CMAPSS EDA #3 (time_series, distributed lag model, adfuller, AIC, OLS, variance_inflation_factor)
3편에서는 엔진 정비 시기를 예측하기 위한 시계열 분석에 초점을 맞출 것이다.
Loading data
RUL을 계산하고 의미없는 column들을 drop한다. (clipping은 이후에 진행함)
Approach
-
센서 값을 예측하고 '알람' 임계값을 설정한다. 센서가 이 임계값을 초과할 것으로 예측되면 구성 요소가 고장이 임박한 상태로 악화된다. 현재 데이터 세트에 대해 이 접근 방식을 사용하는 몇 가지 주의 사항이 있다.
(a) 모든 센서는 개별적으로 모델링되어야 하므로 센서 간의 상호 작용을 활용할 수 없다.
(b) 적절한 임계값을 설정하기 위해 많은 도메인 지식이 필요하다.
(c) 우리의 목표 기능인 RUL에 대해 직접적으로 알려주지 않는다. -
Vector Autoregression (VAR) 유형 모형. 이러한 유형의 모델은 다변량 시계열을 처리할 수 있지만 초기에 X 및 Y 변수의 지연(lag)를 생성한다. 일반적으로 시계열에서 Y의 과거 값은 Y의 미래 값을 결정하는 데 큰 역할을 한다. 그러나 우리는 Y에 대한 우리의 값이 훈련 세트에서 일정하거나 선형적으로 감소한다고 가정하기 때문에, 이러한 자체 정의 target를 모델에 통합하고 예측을 위해 사용하는 것은 모델 결과에 큰 영향을 미치고 Y(t-1)의 효과를 지나치게 강조할 것이다.
-
Distributed lag model을 사용하자. 기본적으로 각 변수에 대해 추가하는 lag를 완전히 제어할 수 있는 회귀 모형이다.
Distributed lag model을 만들 때, 시계열 및 회귀 분석의 많은 도구와 검정을 사용할 수 있다.
구현할 기본 형태는 다음과 같다
Yt = a + B1Xt + B2Xt-1 + … + Bn*Xt-n
a는 절편이고 B1~Bn은 계수. Xt-1과 Xt-n은 각각 1에서 n까지의 시차를 갖는 Xt의 시차 변수이며, Yt는 현재 시간 t의 대상 변수이다.
여기선 Yt에서 RUL을 예측한다. 다음 사이클 즉 Y(t+1)에서 예측하고 싶다면 traget을 1개 shift하면 된다.
Adding lagged variables
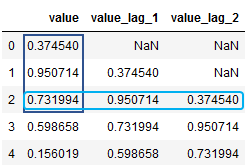
pandas의 shift() 를 통해서 lagged variable을 생성. lagged column은 이전 time stamp 값들이 있다. 데이터 세트에 lag1을 추가하고 NaN 행을 drop.
LinearRegression을 통해 성능 평가.
returns
train set RMSE:39.367692351135005, Variance:0.6709929595362338
test set RMSE:31.423109839706022, Variance:0.42820706786532714
lag time을 1 추가하면 RMSE가 31.95였던 기본 모델이 이미 약간 개선된다. 더 많은 지연 시간을 추가하면 결과가 개선되기 시작함.
시계열 분석 및 회귀 분석을 적용할 때 고려해야 할 몇 가지 가정이 있다.
Stationarity
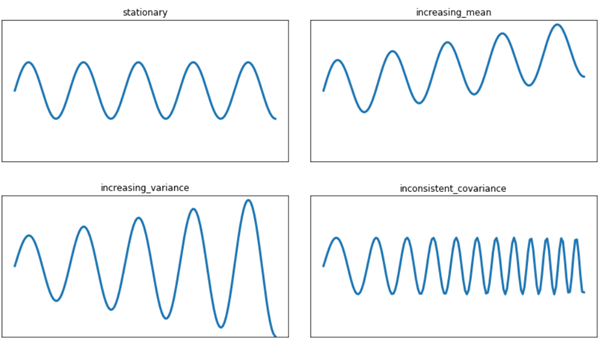
정지성은 평균 및 분산과 같은 시계열의 통계적 특성이 시간에 따라 변하지 않음을 의미하며, 또한 공분산(시계열의 확산)이 시간에 의존해서는 안 된다는 것이다. 많은 통계 모델이 예측을 위해 이러한 속성에 의존하기 때문에 이러한 통계적 특성은 일정하게 유지하는 것이 중요하다. 따라서 평균, 분산 또는 공분산이 시간에 따라 변하는 경우 모형은 다음 값을 정확하게 예측할 수 없다.
