GOLFPOSE : golf swing analyses with a monocular camera based human pose estimation
ABSTRACT
자동화된 골프 스윙 분석을 위해 GolfPose라는 lightweight temporal-based 2D human pose estimation(HPE) 방법을 제안한다.
기존의 image-based 방법과 달리, temporal based 방법은 추정 정확도와 빠르게 움직이며 부분적으로 self-occulsion된 키 포인트에서 이점을 갖기에 효율적이고 효과적인 골프 분석을 위해 설계되었다.
-
self occulsion
Occlusion often occurs when two or more objects come too close and seemingly merge or combine with each other
모바일 기기에서 사용될 수 있도록 real-time 추론을 가능하도록 최적화함
golf club detection(GCD)를 통해 제안된 temporal based 방법은 정확도를 크게 향상시킨다
INTRODUCTION
스포츠 분석에서 중요한 것은 스포츠 선수의 동작을 이해하고 판단하는 것이다. 따라서 신뢰할 수 있는 골프 스윙 분석을 위해서는 정확하고 효율적인 HPE 방법이 중요하다. 그러나, 골프 스윙 분석의 경우 input format, motion blur, self-occlusion의 문제로 다른 HPE task와는 다르다.
따라서 GolfPose라는 temporal-based lightweight 2D HPE 파이프라인을 제안한다.
contribution
- A light-weight monocular temporal-based 2D human pose estimation model which provides accurate pose estimation results and can be deployed on mobile devices
- 정확한 포즈 추정 결과와 모바일 기기에 배포할 수 있는 A light-weight monocular temporal-based 2D human pose estimation model
- Incorporating line segment based golf club detection(GCD) to further improve pose estimation accuracy
- line segment 기반의 GCD를 통합해 포즈 추정 정확도를 향상
- An annotated golf swing dataset with more than 500 videos of over 120 fps and 120,000 images.
- 골프 스윙 데이터 세트
RELATED WORKS
2D Pose Estimation
처음에는 키포인트 위치를 이미지에서 직접 회귀했으나 나중에는 키포인트 히트맵을 추정한 후, 가장 높은 값을 가지는 위치를 키포인트 좌표로 선택하는 방법이 주류
HPE 방법은 human b-box를 먼저 감지하는지 여부에 따라 bottom-up과 top-down 방식으로 분류한다
- Top-down : b-box를 먼저 감지한 후, 모든 b-box 내에서 키포인트 감지를 수행
- Bottom-up : 이미지의 모든 사람에 대한 모든 키포인트 감지 후, 동일한 사람에 속한 키포인트를 개별적으로 연결
데이터 세트의 한계와 in-the-wild 영상에서 정확한 사람 추적의 어려움으로 single-frame-based HPE tasks가 주요 초점
해당 경우, 골퍼의 움직임이 제한되며 motion blur와 self-occlusion을 무시할 수 없기에 temporal-based HPE model로 시간 정보를 활용하고 HPE 정확도를 높일 것이다
Sports Analyses
Action and trajectory analyses
심층적 분석과 평가를 통해 캡쳐된 플레이어의 동작은 기술을 향상하고 게임에서 경쟁력을 높이는데 중요함. 목표 추적(공)은 플레이어의 성능 및 대상과의 상호 작용을 평가하는 방법을 제공
Player Tracking
양 팀 선수의 이동 궤적을 추적하면 팀원 간의 상호 작용을 평가할 수 있으며 전술과 전략 개발에 중요함
METHOD
목표는 모바일 장치에서 찍은 monocular swing 영상에서 정확한 3D pose를 추정하는 것. 2D Golf Pose는 먼저 플레이어의 몸과 클럽에서 키포인트를 생성한 후 3D 포즈로 변환한다.
해당 논문에서는, GolfPose의 2D 구조에 적용된 성능 개선에 초점을 맞춘다.
