Gaze Estimation

https://github.com/dangdang2222/ReadWithMe
캡스톤 디자인I에서 진행했던 프로젝트 중 내가 맡았던 Gaze Estimation 파트에 대해 간단히 기록 남기려고 한다
코드는 위 git 링크에 올려놨으나 readme 부분을 살짝 덜 쓰긴 했다
프로젝트 개요

Gaze Estimation, OCR (Optical Character Recognition), 그리고 ChatGPT API를 결합하여 사용자의 브라우징 편의성을 높이는 확장 프로그램 개발
목표
- 사용자가 바라보는 위치의 좌표값 추정
- 좌표값에 해당하는 텍스트 추출
- 해당 텍스트 관련 ChatGPT 질의응답 결과 제공
프로젝트의 종합적인 목표는 사용자의 브라우징 편의성을 최대한 높이는 것이다. Gaze Estimation을 사용하여 사용자가 마우스를 움직이지 않고도 시선만으로 원하는 요소를 선택할 수 있도록 한한다. OCR을 통해 이미지에 포함된 텍스트를 인식하고 해석하여 사용자에게 제공함으로써, 정보 접근성을 향상시킨다. ChatGPT API를 통해 사용자가 웹 페이지와 상호작용하면서 발생하는 의문이나 질문에 대한 답변과 추가 정보를 제공하여 사용자 경험을 개선한다.
개발 내용
전체적인 pipeline
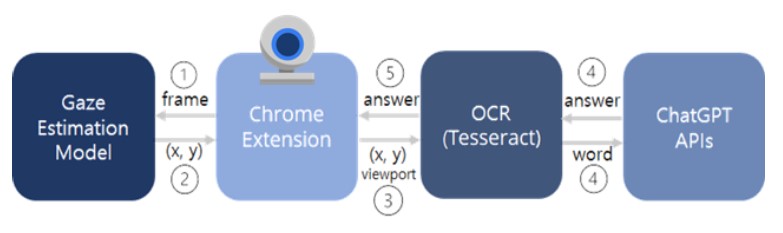
Gaze Estimation
-
extension 서버에서 웹캠으로 입력받은 사용자에 대한 이미지 frame을 전달받아서 이를 통해 사용자가 화면의 어느 위치를 바라보고 있는지를 찾고 그 좌표 값을 OCR 서버로 넘겨주게 된다.
-
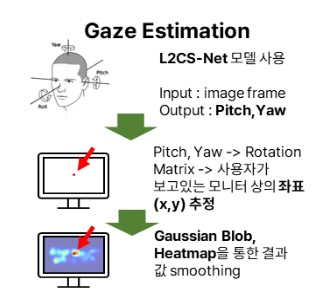
Gaze Estimation을 통한 사용자의 시선 좌표를 추적하기 위해서 L2CS-Net 모델을 사용하기로 하였다. 이 모델은 입력으로 사용자의 얼굴이 포함된 이미지가 들어왔을 때에 사용자의 시선 방향 벡터를 반환하게 된다. 이 때, 사용자가 바라보고 있는 좌표가 아닌, 사용자의 시선의 Pitch 값과 Yaw 값을 반환하기 때문에, 이 두 값과 사용자와 화면의 거리를 통해서 좌표를 추출해 낼 수 있어야 한다.
-
이를 위해서 Pitch와 Yaw값으로 rotation matrix를 구해서 사용자의 시선의 끝이 위치하는 화면의 좌표를 찾아 내었다.
R_x = np.array([[1, 0, 0], [0, cp, -sp], [0, sp, cp]]) R_y = np.array([[cy, 0, sy], [0, 1, 0], [-sy, 0, cy]]) R_z = np.array([[cr, -sr, 0], [sr, cr, 0], [0, 0, 1]]) # 회전 행렬들의 곱으로 최종 회전 행렬 계산 rotation_matrix = np.dot(R_z, np.dot(R_y, R_x))``` -
또한 rotation matrix를 이용해서 좌표를 구하기 위해서는 사용자의 눈과 웹캠사이의 거리도 이용해야한다. 여기서 우리는 사용자들이 평균적으로 40cm의 거리를 두고 사용한다고 가정을 하였다.
아래와 같이 rotation matrix와 사용자의 눈의 위치를 이용해서 화면의 좌표를 구할수 있었다.
moved_point = np.dot(rotation_matrix, origin)
factor = (40/2.54*138)/ moved_point[2]
new_point = np.array([moved_point[0]*factor, moved_point[1]*factor,moved_point[2]*factor])
new_x = int(new_point[1]) + int(x_min + bbox_width/2.0)*1600/640
new_y = int(-1*new_point[0]) + int(y_min+bbox_height/3.0)*1200/480
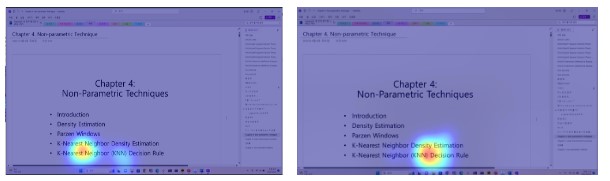
new_z = int(new_point[2])- 아래와 같은 화면에서, 화살표 방향으로 시선이 이동할 때, 우리의 모델이 예측한 시선의 좌표는 오른쪽과 같다.

