📔설명
NL조인, 소트 머지 조인, 해시 조인에 대해 알아보자!
🍔NL 조인
- 두 테이블을 조인할 때,
드라이빙 테이블(Outer 테이블)에서 읽은 결과를Inner 테이블로건건이 조인 시도 - 중첩된 반복
for(i=0; i<I_MAX;i++){
for(j=0; j<J_MAX;j++){
...
}
}
-- ordered : from절에 나열된 순서대로 테이블 읽음
-- use_nl(테이블명) : nl조인을 사용
select /*+ gather_plan_statistics ordered use_nl(e) */ *
from dept d, emp e
where 1=1
and d.deptno=e.deptno;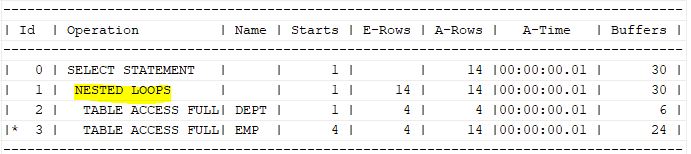
dept 테이블에서 데이터를 한 건 읽어서 emp 테이블로 조인을 시도하고, 이것을 계속 반복
select /*+ ordered use_nl(b) */ a.*, b.*
from item a, uitem b
where a.item_id=b.item_id
and a.item_type_cd='100100'
and a.sale_yn='Y'
and b.sale_yn='Y';
-- 인덱스 : ITEM_TYPE_CD (item_x01)
-- 인덱스 : ITEM_ID+UITEM_ID (uitem pk)- 위는
ordered힌트로 인해item테이블을 먼저 읽는다. - item의 인덱스
item_x01을 이용해 a.item_type_cd='100100'의 데이터를 추출한다. - 추출된 데이터를 이용해 a.sale_yn='Y'에 해당하는 데이터를
최종 드라이빙 데이터로 만든다. - uitem 테이블과 조인 조건인 a.item_id=b.item_id 구문을 수행한다. (uitem pk 인덱스 이용)
- 조인에 성공시 B.sale_yn='Y'에 해당하는 데이터를 최종 결과 집합으로 추출한다.
위의 경우는 item_type_cd+sale_yn 인덱스와, item_id+sale_yn으로 인덱스를 구성하는 것이 더 이득일 수 있다.
- NL조인은 한 건씩 처리하므로
중간에 멈추는 경우이득
🎨소트 머지 조인
- 두 테이블을 각각
조건에 맞게 먼저 읽은 후, 두 테이블을조인 컬럼을 기준으로정렬후 조인 수행 - 오라클은 정렬을
PGA에서 수행하는데 PGA는프로세스에 할당된 독립된 공간이므로버퍼 캐시(SGA)를 사용하는NL조인에 비해 더 빠름
select /*+ gather_plan_statistics ordered use_merge(e) */ *
from dept d, emp e
where 1=1
and d.deptno=e.deptno;
먼저 dept 테이블을 조인 컬럼 기준으로 정렬한다.
emp 테이블을 그 후 조인 컬럼 기준으로 정렬한다.
그 다음 두 테이블을 조인한다.
이 때, 첫번째 조인 시도 후 두번째부터는 첫 번째 시도한 만큼의 데이터는 조인 시도를 하지 않는다.
- 조인으로 인한
랜덤 액세스 부하 없음
select /*+ ordered use_merge(b) */ a.*, b.*
from item a, uitem b
where a.item_id=b.item_id
and a.item_type_cd='100100'
and a.sale_yn='Y'
and b.sale_yn='Y';
-- 인덱스 : item_type_cd (item_x01)ordered힌트에 의해item테이블을 먼저 읽는다.- item_x01 인덱스를 사용해 a.item_type_cd='100101'을 추출한다.
- 추출된 데이터를 가지고 테이블로 이동해 a.sale_yn='Y'에 해당하는 데이터를 최종 추출 데이터로 만든다.
- item에서 최종적으로 추출된 데이터를
조인 컬럼인 a.item_id를 기준으로정렬 - uitem은 인덱스가 없기 때문에
테이블 전체를 읽으며 b.sale_yn='Y'인 데이터를 최종 추출 데이터로 만든다. - uitem 최종 추출 데이터를 b.item_id컬럼 기준으로
정렬 - 조인 조건인 a.item_id=b.item_id 조건을 수행한다.
