 학습할 수 있는 data인 txt파일로 만들어 준다.
이와 같은 데이터셋을 실내외 합쳐 1600장을 라벨링 하였고 이를 학습한다.
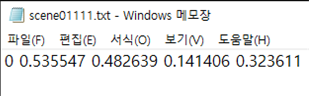
라벨링을 수행하게 되면 위의 사진과 같이 txt에 숫자가 있다.
📌학습
cmd에서 영상을 입력하여 출력결과를 확인할 수 있는 명령어는 다음과 같다.
>> darknet.exe detector demo data/obj.data testcfg/yolov3-tiny.cfg backup/yolov3-tiny_final.weights -i 0 data\fight\data2.mp4
>> darknet.exe detector demo data/obj.data testcfg/yolov3-tiny.cfg backup/yolov3-tiny_final.weights -i 0 (확인할 동영상 파일)추가로 학습을 원하는 경우는 다음과 같이 입력한다.
darknet detector train data\obj.data testcfg\yolov3-tiny.cfg backup/yolov3-tiny_final.weights -gpu 0📰출력 결과
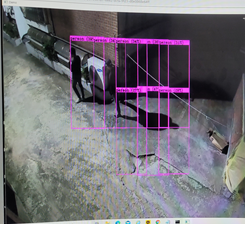
2000회를 학습 한 후 객체 검출의 결과는 위와 같다.
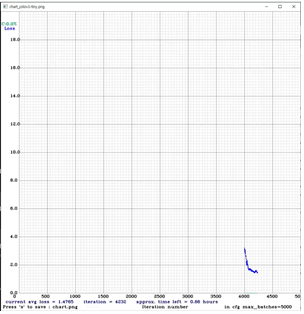
5000번대 손실률 그래프는 위와 같다.


📂고찰
최종적으로 person 객체와 fight라는 폭력행위를 검출한 결과는 다음과 같은 출력을 보인다.
첫번째 사진은 실내 폭력행위 영상을 입력 data로 집어넣어 객체는 34%, 37%의 정확도를 보이고
폭력행위는 55%의 정확도를 보이며 폭력행위라는 출력을 화면상에 그려준다.
두번째 사진은 실외 폭력행위 영상을 입력 data로 집어넣어 객체를 40%, 53%의 정확도로 검출하고
폭력행위는 38%의 정확도로 확인하여 출력으로 나타난다.
🧸담당 역할
- Darknet Windows 10 환경 구축
- Yolo v3 학습 전 classes 수와 max_batches, steps 값 수정
- 폭력행위 영상에서 이미지를 추출
- 1600장의 사진을 Yolo-mark로 라벨링
- 정확도를 위하여 30000번 학습
📚참고문헌
[1] https://www.index.go.kr/potal/main/EachDtlPageDetail.do?idx_cd=2855
[2] CCTV 통합관제센터 운영실태 및 개선방안, p32
[3] Girshick, R., Donahue, J., Darrell, T. and Malik, J., Rich feature hierarchies for accurate object detection and semantic segmentation. CVPR, pp.580-587, 2014.
[4] Girshick, R. Fast r-cnn, ICCV, pp.1440-1448, 2015.
[5] Ren, S., He, K., Girshick, R., & Sun, J., Faster rcnn: Towards real-time object detection with region proposal networks, NIPS, pp.91-99, 2015.
[6] https://jjjhong.tistory.com/25
[8] http://www.dbpia.co.kr/journal/articleDetail?nodeId=NODE06281351
[9] http://daddynkidsmakers.blogspot.com/2020/05/yolo.html
데이터 제공 : https://aihub.or.kr/aidata/139
