3D Human Pose Estimation
입력 이미지로부터 사람의 관절을 3D 공간에 위치
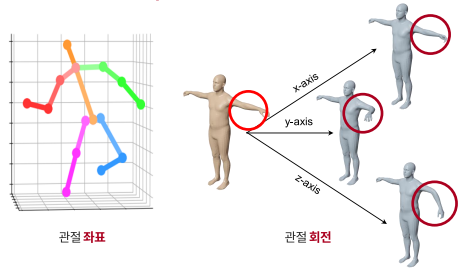
3D human pose란?
3D 관절 좌표 혹은 3D 관절 회전
challeges
2d와 유사함 ( 가려짐, 복잡한 자세, 작은 해상도, 모션 블러, 잘림)
3d만의 문제점
- depth ambiguity
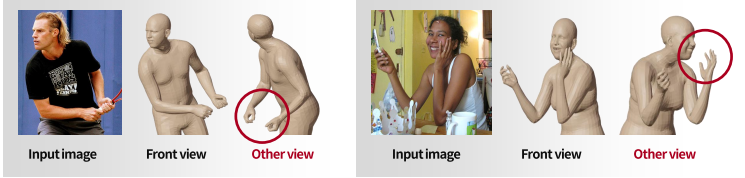
입력이 2d인데 아웃풋은 3d라서 생기는 문제
즉 front view, 카메라가 보는 방향에서 추정은 문제 없지만 다른 각도 view에서 봤을 때는 문제가 생김
⇒ 주어진 정보가 front view밖에 없으므로 그에 최대한 fit(align)되게 하다보니까..
이걸 해결하는 방법은? Multi view image를 제공 그러나 in the wild(일상생활)에서는 비실용적인 접근법임 - Data collection
- 3d 데이터는 특수 장비로부터만 얻을 수 있다(모션 캡쳐 등)
- in the wild(조명, 배경, 환경 등)에 적용하긴 어려움
3D Human Pose Estimation 네트워크의 train, test
기본적 forward 과정
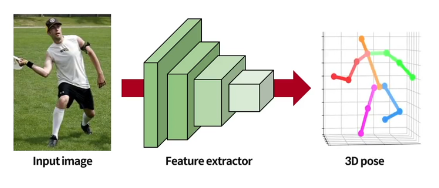
feature extractor : ResNet
3D pose의 shape은 Jx3
J번째 관절의 3D pose는 그 관절의 3D 좌표 혹은 3D 회전을 의미함
Training
coordinate
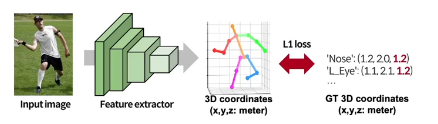
이때, 3D 좌표 x,y,z의 좌표는 meter(cm, mm, m 상관없음) 단 픽셀 단위가 아닌 real scale임
마찬가지로 GT 3D coordinate과 가까워지도록 학습
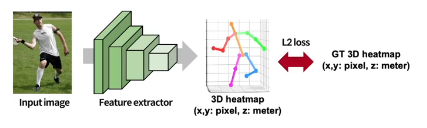
2D의 경우 좌표를 바로 추정하는 것보다 image의 높이와 너비 정보를 보존하는 heatmap을 거치는게 성능이 훨씬 좋게 나오기에 주류임
3D heatmap을 추정할 때, xy는 픽셀 z는 real world 단위임 마찬가지로 관절 위치에 gaussian blob이 있음
xyz 좌표를 모두 real scale로 얻고 싶다면, GT 자체에 image의 높이 너비 정보가 필요 없기에 feature extractor에서 pooling하고 fc 몇개 추가해서 좌표 추정하는 파이프라인
3d까지는 아니여도 xy pixel에 z만 real scale을 원한다면? 이 경우 input이 2D image라서 z축을 만들 수가 없음 feature map의 dimension이 채널의 높이 너비로 되어 있어서 z 축 깊이를 만들 수 없음 따라서 채널 dimension을 늘린 후 reshape을 해서 depth를 만들어냄
ex) c 채널 h, w인 feature map을 c,d,h,w (여기서 c,d가 채널, h w는 1 convolution으로 그대로 감, 채널 수를 늘린거임) 이걸 reshape해서 3d로 만듬
