GolfDB : A Video Database for Golf Swing Sequence
Abstract
골프 스윙의 주요 이벤트를 감지하고 골프 스윙 분석을 용이하게 하기 위한 골프 스윙 시퀀싱 개념
1400개의 고품질 골프 스윙 동영상으로 구성된 벤치마크 데이터세트 GolfDB. 각 영상은 event frames, bounding box, player name, sex, club type, view type 라벨을 포함.
SwingNet이라는 hybrid convolutional and recurrent neural network 구조를 갖고있는 lightweight deep neural network를 제안
Introduction
CNN을 통해 video recognition, action recognitino, temporal action detection, spatio-temporal action localization 작업이 가능해짐 이를 통해 CNN을 영상에 적합하게 맞춰서 골프 스윙 비디오에서 event frame 자동 추출을 통해 골프 스윙 분석을 하고자 함
GolfDB는 다양한 프레임 속도와 390k 이상인 남녀 프로 골퍼 총 1400개의 HD 골프 스윙 비디오를 유투브에서 수집한 것이다. 각 영상은 8개의 event label 주석을 수동으로 달았으며
- event label
- club type(driver, iron, wedge)
- view type(face-on, down-the-line, orther)
- player name
- sex
등의 정보가 있음
자세히는 pickle file의 key를 확인한 결과 다음과 같음
Index(['id', 'youtube_id', 'player', 'sex', 'club', 'view', 'slow', 'events',
'bbox', 'split'],
dtype='object')또한 GolfDB에서 골프 스윙 이벤트를 detect하는 SwingNet이라는 lightweight baseline network를 제안함
Related Work
Computer Vision in Golf
공의 궤적을 실시간으로 추정, 골프 스윙 분석 등의 연구가 있음
GolfDB는 human pose 및 golf club 추적을 지원하는 다양한 키포인트 주석을 포함하도록 확장할 계획이 있음. SwingNet을 사용한 automated golf swing sequencing은 pose-baed golf swing 분석을 보완함
Action Detection
action detection에는 여러 하위 항목이 존재
action recognition은 영상에 대한 단일 동작을 예측하는데 대응됨
- 이미지 시퀀스에 시간 정보를 fusing 하기 위해 CNN을 사용함
- 3D CNN을 사용해 전체 영상 차원에서 convolution 수행
- RNN, LSTM
Temporal action detection은 영상의 시작과 끝 frame을 예측하는 작업
- Segment-CNN
- 강화학습을 활용한 RNN
Spatio-temporal action localization은 3D CNN과 oebject detection model을 합치는 것에서 문제를 겪음
- I3D model은 Faster R-CNN과 결합
- Tube-CNN
Event Spotting
일반 행동의 시간적 경계를 예측하는 것은 시간적 범위를 둘러싼 불확실성에 의해 쉽지 않은 작업임. 단 스포츠 행동에서의 이벤트는 단일 시간 인스턴스에 고정된다. 따라서, 잘 정의된 이벤트가 발생할 때 시간 인스턴스(지점)을 찾을 수 있다
Golf Swing Sequencing
golf swing sequencing은 단일 골프 스윙을 포함하는 영상에서의 event detection(spotting)임
trimming(화면의 불필요한 부분을 제거하여 구도를 조정하는 일) 영상을 쓰는 이유는 다음과 같다