위의 예시에서 볼 수 있듯이, 모델이 예측한 이 좌표만을 사용하기에는 어려움이 있었다. 좌표가 상당히 흔들리기도 하였고 텍스트들 사이에는 간격이 좁기도 하고, 텍스트가 아닌 여백 부분을 예측해 버린다면 OCR에서 원하는 것과는 다른 텍스트를 추출해 버릴수도 있었다. - 이 점을 해결하기 위해서 Gaussian Blob을 사용해서 정해진 시간동안 사용자의 시선 집중도를 통해서 smoothing 하는 방법을 사용하기로 하였다. 이 방법을 테스트해보기 위해서, 10프레임동안 gaussian blob의 가중치를 쌓고, 이 가중치에 따라서 픽셀별로 색을 표시하였다.
모델 성능
L2CS-Net Github(Ahmednull/L2CS-Net: The official PyTorch implementation of L2CS-Net for gaze estimation and tracking (github.com))에서 제공하는 pretrained 모델을 사용했기에 해당 논문(2203.03339.pdf (arxiv.org)) 에서 제공하는 성능 지표로 gaze estimation 품질 검증을 대체한다. 사용한 평가 지표는 gaze angular error로 ground truth gaze vector g와 predicted gaze vector g 사이의 오차 각도를 계산한다. 각 벡터는 3차원 벡터이다.
Gaze360 데이터 셋으로 mean angular error를 계산한 결과 정면측 180° 범위 내의 데이터에서 10.41°, 그리고 정면 데이터 셋에서는 9.02°를 기록했다.
해당 프로젝트에서는 L2CS-Net의 output인 pitch, yaw 값을 그대로 사용한 것이 아니라 rotation matrix로 변환한 후 사용자와 모니터 사이의 거리를 통해 pixel 좌표로 변환하는 과정을 거쳤다. 따라서 이에 대한 추가적인 오차가 발생할 수 있다. 사용자와 모니터 사이의 거리 1cm당 1.4pixel의 오차가 발생한다.
gaze estimation의 성능이 매우 중요한 프로젝트였고 단순한 시선 벡터가 아닌 픽셀 단위의 정교한 좌표 값이 필요했었다. 모델 성능 향상을 위해 추가적인 학습도 진행했었지만 큰 성과가 없었으며 이는 특별한 장비나 환경 설정 그리고 calibration 없이 추정하는 과정인 만큼 모델과 성능과 해당 기술의 한계라고 생각한다. 그러나 장비나 별도 프로세스 없이 웹캠을 몇초 보는 과정을 통한 간단한 calibration과 히트맵을 통해 성능을 크게 올릴 수 있었으며 OCR 단에서 진행한 알고리즘으로 인해 어느 정도 해결할 수 있었으므로 의미있는 결과라고 생각한다.
향후 개선방안
모델 성능이 가장 아쉬운 점으로 남는다. 이를 개선하기 위해 해당 프로젝트에서 사용한 pretrained 모델이 학습한 Gaze360이 아닌 MPIIGaze 데이터 셋으로 추가적인 학습을 진행하였다. gaze 360 데이터 셋은 사용자가 360’ 다양한 각도를 보고있는 사진으로 구성되어있으며 MPII GAZE 데이터 셋은 노트북의 화면의 특정 점을 보고있는 사진들로 구성되어 있다. 노트북 화면 상의 어디를 보고있는지 측정하는 해당 프로젝트에는 MPII GAZE 데이터 셋이 더 적합하다고 생각하여 성능 향상을 기대하고 학습을 시켜보았지만 오히려 성능이 떨어지는 것을 확인할 수 있었다. 이후 calibration과 heatmap을 통해 보완하였고 해당 방법들이 효과적이었지만 그럼에도 모델의 자체적인 성능을 올리는 것은 해결하지 못하였다. 전문적인 측정 장비를 사용하지 않으며, 화질이 좋지 않은 웹캠을 사용한다는 점 그리고 calibration 없이 진행하며 주변 환경에 대한 제약사항이 없다는 점이 해당 모델의 성능에 영향을 미쳤다고 생각하며 이는 일상생활에서 쉽게 사용할 수 있다는 장점과 trade-off 관계이자 한계점이라고 생각한다.