rotation
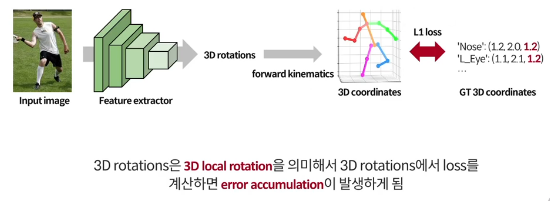
rotation은 pooling한 후 추출(높이 너비 개념이 없으니까)
forward kinematics를 통해 rotation에서 coordinate를 추출
forward kinematics란 미분 가능한 연산
따라서 3D coordinate과 GT 3D coordninate 사이의 loss의 gradient가 feature extractor까지 backward해서 feature extractor가 학습함
error accumulation
rotation만 학습하면 성능이 안좋음
rotation이 local rotation인데, 즉 서로 상대적인 관절들 때문에 foward kinematics를 해서 3d 좌표를 얻으면 각 rotation이 누적되어 좌표가 결정됌 즉 error들도 축적됌 따라서 end point로 갈 수록 error가 커짐
따라서 loss를 두번 계산함( 3D rotation과 3D coordinate )
kinematic chain
트리 구조임 pelvis가 root node이며 나머지는 child node들
Forward kinematics
관절들 사이의 길이와 관절들의 3D 회전으로부터 관절들의 3D 좌표를 recursive하게 계산

out[root_joint_idx]=torch.eye(4)
forward_kinematics(skeleton, root_joint_idx, predicted_pose, out)
recursive코드임
즉 처음 부를때, cur_joint_idx에 루트 노드가 들어가고 child_id에는 루트 노드 바로 밑 child들이 들어감 그 다음 for문에 의해서 그 child들이 하나씩 같은 함수의 아까 루트 노드 들어간 자리에 들어가면서 child를 부르게 됌
이때 global_pose는 결국 output인데, rotation이랑 translate가 같이 있음 (4x4 matrics) 이때 현재 관절과 global pose와 child 관절의 local pose를 행렬곱하면 child 관절의 global pose가 나옴
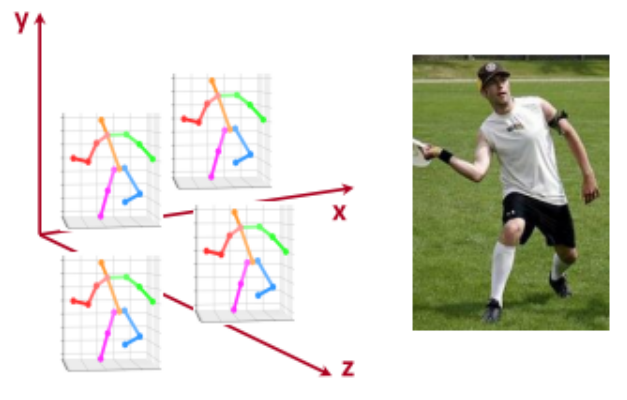
같은 root joint-relative 3d 좌표를 가진 3d 관절 좌표들은 무한개 있을 수 있음 → 즉 중심으로부터 offset은 동일한 (생김새는 똑같은) 것들이 무한개 있을 수 있음 → 위치가 어딘지 모른다는 것임
single cropped의 경우에는 그 위치를 복원할 수 없음 왜냐면 전체 이미지에서 잘랐기 때문에 카메라 위치를 알 수가 없음 사실 single person의 경우 중요한 문제도 아니긴 함
따라서 root joint-relative 3d pose를 추정하도록 학습시키는데 → root joint를 origin으로 두고 relative한 offset들을 관절마다 추정하는 것으로 문제를 단순화함