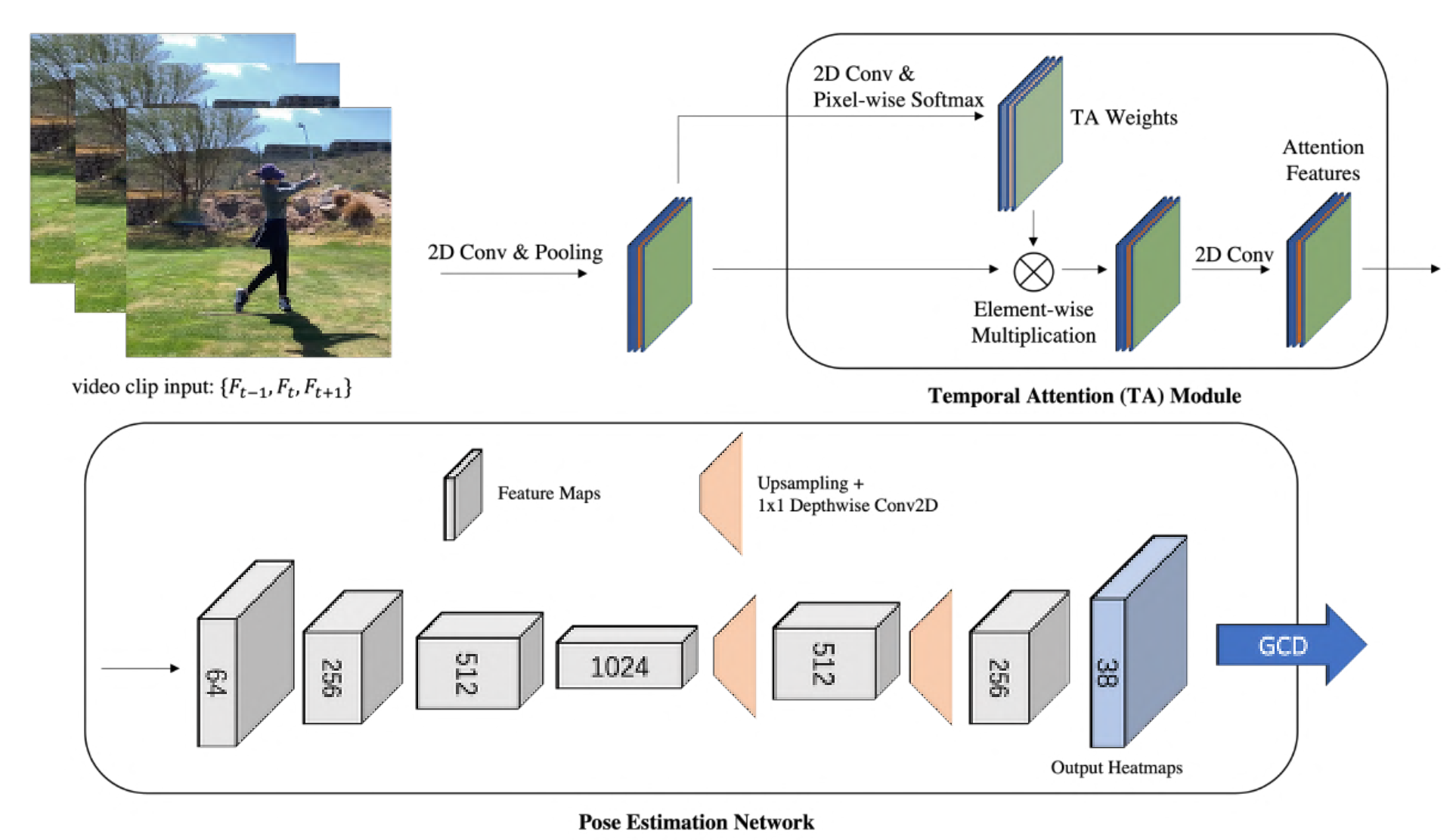
기존 image-based HPE 프레임워크를 기반으로 CNN 기반 temporal 2D HPE 모델을 구축한다. 입력은 영상 시퀀스 클립이므로 시간 정보를 활용해 키포인트 예측 정확도를 높인다. line segement 알고리즘을 구현해 2D HPE 모델에서 생성된 골프 클럽 키포인트에 대한 부정확한 예측을 수정한다.
Problem Formulation

input 영상으로, HXW size의 RGB(C=3) L frame
HPE의 목표는 영상 시퀀스에 대한 모든 frame에서
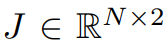
인 2D keypoint set을 예측하는 것. N은 keypoint 개수(38개)
sequence-based 접근으로 짧은 영상인
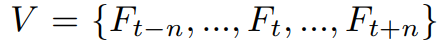
에서 매 타임 스텝 t마다 작동함
center frame인 Ft에 HPE 결과를 출력함
2D Temporal based Model
self-occlusion과 motion blur 문제를 해결하기 위해서 시간 정보는 좋은 해결 방법이다. 따라서 2D temporal-based HPE 모델을 제안함
temporal attention 모듈은, “Dior: Distill observations to representations for multi-object tracking and segmentation”에서 수정함.
