📔설명
숫자형, 문자형 컬럼 인덱스를 range scan하는 방법을 알아보고, 중복된 데이터가 있는 컬럼의 인덱스 range scan 방법을 알아보자
🍔INDEX SCAN
| 인덱스 액세스 방법 | 힌트 |
|---|---|
| index range scan | index |
| index unique scan | index |
| index skip scan | index_ss |
| index full scan | index_fs |
| index fast full scan | index_ffs |
| index merge scan | and_equal |
| index bitmap merge scan | index_combine |
🧇숫자형 컬럼 INDEX RANGE SCAN
select ename, sal
from emp
where sal=1600;
--명시
select /*+ index(emp emp_sal) */ ename, sal
from emp
where sal=1600;
에서 sal이 1600인 데이터를 읽을때, emp_sal인덱스에서 찾는다.
sal 순으로 정렬되어있지만, 만약 1600을 찾았다 해도, 한 번 더 읽는다
왜냐하면 또 그 다음 1600일 수 있기 때문이다.
create index emp_sal on emp(sal);
select /*+ gather_plan_statistics */ ename, sal
from emp
where sal=1600;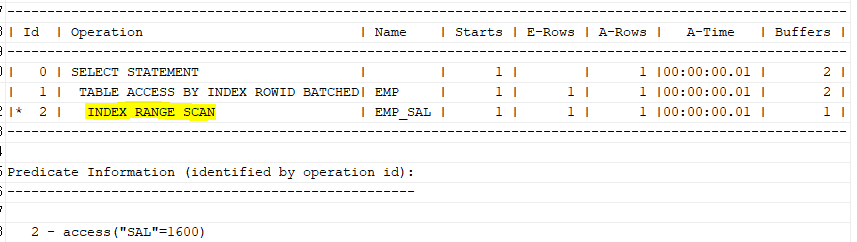
🍠문자형 컬럼 INDEX RANGE SCAN
select ename, sal
from emp
where ename='SCOTT';
--명시
select /*+ index(emp emp_ename) */ ename, sal
from emp
where ename='SCOTT';unique제약이 걸려있는 것이 아니기 때문에, 중복된 데이터가 ename에 올 수 있어 range scan으로 읽게 된다.
create index emp_ename on emp(ename);
select /*+ gather_plan_statistics */ ename, sal
from emp
where ename='SCOTT';
select * from table(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));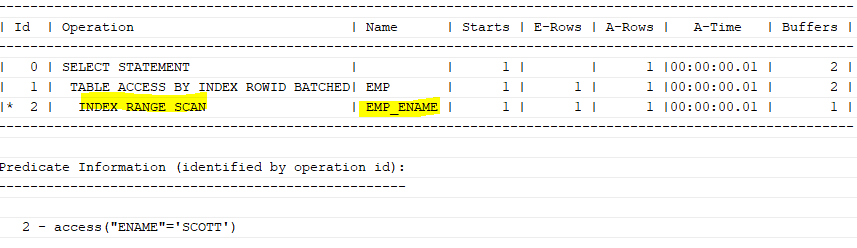
🧉중복된 데이터가 있는 컬럼 INDEX RANGE SCAN
select ename, sal
from emp
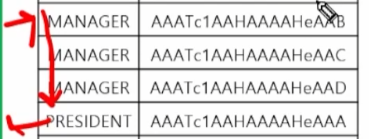
where job='MANAGER';job은 유니크 제약을 걸 수도 없다.
select job, rowid
from emp
where job>' ';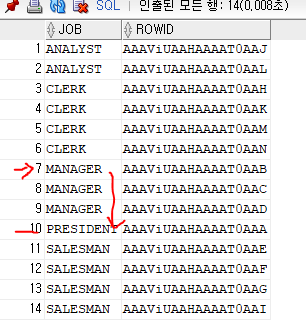
그러므로 emp_job 인덱스에서 manager 직업인 것들을 읽고, 그 다음까지 읽어보는 range scan을 한다.
create index emp_job on emp(job);
select /*+ gather_plan_statistics */ ename, sal
from emp
where job='MANAGER';
select * from table(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));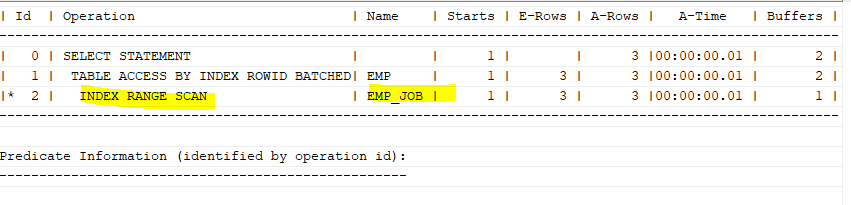

MSSQL DBA 신입