위의 경우 item_type_cd+sale_yn+item_id 인덱스와 sale_yn+item_id 로 인덱스를 구성하는 것이 이득이다.
랜덤 액세스를 줄일 수 있을 뿐더러 정렬을 대신할 인덱스가 있으면 정렬 부하를 줄일 수 있다.
🥾해시 조인
해시 맵을 만들 때 두 테이블 중작은 테이블을 읽음- 큰 테이블을 읽어 해시 함수를 통해
해시 버킷을 찾아가 실제 데이터를 찾음 - 작은 테이블을
Build Input - 큰 테이블을
Probe Input - 해시 맵에는
조인 컬럼과SELECT절에서 사용한 컬럼까지 포함
select /*+ gather_plan_statistics ordered use_hash(e) */ *
from dept d, emp e
where 1=1
and d.deptno=e.deptno;
dept 테이블을 먼저 읽어 Build Input으로 선택해 해시 맵을 만들고 조인을 시도한다.
- 사용자가
Build Input을 선택하기 위해선SWAP_JOIN_INPUTS(테이블명)힌트를 사용해야 함
select /*+ gather_plan_statistics ordered use_hash(e) swap_join_inputs(e) */ *
from dept d, emp e
where 1=1
and d.deptno=e.deptno;
Build Input이 커지면, PGA내 해시 영역 안에 적재가 힘들어 결국디스크 공간을 사용하게 되므로 해시 조인의 성능이 떨어지게 된다.
👜조인 방식별 특징
NL 조인
- 중간에 멈출 수 있음
- 랜덤 액세스 부하가 매우 높음
- 온라인 트랜잭션이 많고, 부분범위처리(주로 페이징)가 가능할 경우
- 각 테이블의 데이터는 많으나 추출 대상이 되는 데이터 양이 많지 않을 경우
소트 머지 조인
Outer 테이블에정렬을 대신할 인덱스/(Group by/Order by 등의) 인라인 뷰가 있다면 정렬 시도 XInner 테이블의크기가 작다면 정렬에 대한 부담 줄어듦- 첫 번째 테이블에 조인 컬럼 기준으로 인덱스가 있어 정렬 부하가 발생하지 않는 경우
- Group by 또는 Order by 등 이미 정렬한 서브 쿼리와 조인 시도 시 두 번째 테이블의 양이 작을 경우
- 테이블 양이 매우 커서 NL조인이 힘들고, 등치 조인이 아니어서 해시 조인이 힘들 경우
해시 조인
등치(=)조건으로 가능- 조인 키 값의 Distinct Value 수와 전체 값의 수가 차이가 많이 나면 성능 저하
조인 컬럼 값에중복 값이 적거나where절에조인 컬럼으로값을 걸러내는 필터 조건이 없어야 함
ex) B테이블이 Build Input인데 where절에 b.key='30'으로 조건절이 있으면 하나의 버킷에 해시 체인이 연결됨- 대용량 테이블 조인 시도시 조인 컬럼에 인덱스가 없어 NL조인이 힘든 경우
- 조인 컬럼에 인덱스가 있으나, 드라이빙 테이블의 결과 건수가 많아 Inner 테이블로 많은 양의 랜덤 액세스 발생 시
- 두 테이블 양이 많아 소트 머지 조인 시도 시 정렬 부하가 클 경우
🎡조인 방식에 따른 인덱스 설계
select a.*, b.*
from item a, uitem b
where a.item_id=b.item_id
and a.item_type_cd='100100'
and a.sale_yn='Y'
and b.sale_yn='Y';
--조인 방향 : item->uitemNL 조인
- item은 드라이빙 테이블이므로, 조인 컬럼을 만약 인덱스에 추가시 뒤에 배치 (필터 후 조인하기 때문)
item_type_cd+sale_yn또는 그 반대로 인덱스 구성- 조인 컬럼을 인덱스에 추가시
테이블 방문이 사라진다면, 인덱스에 추가 - 조인 컬럼 추가시
테이블 방문한다면 인덱스에 조인 컬럼 추가 X - uitem은 inner 테이블으로
NL조인의 핵심인INNER 테이블에조인 컬럼이 반드시 인덱스로 존재해야 함 item_id+sale_yn또는 반대로 인덱스를 구성
소트 머지 조인
