블로그에 포스팅하는 내용들은 강의 전체 내용이 아닌 내 기준, 나한테 필요한 내용들 기억하고 싶은 내용들 위주입니다
해당 내용의 출처는 LG Aimers(https://www.lgaimers.ai)에 있습니다
Part 1. 품질 및 품질비용
품질이란?
규격에 부합하는 것 -> 고객의 명시적/묵시적 요구를 충족시킬 능력이 있는 특징이나 특성의 전체
기업의 품질 우위는 경쟁력의 필수 요건일 뿐 아니라 시장확보 및 수익성 제고를 위한 기본 요건이자 전략 변수이다.
Total Quality
제품과 서비스는 아무리 훌륭해도 고객에게 수용되지 않으면 의미가 없다
즉 고객 지향적인 품질의 정의가 중요함.
제품/서비스의 품질(Quality) + 비용(Cost) + 납기(Delivery)
COPQ(Cost of Poor Quality)
저품질로 인한 총 비용
6시그마에서 개선 Project의 대상
Q-Cost(품질비용) + Hidden Cost(숨겨진 비용)
- 서비스 품질에 대한 소비자의 인식이 판매가격을 결정
- 고객 이탈율의 증가로 인한 기회 손실 비용 발생
품질 비용
- 생산자 품질 비용
a. 예방비용 : 처음부터 불량 발생 X
b. 평가비용 : 품질 수준을 유지하는데 발생
c. 실패비용 : 품질 수준 유지에 실패해서 발생- 내부 실패비용
- 외부 실패비용
- 사용자 품질 비용
a. 소비자 부담비용
b. 소비자 불만비용
c. 명성상실 비용 - 사회적 품질 비용
- 새로운 품질 개념
불량을 만들지 않는 process 구축
검사, 재작업, 폐기 비용 등의 loss를 줄이는 개념
변동
- 이상원인
- 비정상적 요인
- 개별적 요인
- 큰 변동
- 우연 원인
- 정상적 상태에서 존재
- 많은 개별적 요인
- 작은 변동
우연변동만이 존재한다면 시간에 대해 안정되고 예측이 가능하나 이상변동도 존재한다면 불안정되고 예측 불가해짐
(94%의 우연 변동과 6%의 이상변동)
Part 2. SPC의 필요성과 개념
SPC (Statistical Process Control, 통계적 공정 관리)
input으로 4M(Man, Machine, Material, Method)
output으로 제품/서비스
요구사항을 파악하는 공정의 소리 VOP,
변화하는 고객요구의 기대치를 다시 input에 반영하는 VOC
이를 feed-back
+
sensor/ iot를 통해 실시간으로 반영 --> Online Feed Back
품질 : 4M
품질관리(QC) 7가지 도구 :
1. 파레토 차트
2. 특성요인도
3. 체크시트
4. 히스토그램
5. 산점도

6. 그래프
- 데이터의 최소값, Q1(1사분위 값), 중앙값, Q3(3사분위 값), 최댓값
- 3 sigma rule
7. 관리도
Part 3. 스마트 품질 경영

1 군집분석
군집 분석을 통하여 유사성이 높은 변수를 군집으로 분류
군집의 수는 트리 다이어그램을 통해 결정
분류된 군집에서 대표 공정변수 추출
- 단 각 군집 내에서 변동이 가장 큰 변수를 대표 공정 변수로 추출
2 회귀분석
가정된 회귀모형을 통해 품질 계측치의 예측 또는 통계적 추론을 하는 분석기법
- R^2 : 변동의 비율(0.8 이상이면 설명력이 높다고 판단) 회귀 선에 얼마나 가깝게 분포하는지
- RMSEP : 평균예측오차(작을수록 예측력이 좋다고 판단)
3 변수 선택법
영향을 주는 공정변수를 선택, 영향을 주지 않는 공정변수 제거
R^2값이 유사하며 RMSEP가 더 좋아진다면 올바른 변수를 선택
4 기여도 분석
Part 4. 신뢰성 개념과 중요성
Part 5. 신뢰성 분포와 신뢰성 척도
신뢰성
주어진 작동 환경에서 주어진 시간 동안 시스템이 고유의 기능을 수행할 확률
1. 지수분포
지수분포의 무기억성 : 시간 t와 관계없이 원래의 평균 수명과 동일하다. 즉 지수분포를 따르는 제품은 작동하는 동안에는 늘 새 것과 같음
일반적으로 사건이 1건 발생하는데 걸리는 시간에 대한 분포로 사용.