기존 temporal attention 모듈은 3D convolution을 기반으로 하여 높은 계산 비용과 모바일 장치에서 실시간 수행이 불가함. 이를 위해 3D convolution을 depthwise 2D convolution으로 바꾸고 아키텍쳐도 수정함
나머지 부분은 LPN(”Simple and lightweight human pose estimation”)에서 수정하여 모바일 호환가능하게 함
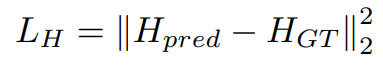
모델을 훈련하기 위해선 다른 HPE 모델과 같이 MSE loss를 사용하여 예측된 키포인트 히트맵(Hpred)와 ground truth 키포인트 히트맵(Hgt) 사이의 차이를 줄임
Golf Club Detection
스윙 동작에서 골프 클럽의 빠른 움직임은 2D GolfPose model에 motion blur 등으로 인한 골프 클럽 탐지의 유실을 발생시킴. 또한 이미지 영역 밖에서 움직일 수도 있기에 탐지 실패를 야기함. 이러한 문제는 키포인트 예측의 성능을 방해한다. 특히, club hosel의 포인트는 골프 스윙에서 가장 중요하다.
따라서 부정확한 hosel 예측 문제 해결을 위해 전통적 컴퓨터 비전 기술을 사용함


위 알고리즘은 GCD(golf club detection)을 설명한 것.
- 2D GolfPose 키포인트 모델 예측 결과를 바탕으로 골프 클럽의 b-box를 결정
- 골프 클럽 b-box 영역에 LSD(Line Segment Detection) 적용
-
LSD 출력은 LSD가 pixel 정보에만 의존하며 잔디와 땅과 같은 다른 선 모양 요소에 쉽게 영향 받을 수 있기에 각자 다른 방향의 unconnected short line segement를 준다
-
클럽 핸들의 탑 부분 Jhandle부터 클럽의 중간 Jmd까지의 방향을 reference direction으로 설정한다
-
이전에 감지한 중복되고 잘못된 선분과 이 reference direction을 사용하여, reference direction에 대해 큰 각도를 가진 선분을 제거하고 나머지 선분의 벡터 방향을 할당함
-
iteration을 통해 골프 클럽에 놓여있지 않은 outlier를 제거하고 다른 벡터들을 연결해 전체 골프 클럽 라인을 형성한다.
매 iteration에서 search space에서 새로운 vector를 찾고 현재 클럽 라인 후보와 연결하여 골프 클럽을 나타내는 새 라인을 형성한다.
연결된 벡터는 현재 클럽 라인과 두 벡터 사이의 거리가 최소인, 일정한 방향을 갖고 있어야한다.
두 벡터 사이의 거리인 D는 first의 end point와 second의 start point 사이 거리이다.
-
EXPERIMENTAL RESULTS
Dataset and evaluation metrics
120,000개의 이미지가 포함되며, 100,000개의 이미지는 훈련에 20,000개의 이미지는 검증 및 테스트에 사용된다.
기존의 2D HPE 데이터 셋 (COCO)와 다르게, 우리 데이터 세트는 영상 기반이며 motion blur를 제거하기 위해서 120fps 이상으로 기록된다.
골프 클럽의 키포인트까지 포함해서 38개의 키포인트가 주석되어 있다. 우리 데이터 셋의 영상 해상도와 기록된 선수의 사이즈가 비슷하기에 2D mean pixel error를 키포인트 정확도를 평가하는 evaluation metrics로 사용한다.
Training details
GolfPose는 모바일 장치를 위해 설계되었으므로, TensorFlow 프레임워크를 사용해 시스템을 구현하고 모바일을 위해 TensorFlow Lite 모델로 변환한다.
pose estimation 모델은 E2E 방법으로 학습된다. 모든 파라미터는 σ = 0.001인 zero-mean Gaussian distribution에서 랜덤하게 초기화된다. 32 사이즈의 mini-batch로 Adam optimizer를 사용해서 파라미터를 업데이트 한다. epoch은 150이며 초기 learning rate는 0.001이고 90번째와 120번째 epoch에서 10배 감소한다.