데이터에서 정지 상태를 확인하기 위한 검정이 있고, 검정을 통과하지 못한 경우 시계열을 정지 상태로 만드는 방법도 있다.
정지 상태를 테스트하기 위해 Augmented Dickey-Fuller 테스트를 사용하자. 검정 통계량이 음수일수록 신호가 더 정지한다. p-값이 0.05보다 작으면 시계열이 정지 상태라고 가정할 수 있다.
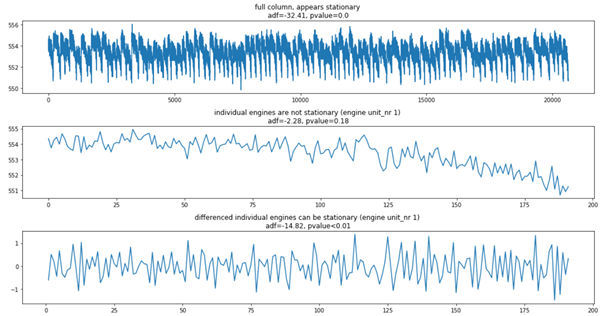
- 한 센서 칼럼의 정지 상태 테스트에는 모든 100개 엔진의 시계열이 포함된다. 모든 엔진이 함께 정지 신호를 형성하지만 개별 엔진의 신호는 정지하지 않을 수 있다.
정지 상태가 되기까지 각 엔진의 각 센서의 시계열을 몇 번 더 변경해야 하는지 사전에 알 수 없으므로, p-값을 정지 상태를 가정하는 결정적 요소로 사용하여 이러한 기능을 처리하는 function을 만든다.
데이터를 모두 stationary data로 만들고 linear 회귀를 하자.
returns
train set RMSE:51.63375613791181, Variance:0.4340864011385228
train RMSE 값이 상당히 나빠졌다. 데이터에 trend가 없어서 회귀선을 fit하기가 어려워졌기 때문이다. 따라서 lagged variable을 추가한다면 시간이 지남에 따라 센서 값의 변화 간의 관계가 모델에 알려지기 때문에 성능이 다시 향상된다.
다음은 최적의 모델을 위해 몇개의 지연이 필요한지 결정하겠다.
AIC : searching for the correct number of lags
AIC(Akaike Information Criterion)는 모델 품질을 반영하는 지표로 시계열 분석에 자주 사용된다. 그것은 과적합과 과소적합 모두를 고려한다. 여러 유사한 모델을 교육할 때 모델 선택을 위해 AIC 점수를 비교할 수 있다. 일반적으로 점수가 낮을수록 좋지만 복잡성과 모델 품질 개선 사이에는 절충이 있다.
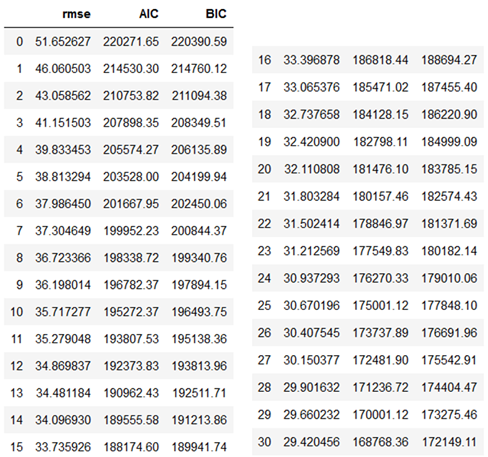
우리는 AIC가 더 많은 지연을 추가함으로써 모델 개선의 수익률을 감소시키는 티핑 포인트를 찾고 있다. 그러나 해당 표는 계속 개선되는 것처럼 보여서 명확하지 않기에 시각화를 통해 표현해보자.
