Multi Person으로 확장해보자
Top-down 접근법 : Human detection + single person pose estimation
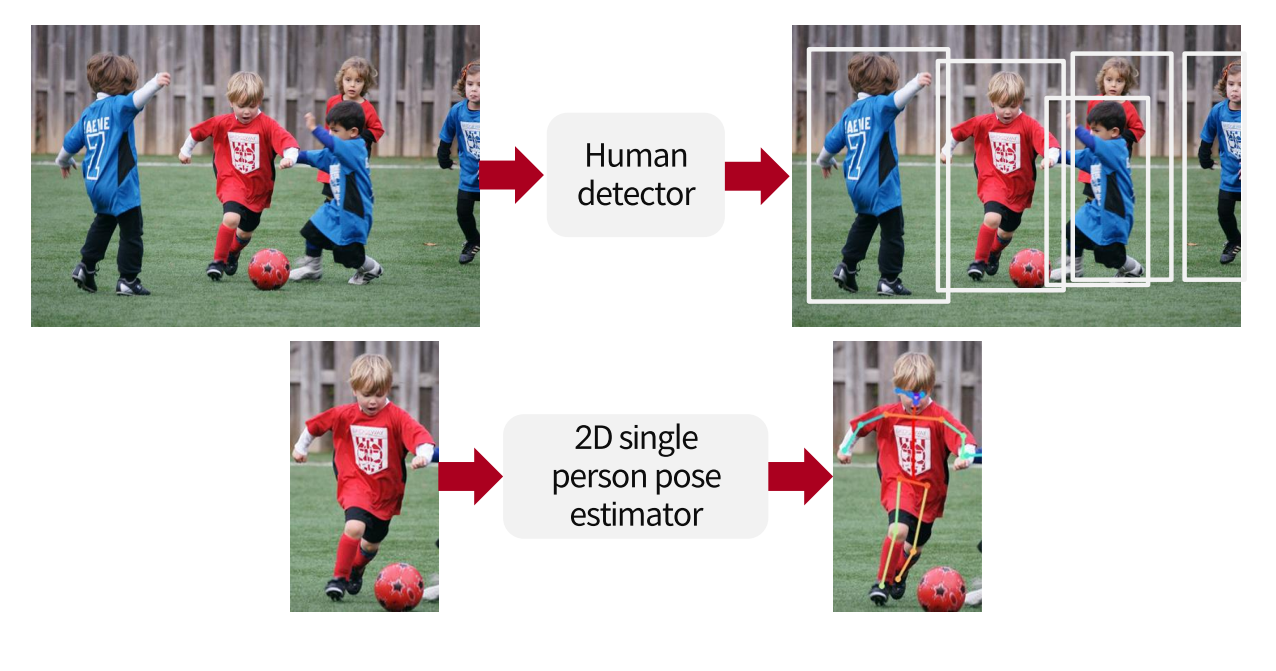
- Human detector : Object detector(mask R-CNN ,YOLO)
- Human detector로 bounding box를 미리 얻고
- 각 사람마다 2D single person pose estimator
Bottom-up 접근법 : joint detection + grouping
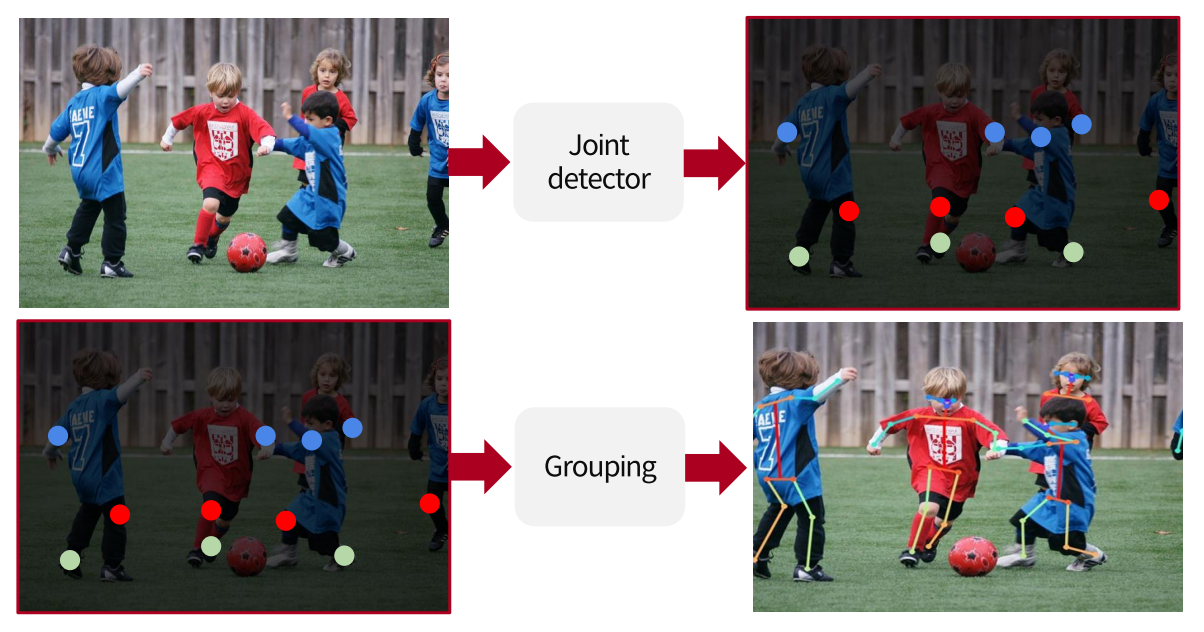
- joint detector : j=JxHxW 즉 팔꿈치 heatmap이면 어떤 사람이든 상관없이 모든 팔굼치를 다 찾음
- 그 다음 grouping함
Top-down 접근법이 성능이 훨씬 뛰어남
Top-down approach
단점 : human detection에 실패하면 single person pose estimation도 당연히 실패함 그러나 최근 detection 모델 자체가 너무 뛰어남
사용하는 사람 입력 이미지가 고해상도 → 크기가 작은 사람도 single person pose estimator에 쓰이기 위해서는 crop해서 사이즈를 재조정함 → 즉 scale이 모두 같음
비효율적 : 두개의 분리된 시스템으로 처리함 → gpu 메모리 등 비효율
bottle neck은 human detection이 아닌 pose estimation임
Bottom-up approach
낮은 정확성 : 입력 이미지가 저해상도 일 수 있음 → crop해서 resize하지 않고 작은 그대로 쓰므로 → 손목 발목 같은 edge들을 detect하기 힘듬
여러 scale을 갖는 사람들을 다뤄야함
효율적임 : 한 네트워크에서 진행됌