- untrimmed 영상도 존재하지만 이를 별도의 작업으로 간주하고 향후 연구를 위한 방법으로 생각함
- 현장에서 골프 스윙 시퀀스를 보고자하는 사람은 피사체가 프레임 중앙에 오도록 모바일 장치에서 간단히 녹화할 수 있다. 즉 시공간적 지역화의 필요성이 제거됌
- 해당 영상들은 특정 순서로 발생하는 특정 수의 이벤트로 구성된다
Golf Swing Events
엄격한 이벤트 정의를 사용해 단일 frame으로 지역화할 수 있다. 다음과 같이 골프 스윙 시퀀스를 구성하는 8개의 연속 이벤트를 정의한다

GolfDB
1400개의 골프 스윙 비디오 샘플과 390k 이상의 프레임으로 구성된 GolfDB는 골프 스포츠에서 computer vision의 첫 번째 실질적인 데이터 세트임
Video collection
실시간 및 슬로우 모션 골프 스윙이 포함된 580개의 youtube 영상 모음을 수동으로 편집함 골프 스윙 시퀀싱의 경우 shaft가 항상 보이는 것이 중요하며 모션 블러를 완화하기 위해 고품질 영상만 고려함
총 248명의 개인으로 구성되어 다양한 골프 코스의 다양한 위치와 다양한 카메라 각도를 갖고 있음 이러한 특성은 모델의 일반화에 도움이 됨
Annotation
주석은 골프 스윙(pitch shots, chips, putts 등)을 식별하고 10개의 프레임 라벨(시작, 8개 골프 스윙 이벤트, 종료)을 지정함 또한 b-box와 golf club 유형, 실시간/슬로우모션 식별. 이때 b-box는 클럽 헤드와 골프공을 포함한다. 또한 골퍼의 이름과 성별을 식별함
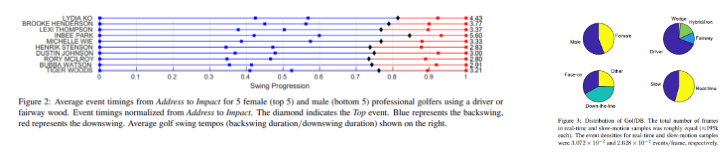
Evaluatoin Metric and Experimental Protocol
이벤트 감지에 대해, 프레임 수에 대한 허용 오차 δ를 도입함 30fps 기준으로 δ = 1이며 슬로우 모션의 경우 기본 프레임 속도를 기준으로 허용 오차를 조정
따라서 sample-dependent tolerance (샘플 종속 오차)는 다음과 같음
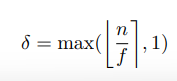
n은 address에서 impact까지의 프레임 수, f는 샘플링 빈도, []는 정수 반올림
PCE 평가 메트릭을 허용 오차 내의 ‘Percentage of Correct Events’로 사용함. PCE는 head segment length를 사용해 spatial detection tolerance를 측정한다. cross-validation을 위해 4개의 random split을 사용하고 이 4개 split에 대한 평균 PCE가 기본 평가 메트릭으로 사용
SwingNet : A Swing Sequencing Network
SwingNet은 야구, 테니스, 크리켓과 같은 다양한 스포츠의 스윙으로 일반화할 수 있다
Network Architecture
MobileNetV2는 CNN 기반 inverted residual 구조이며 lightweight depthwise convolution을 자유롭게 사용할 수 있게 한다 따라서 모바일 어플에 잘 맞는다 또한 MobileNetV2는 각 layer의 채널의 수를 확장하여 네트워크 복잡도와 속도 사이의 편리한 trade-off를 제공하는 ‘width multiplier’를 포함한다
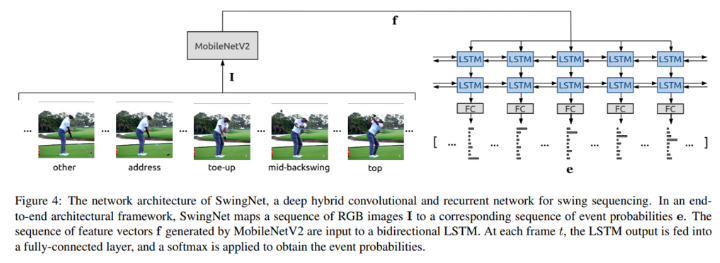
이미지 분류 작업을 위해 224X224 크기의 input과 1개의 width multiplier를 사용해서 Google Pixel의 단일 코어에서 프레임당 75ms속도로 실행된다. 모바일 배포에 중점을 두었기에 MobileNetV2를 E2E 네트워크 구조의 backbone CNN으로 사용하며, dXd RGB 이미지 시퀀스인 I = (I1, I2, ..., IT)를 대응하는 이벤트 가능성인 e = (e1, e2, …, eT) 시퀀스로 매핑한다. 여기서 T는 시퀀스 길이이며 C는 이벤트 클래스의 개수(총 9개, 8개의 골프 스윙 이벤트와 1개의 No-event)이다.
