📔설명
소트 연산의 종류와 동작 원리에 대해 알아보고 소트 연산을 피하고 부하를 줄여보자!
✨소트 연산의 종류
Order by(Sort Order by)
select *
from emp
order by deptno;
Group by(Sort Group by/Hash Group by)
group by명령과order by명령을 SQL문에 동시에 사용 시
select deptno, sum(sal+nvl(comm,0))
from emp
group by deptno
order by deptno;
select /*+ gather_plan_statistics */ deptno, sum(sal+nvl(comm,0))
from emp
group by deptno;
- group by 만을 수행할 땐
HASH GROUP BY연산으로 수행 - 정렬 연산을 하지 않고 해시 알고리즘으로 group by 수행
- 오라클은 ORDER BY 절 외에는 정렬 보장 X
Distinct, IN, UNION, MINUS, INTERSECT 등
Sort Unique연산과Hash Unique연산을 발생
select /*+ gather_plan_statistics */ *
from dept
where deptno in (select deptno from emp);IN절에 의해Sort Unique 연산발생- 그러므로 IN절은 비효율 유발
select /*+ gather_plan_statistics */ *
from emp
where mgr=7839
union
select *
from emp
where mgr=7566;
- 집합 연산자 union, minus, intersect 사용시
SORT UNIQUE발생 - 중복 제거된 합집합을 만들기 위함
select /*+ gather_plan_statistics */ distinct job
from emp;
HASH UNIQUE연산 사용 시 정렬 발생 X
select /*+ gather_plan_statistics */ distinct job
from emp
order by job;
- 정렬을 하기 때문에 SORT UNIQUE 연산이 나와있다.
윈도우 함수(Window Sort)
select /*+ gather_plan_statistics */ empno, ename, job, sal,
rank() over(partition by job order by sal desc)
from emp;
Sort Aggregate 연산
- 실제로는 정렬을 하지 않음
select /*+ gather_plan_statistics */ count(*), sum(sal), max(hiredate), min(hiredate)
from emp;
🎫인덱스를 이용한 소트 대체
Sort Order by
create index emp_x01 on emp(deptno);
select /*+ gather_plan_statistics */ *
from emp
order by deptno;
인덱스를 만들었으나, 테이블을 접근해 SORT ORDER BY 연산이 발생한다.
index(emp emp_x01)로 힌트롤 줘도 똑같다.
왜냐하면 emp 테이블의 deptno 컬럼은 NULL이 존재할 수 있기 때문이다.
select /*+ gather_plan_statistics */ *
from emp
where deptno is not null
order by deptno;
NULL 데이터를 결과 집합에 포함시키지 않아도 된다면 위의 방법을 사용하면 된다.
Sort Group by
select /*+ gather_plan_statistics */ deptno, sum(sal+nvl(comm,0))
from emp
group by deptno;
정렬은 발생하지 않았으나, hash group by 연산이 발생했다.
order by 와 마찬가지로 not null을 넣어보자.
select /*+ gather_plan_statistics */ deptno, sum(sal+nvl(comm,0))
from emp
where deptno is not null
group by deptno;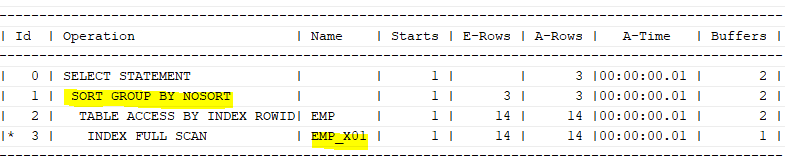
인덱스를 스캔하면서, 같은 값으로 집계를 하였기 때문에 sort group by 연산을 사용하며 sort를 하지 않았기 때문에 nosort가 나온다.
🛒불필요한 소트 제거
집합 연산자
SORT UNIQUE피하기- 중복의 결과가 발생하지 않는다면,
union all연산자를 사용
IN절 안의 서브쿼리
SORT UNIQUE피하기- IN절을
EXISTS로 변경시, 해당 컬럼으로 인덱스를 사용 (사용 X시 무조건 성능 개선 X)
unnest는 서브 쿼리를 풀어 from절과 조인
🎇소트 영역 적게 사용하기
소트 영역은 로우 개수와 함께 컬럼들의 최종 길이 함께 결정
=> 가로 길이(컬럼 수)와 세로 길이(로우 수)가 함께 결정
SELECT절에 있는컬럼의 수가소트 영역을 정하는 데 영향을 미침
페이징 기법
: 사람이 볼 수 있을 만큼 적당히 나눠서 보여주는 기법
select a.*
from ( select rownum rn, a.*
from ( select *
from emp_100000 --emp 테이블을 10만배 복사
order by ename desc) a
) a
where a.rn between 1 and 10;위 처럼 쿼리를 작성하면, sort order by도 발생하며 디스크에서 정렬을 수행하게 된다.
select a.*
from ( select rownum rn, a.*
from ( select *
from emp_100000 --emp 테이블을 10만배 복사
order by ename desc) a
where rownum<=10
) a
where a.rn >=1;where rownum<=10을 통해 소트 영역을 적게 잡아두고 정렬을 수행하였다.
해당 쿼리로 인해 정렬에 필요한 메모리 공간으로 10개만 지정하고 그 안에서 정렬을 수행하는 것이다.
이때 count stopkey 가 실행계획에 나타나게 된다.
COUNT STOPKEY 원리
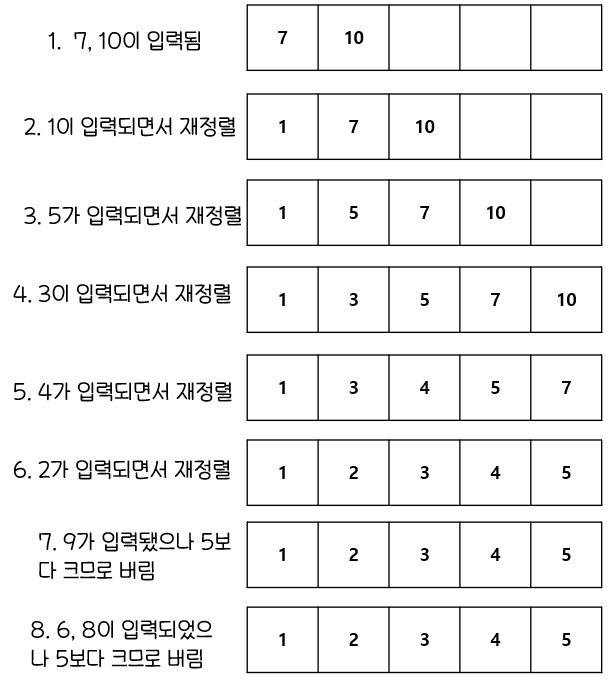
6번에서 이미 정렬되었으나, 오라클은 어떤 데이터가 입력될 지 모르기 때문에 멈추지 않는다.