발생빈도에 따라 1개의 사건이 발생하는데 걸리는 시간이 확률 변수
포아송 프로세스에서 도착시간 간격은 지수분포를 따름
- 사용된 제품은 확률적으로 새 것과 같음 -> 예방보전으로 미리 교체할 이유가 없음
- 여러 다른 부품으로 구성된 시스템의 수명분포는 근사적으로 지수 분포를 따름
2. 감마분포
포아송 프로세스를 따르는 사건이 k개 발생하는데 걸린 시간의 확률 분포
3. 와이블분포
신뢰성 데이터 분석에 가장 널리 사용
형상모수가 1인 경우 와이블 분포는 지수분포와 동일
고장률 함수에서 베타가 1인 경우 고장률 일정(지수 분포) / 1보다 큰 경우 고장률 증가 / 0보다 크고 1보다 작은 경우 고장률 감소
- 시간에 따른 제품의 동작을 와이블 분포로 모형화하면 제품의 수명에 대한 다양한 정보를 획득함
- weakest link 법칙
- 부품의 수명분포에 주로 사용됌(지수함수는 시스템의 수명분포)
4. 정규분포
특히, 평균이 0 분산이 1인 정규분포를 표준정규분포라고 함
n(추출된 표본 개수)이 충분히 크다면 표본평균의 분포는 근사적으로 정규분포를 따름
5. 대수정규분포
다양한 형태의 분포를 표현 -> 경험적 모형으로 폭넓게 사용
정규분포의 다양한 성질 사용
곱셈형 충격의 누적 효과로 인해 고장이 발생하는 현상에 대해 대수정규분포가 유도
6. Bernoulli 이항분포
결과값이 독립적으로 성공과 실패(0,1)로 나누어지는 경우
7. 푸아송분포
발생빈도에 따라 단위 시간동안 발생하는 사건의 수가 확률 변수
Part 6. ICT기반 예지보전
보전
1. 사후 보전
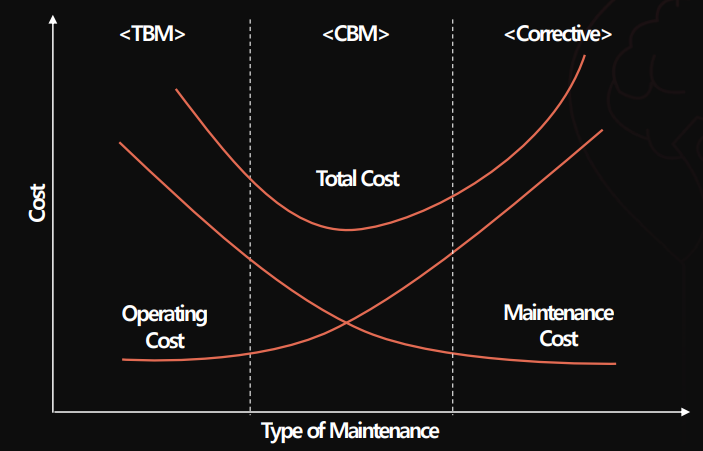
2. 예방 보전
- 시간기준보전(TBM)
- 상태기반보전(CBM)
- 목적은 무엇인가? ( 고장을 예지, 불량을 예지)
- 유닛 단위인가 부품 단위인가?
- 성능열화상태는 알 수 있는가?
- 파라미터로서 생각할 수 있는 것은 무엇인가? (변위, 속도, 가속도 등)
- 파라미터의 측정 방법은 어떤 것인가?
- 정기적으로 장비 측정
- 파라미터와 열화간의 상관관계는 존재하는가?
- 잠정 기준 (threshold) : 열화 정도로 추정하여 잠정 한계 기준값을 설정한다
- 잠정 기준을 벗어난 것을 분해 조사, 상태 체크
- 상관 관계를 입증
- 경향 관리 시스템 구축
신호 전처리 프로세스
- 퓨리에 변환
선형 변환 - 웨이블릿 변환
신호 데이터의 전처리 및 노이즈 제거, 데이터 축소
신호 데이터를 다른 주파수 성분을 분해하는 비선형 변환 웨이블릿 계수의 특징 추출 방법에는 hurst exponent(허스트 지수)
웨이블릿 계수의 분산에 대한 기울기, 회귀 분석으로 추정
특정 구간에서 신호 데이터의 특징을 대표
- PCA
다차원 데이터로부터 차원을 축소, 특성을 추출
잡음 데이터에 강건, 변수간 상관관계를 가지는 문제를 해결, 유의미한 축소 가능
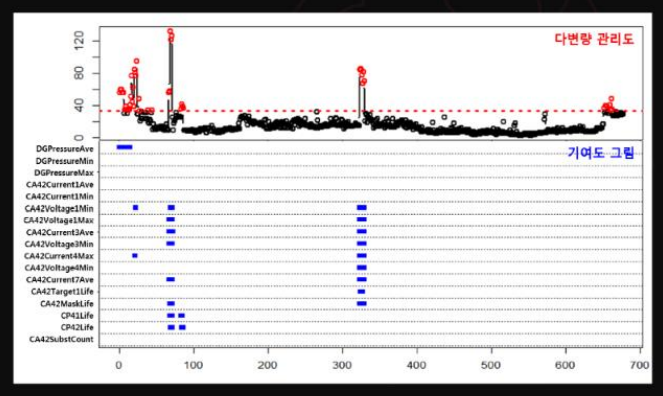
다변량 관리도는 변수 간의 상관관계를 고려할 수 있고 다수의 변화를 동시에 탐지함
다변량 관리도 중 가장 많이 사용되는 관리도는 Hotelling의 T2관리도 -> 추정 통계량이 관리 상한선을 초과한 경우 이상 발생으로 판단
인공신경망(CNN,AE) / 서포트백터머신 활용
ex) CBM(PSM Lab)
신호 측정 -> 웨이블릿 변환(thresholding rule, hurst exponent) -> 다변량 관리도 (hotelling's T^2 관리도)