- 각 테이블에서 조인 컬럼으로 정렬이 발생함
- item 테이블은
item_type_cd+sale_yn또는 그 반대로 구성 - 정렬을 대신하기 위해
item_id를 위의 인덱스에 추가로 구성해item_type_cd+sale_yn+item_id로 인덱스를 구성 - uitem 테이블도 마찬가지로 조인 컬럼을 인덱스에 추가해 정렬을 대신
- uitem 테이블은
sale_yn+item_id로 만들어야 함 (그 반대로 구성시 인덱스 풀 스캔이 발생하게 됨)
해시 조인
- item 테이블엔
item_type_cd+sale_yn또는 그 반대로 인덱스 생성 - uitem 테이블은
sale_yn만으로 구성 - 해시 조인은
조인 컬럼이 인덱스에 포함되지 않아도 성능에 문제 없음 - 다만 조인 컬럼이 인덱스에 포함됨으로써 테이블로의 방문을 막을 수 있으면 고려
🎨Outer 조인
Outer NL 조인
NL조인의 특성상 Outer 조인 시, 조인 방향이한쪽으로 고정Outer 기호(+)가 붙지 않은테이블을 항상드라이빙 테이블
select /*+ gather_plan_statistics leading(d) use_nl(e) */ *
from dept d, emp e
where d.deptno=e.deptno(+);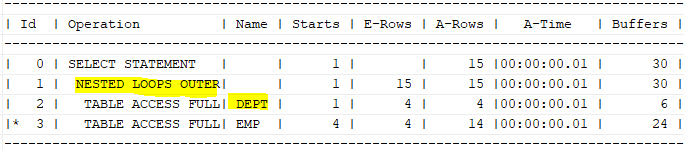
Outer 소트 머지 조인
- 각 테이블의 조인 대상 집합을 정렬한 후 조인
- NL 조인과 마찬가지로
조인 방향이 한 쪽으로 고정
select /*+ gather_plan_statistics leading(d) use_merge(e) */ *
from dept d, emp e
where d.deptno=e.deptno(+);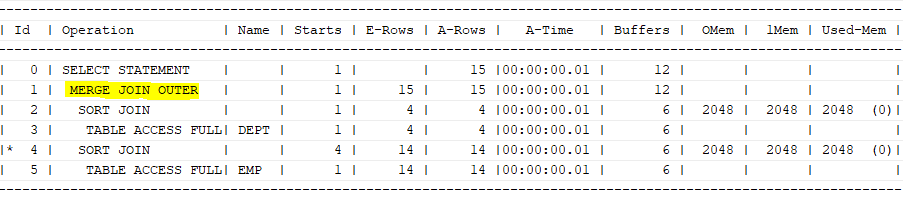
Outer 해시 조인
- 해시 조인은
조인 방향을 바꿀 수 있음 - 데이터가 작은 테이블 데이터로
해시 맵을 만들 수 있게 됨
select /*+ gather_plan_statistics leading(d) use_hash(d e) */ *
from dept d, emp e
where d.deptno=e.deptno(+);
select /*+ gather_plan_statistics leading(d) use_hash(d e) swap_join_inputs(e) */ *
from dept d, emp e
where d.deptno=e.deptno(+);
✨스칼라 서브 쿼리로의 조인
스칼라 서브 쿼리: 입력값에 대해한 개의 반환값만 반환- 스칼라 서브 쿼리는 내부적으로
캐시에 값을 저장해 둠 입력 값과출력 값을 저장해두고 서브 쿼리 실행 시, 캐시에서 입력값을 찾아 만약 있으면 미리 저장된 출력값 반환, 없으면 서브쿼리 실행해 결과 캐시에 저장- 서브 쿼리로 입력값이 다양하게 들어오면, 캐시에 저장해야 할 값이 많아지기 때문에 재사용 가능성이 낮아짐
->자주 반복되고값의 종류가 다양하지 않은테이블과 조인시 사용하면 효과 좋음
select /*+ gather_plan_statistics */ e.empno, e.ename, e.job,
(select dname from dept where deptno=e.deptno) dname,
(select loc from dept where deptno=e.deptno) loc
from emp e;같은 테이블을 두 번 액세스하는 비효율이 발생하는데, 이럴 때 아래와 같이 SQL문을 수정
select empno, ename, job, regexp_substr(sub,'[^$]+',1,1) dname,
regexp_substr(sub,'[^$]+',1,2) loc
from (
select e.empno, e.ename, e.job,
(select dname || '$' || loc from dept where deptno=e.deptno) sub
from emp e);
--또는 TRIM 이용
MSSQL DBA 신입