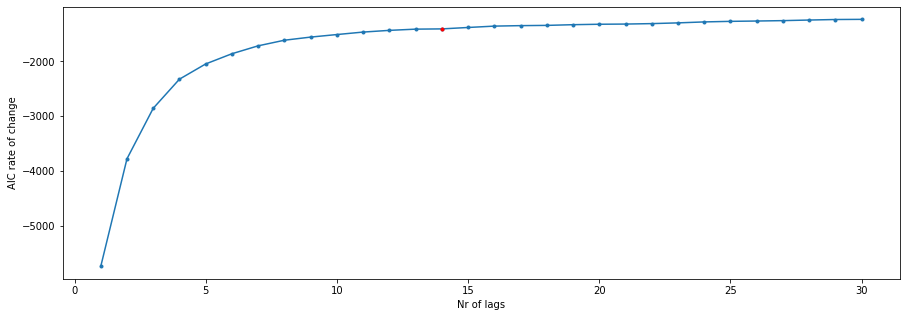
14번의 지연 이후 품질 개선이 정체되는 것으로 보인다. 이 시점에서 모델 복잡성과 품질 사이의 절충에 도달했음을 나타낸다.
동일한 변수의 여러 시차를 추가하는 경우의 한 가지 문제는 다중 공선성의 도입(통계학의 회귀분석에서 독립변수들 간에 강한 상관관계가 나타나는 문제) 가능성이다.
Multicollinearity
다중 회귀 분석 모형의 독립 변수가 높은 상관 관계를 가질 때 다중 공선성이 발생. 본질적으로 다음 시간 값과 관련이 있는 시계열의 특성상, 지연 변수를 추가할 때 다중 공선성을 도입할 가능성이 큼. 다중 공선성은 모델의 계수와 안정성에 영향을 미쳐 새 데이터에 대한 잘못된 결과가 발생할 가능성을 높임. 5 미만의 vif-값이 안전한 것으로 간주되기 때문에 분산 인플레이션 계수(VIF)를 계산하여 모델의 다중 공선성을 테스트하자.
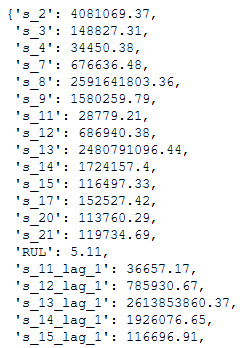
우리 모델은 vif 값이 5보다 훨씬 큰 다중 공선성으로 인해 크게 어려움을 겪는 것으로 보인다. 다중 공선성을 계산하기 위해 statsmodel이 사용하는 방법은 스케일링에 의해 큰 영향을 받을 수 있다는 것을 발견했다. 따라서 scaling transformation을 구현하자.
StandardScaler() make_stationary() add_lagged_variables()
Combine, predict and evaluate
추가할 lag 수를 계산하는 과정을 반복하면, scaling 추가 후 약간의 변동이 있어서 9개로 줄어든다.
drop(), scaler, stationary, add lagged, add constant, fit model, predict, evaluate
returns
train set RMSE:20.80233928213837, Variance:0.7523208224684113
test set RMSE:21.14895857012398, Variance:0.7409888687595052
현재 우리 모델은 연속적인 lagged variable을 사용한다. 그러나 근접한 lag가 고유한 정보를 가질 필요는 없다.(시차 6, 7, 8에서 센서 값의 변화는 미미할 수 있으므로 모델에 실제로 도움이 되지 않을 수 있다.) 센서 값의 변화는 시차 사이의 시간 단계를 증가시킬 때 더 뚜렷해진다. (센서 5,10,20은 정보를 제공하기에 충분히 differ할 수 있다). 높은 lagged variable을 추가할 수록 더 많은 데이터 행도 폐기되므로 trade-off가 됌.
엔진이 열화되고 고장이 가까워지면 센서에서 단일 시간 단계를 구분할 수 있는 분명한 경향이 나타난다. 그래서 개인적으로, 시차 사이의 시간 단계를 늘리기 전에 처음 몇 개의 시차를 연속적으로 유지하기로 선택한다. 몇 가지 변형을 시도해 보고 어떤 점수가 가장 좋은지 알아보자.
물론 더 많은 가능성이 있지만, 최소의 시험과 더 많은 연속적인 시차를 추가함으로써 발생하는 정체된 개선을 고려했을 때, 시차[1,2,3,4,5,10,20]가 20.85의 RMSE에서 가장 잘 수행되었다.
Distributed lag model은 뛰어난 유연성과 제어력을 제공하는 동시에 비즈니스에서 쉽게 설명하고 해석할 수 있다.