단일 프레임을 사용해 골프 스윙 이벤트를 감지하는 것은 어려운 작업니다. 따라서 시간적 context가 중요한 구성 요소가 된다. 시간 정보를 잡아내기 위해, MobileNetV2의 최종 feature map에 GAP를 적용한 feature vector f = (f1, f2, …, ft)의 시퀀스를 각 layer마다 H hidden units를 갖고 있는 N-layer bidirectional LSTM의 input으로 사용한다. 매 frame t마다 LSTM의 H 차원 output이 fc layer를 통해 공급되고 클래스 가능성 e를 얻기 위해 softmax가 더해진다. FC layer의 weight는 프레임마다 공유된다.
Implementation Details
프레임은 b-box를 사용해 크롭했다. 그 다음 bilinear interpolation을 사용해 resize해서, 가장 긴 차원이 d와 동일하도록 했으며 ImageNet pixel mean을 사용해 패딩을 해서 input size가 d X d가 되도록 하였다. 최종적으로 모든 프레임은 ImageNet means를 빼고 ImageNet standard deviation으로 나누어 정규화 하였다.
MobileNetV2의 각 convolutional layer 뒤에는 batch normalization이 있고 비선형성이 사용되지 않은 inverted residual 모듈의 최종 convolution을 제외하고는 batch normalization 뒤에 ReLU가 있다.
MobileNetV2 backbone은 ImageNet의 사전훈련 weight로 초기화 했고, fully-connected layer의 weights는 Xavier Initializatoin을 따른다.
골프 스윙 이벤트와, no-event 클래스 사이의 불균형성을 고려해 weighted cross-entropy loss를 사용했다. 이때 골프 스윙 이벤트는 가중치 1을, no-event는 가중치 0.1을 사용함
시작 프레임을 무작위로 선택하는 것은 데이터 증강의 한 형태이며 action recognition에서 자주 사용된다. random horizontal flipping, slight random affine transformation과 같은 다른 데이터 증강도 사용됌. (horizontal : 왼손잡이와 오른손잡이 사이의 불균형, affine : 카메라 각도의 변화)
이미지 시퀀스의 배치의 훈련을 가능케하기위해서 T 길이의 여러 시퀀스가 네트워크에 입력되기 전에 채널 차원에 따라 concat되었다. output features f는 LSTM의 입력으로 들어가기 전에 (batch size, T, 1280)으로 reshape된다. 학습의 관련 요소에 대해서 Adam optimizer가 초기 learning rate 0.001로 사용되었다. 모든 학습은 NVIDIA Titan Xp GPU에서 진행됌.
Test할 때는, sliding window 접근법이 모든 full-length golf swing 영상에 적용되었으며 sliding window는 T size이고 computation load를 최소화하기 위해 overlap은 사용되지 않았다. 각 sample은 정확히 8개의 event를 포함하며 event frame은 각 event class에 대한 maximum confidence를 사용해 선택되었다.
Experiments
알맞은 하이퍼파라미터를 결정하기 위한 실험들에 대한 설명
Ablaton Study
생략
Frozen Layers
ablation study의 결과는, sequence 길이와 batch size의 증가가 성능향상을 가져온다는 것을 밝힌다. 단일 GPU에서 sequence length와 batch size는 제한적이다. 모델이 pre-trained ImageNet weight에 크게 의존하는 것을 알기에 우리는 어떠한 ImageNet weight가 성능의 손실 없이 frozen될 수 있을 것이라고 가정했다.