영상 frame에서 감지되고 cropped된 사람 b-box는 Height:Width = 4:3의 비율로 고정된다. cropped b-box는 256X192로 resize되어 기존의 비율을 유지하며 black background로 padding되어 input image로 사용된다.
data augmentation을 위해 random rotation, random scale, flipping을 하였고 특정 상황에서 시스템의 견고성을 위해 추가적 증강 기법을 사용했다(밝기 조정 등)
random gaussian noise를 추가하여 카메라가 흔들려 발생한 motion blur를 시뮬레이션함
train은 NVIDIA 1080Ti GPU로 36시간 걸림
Results

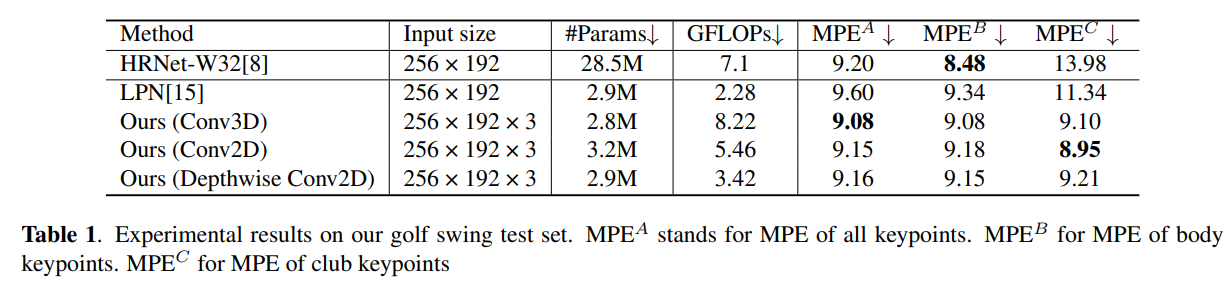
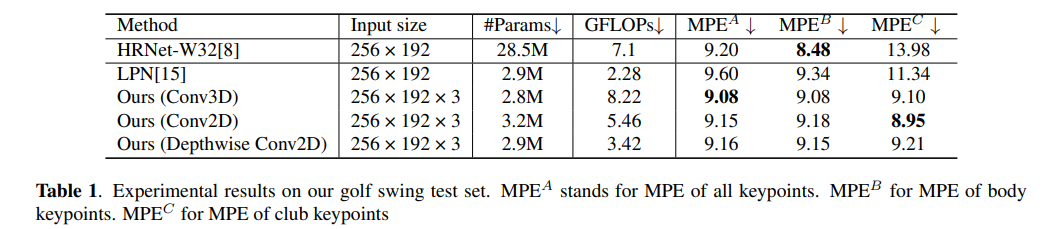
HRNet과 비교하여 더 좋은 성능을 냄(낮은 GFLOPS, 적은 파라미터)

골프 클럽의 키포인트에 대해, multi-frame temporal input과 temporal attention 모듈의 도움으로 image-based SOTA인 HRNet보다 더 좋은 성능을 냄
모델 사이즈가 작기에 모바일 장치에서 추론 속도 면에서 더 좋으며, 모든 연산은 모바일 GPU로 가속화 가능함
GCD는 HPE 모델의 실패한 케이스를 수정하기 위해 통합되었으며, 골프 클럽의 키포인트 추정 정확도를 개선시켰다.

특히 GCD는 골프 클럽 hosel의 pixel error 표준 편차를 33.89에서 23.19로 낮췄다. 즉 GCD가 효과 있었다는 것.
Ablation Study
시퀀스 입력의 길이와 temporal attention 모듈의 다양한 디자인을 포함한 각 구성 요소의 효과를 연구함
Length of input sequence
single image-based가 아닌 sequence-based이므로, 입력 시퀀스 길이가 정확도와 속도에 어떠한 영향을 주며 좋은 trade-off를 결과적으로 주는지 확인하고자 한다.
단순히 길이를 증가시키는 것이 좋은 선택이 아님. 정확도와 속도 둘 다 안좋게 될 수도 있음
Temporal attention module
속도 향상을 위해 3D convolution을 2D convolution 또는 depthwise 2D convolution으로 교체했다.

GFLOPs와 추론 시간은 개조로 인해 의미있게 줄어들었으며 성능은 비슷하게 유지했다. depthwise 2D convolution based temporal attention module이 모바일 장치로는 가장 좋은 선택이다.
CONCLUSTION
본 논문은 모바일 기기에 적용할 수 있는 효율적이며 정확한 골프 스윙 분석을 위해 새로운 lightweight temporal-based 2D human pose estimation 방법인 GolfPose와 골프 클럽의 키포인트 예측을 개선하기 위한 GCD 방법을 제안했다.
이 파이프 라인은 플레이어가 움직이지 않는다는 가정하에 성공적이다. 이는 골프 스윙에서는 작동하지만, human tracking mechanism이 요구되는 플레이어가 돌아다니는 상황에는 적합하지 않다.