따라서, 더 큰 sequence length와 batch size를 위해 GPU 메모리에 공간을 만들기 위해 학습 전에 MobileNetV2에 freezing layer를 넣어서 실험해보았다
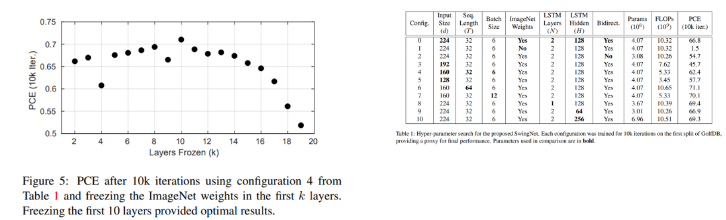
왼쪽 plot은 첫 k layer를 오른쪽의 configuration 4를 사용해서 freezing한 결과이다. 몇 outlier에도 불구하고 PCE는 k=10까지 증가하였으며 그 이후 감소하기 시작했다. 이 결과를 활용하여 baseline SwingNet을 더 큰 sequence length와 batch size를 사용해 학습시킨다.
Baseline SwingNet
위의 오른쪽 테이블은 input size 160이 224보다 더 비용 효율적이라고 제안한다. 후자는 단지 7%의 PCE 증가를 위해 두 배의 연산이 필요하다. 이를 고려해 다른 하이퍼파라미터의 비교 결과 뿐만 아니라 우리는 input size 160 sequence length 64 hidden unit 256개의 single-layer bidiretional LSTM인 baseline SwingNet을 제안한다. pre-trained된 ImageNet weight로 초기화하고 10 layer를 freezing하면 모델은 12GB의 단일 GPU에 24 batch size로 학습할 수 있다. 상당히 큰 batch size로 모델은 더 빠르고, 학습하는데 많은 반복을 필요로 하지 않게 된다. 따라서 baseline SwingNet은 7k 반복으로 GolfDB의 각 분할을 학습했지만 learning rate은 5k 반복 후 10배 감소한다. Affine transformation은 학습 데이터를 augment하기 위해 사용되었다.

SwingNet은 event를 76.1%로 알맞게 감지한다. Address와 Finish는 좋지 않은 감지 결과를 보여준다. 이는 주관적 라벨링의 복합적 요인과 이러한 이벤트를 시간적으로 정확하게 localizing하는 것과 관련된 내재된 어려움에서 비롯되었을 가능성이 높다. 이러한 요소는 Top 이벤트에서도 보이는데, slow-motion에서는 전환이 유동적이기에 club의 방향이 바뀌는 정확한 프레임이 해석하기 어렵다. 더욱이 감지율은 backswing 이벤트에서도 보통 slow-motion이 낮다. backswing이 downswing보다 훨씬 느리기에 ground-truth와 비슷하게 보이는 frame들이 많기 때문일 것이다.
Impact 이벤트는 가장 능숙하게 감지되었다. 이 결과는 직관적인데, 모델이 단지 clubhead가 golfball과 가장 가까울 때만 찾으면 되기 때문이다. 팔이나 shaft가 지면과 평평할 때 즉 Toe-up과 Mid-backwing과 같은 이벤트를 해석하는 것은 더 추상적인 직관을 필요로 한다. Address와 Finish를 고려하지 않는다면 총 PCE는 91.8%이다.
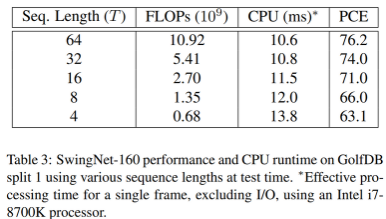
64 sequence length로 훈련한 이후, 더 작은 sequence length가 test time에 사용되더라도 약간의 성능 감소만 발생한다. 이는 모바일 배포에 영향을 주며, 시퀀스 길이는 네트워크의 메모리 요구사항을 줄이기 위해 활용될 수 있다는 것을 의미한다.
Conclusion
본 논문은 trimmed된 골프 스윙 영상에서 주요 이벤트 감지로써 골프 스윙 시퀀싱 작업을 소개했다. 목적은 모바일 장치를 통해 현장에서 즉각적인 피드백을 제공하여 골프 스윙 분석을 용이하게 하는 것.
이를 위해 GolfDB를 구축하고, 모바일 배포 가능하며 deep hybrid convolutional and recurrent network 구조인 Swing Net을 소개했다.
