블로그에 포스팅하는 내용들은 강의 전체 내용이 아닌 내 기준, 나한테 필요한 내용들 기억하고 싶은 내용들 위주입니다
해당 내용의 출처는 LG Aimers(https://www.lgaimers.ai)에 있습니다
Part 1. SL Foundation
Supervised Learning(Labeled Data)
- Regression
- Continuous output- Classification
- Discrete output
Unsupervised Learning(Unlabeled Data)
- Clustering
- Dimensional reduction
Data set
입력 x, 출력 y(label, target)
x에서 y로 가게되는 h를 학습
Phase 1 : training
우리가 가지고 있는 label(정답)으로부터 이 모델이 출력을 정확히 맞추는지 아닌지 알려줌
model의 parameter를 변경, 정답과 예측간의 error를 줄여가는 방향으로 학습
Phase 2 : test
train 단계에서 보지 못했던 새 입력으로 testing
model을 learning하는 과정
- feature selection
- model selection
- optimization
Machine Learning은 그 자체로 Data의 결핍으로 인한 불확실성을 포함하고 있다
따라서 가장 중요한 것 중 하나는 Generalization이다.
training error, validation error, test error를 통해 Generalization Error E를 최소화하도록 노력
data sample에서 발생하는 모든 sample들의 pointwise error를 합쳐서 loss function(overall error, cost function)을 만듬
- E(train)
model을 주어진 data set에 맞춰 학습하는데 사용하는 error. 즉 주어진 sample에서 model parameter를 최적화하도록 함 -> E(general)을 근사하는데는 적합X
training sample과 overlap 되지 않도록 전체 data set에서 일부 sample을 따로 빼서 test sample 정의
- E(test)
model이 real world에서 적용할 때 나타나는 E(general)를 표현
E(test)를 0으로 근사하게 한다면 E(general) 역시 0으로 근사하지 않을까?
1. E(test)가 E(train)과 가까워지도록 학습
일반적인 성능을 갖게 함 (분산이 작게)
그러나 overfitting이 발생할 수 있음.
더 많은 data를 사용하거나 정규화를 함
2. E train이 0에 가까워지도록 학습
모델 정확도가 올라간다 (편차가 낮아진다)
그러나 underfitting이 발생할 수 있음.
더 복잡한 모델을 쓰거나 최적화를 해야함
model의 정확도 증가 = bias 감소, model의 일반성 증가, variance 감소
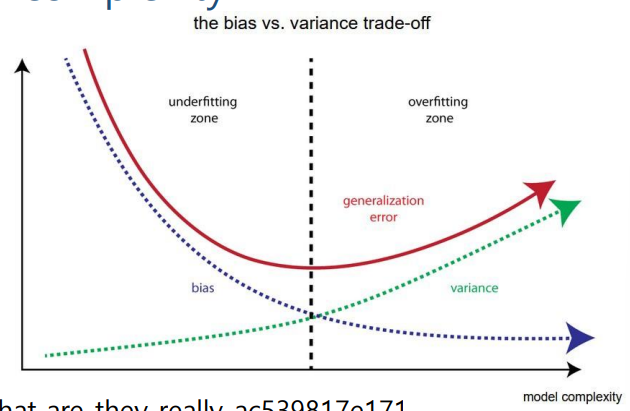
bias와 variance의 trade off
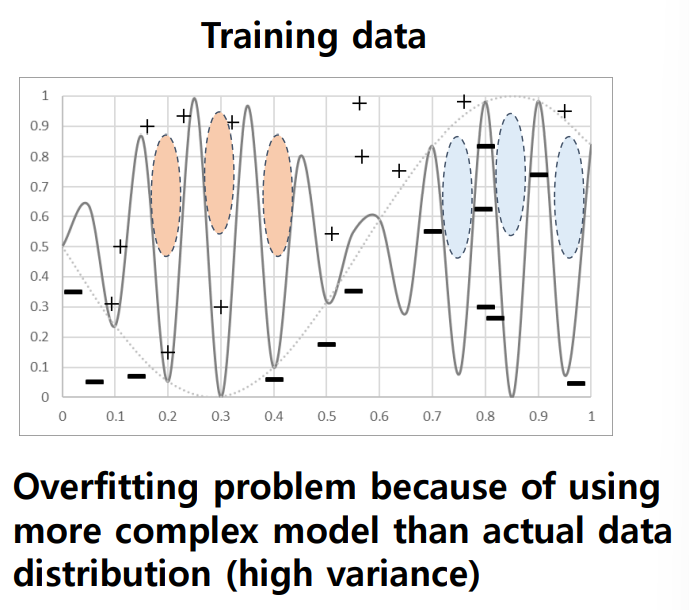
모델이 복잡해지면 overfitting 발생이 쉽고 bias는 줄지만 variance가 증가해서 일반화가 어려움
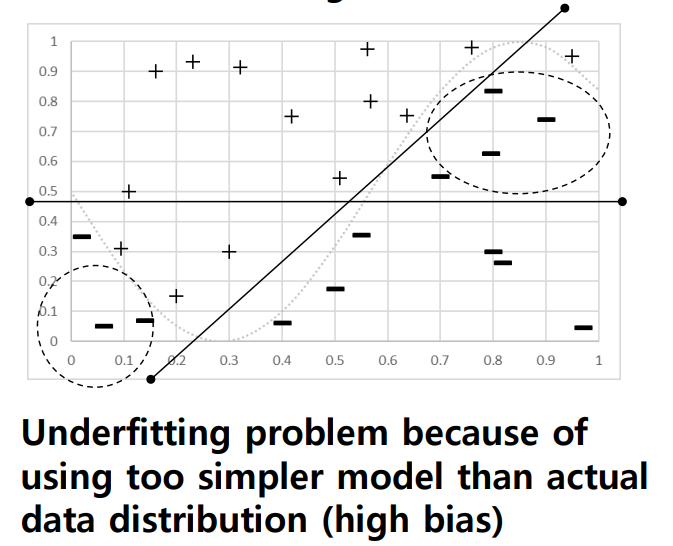
모델이 단순하면 underfitting 발생이 쉽고 bias가 높아져서 우수한 성능을 제공하기 어려움
Curse of dimension
복잡도가 증가하는 속도에 비해 Data sample 수는 쉽게 늘리지 못한다 : overfitting 문제가 큼
해결 방법
- Data를 늘린다
- Data augmentation : 변형하거나 생성함
- Regularization
- Ensemble
Cross-validation(CV)
training set를 K개 그룹으로 구분, k-1개를 train 나머지 1개를 validation에 사용
training은 model parameter fitting, validation은 model 최적화
모델 일반화에 도움
Part 2. Linear Regression
resgression은 모델 출력이 연속적임
선형 모델의 장점
쉽고 단순하다 = 일반화가 가능하다
입력변수의 해당 요소가 출력에 어느정도의 영향을 주는지 예측이 가능함
linear regression
주어진 입력에 대해 출력과의 선형적인 관계를 추론하는 문제
단 입력 변수가 선형일 필요는 없다
곱해지는 세타(파라미터)에 대해 선형이란 뜻
보통 loss function으로 MSE를 사용
파라미터를 구하는 방법
- Normal equation
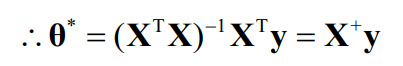
one step 방식
data sample 숫자가 늘어나는 경우 비효율적임 - Gradient descent algorithm
iterative 함
greedy method : 현재 지점에서 변화도가 가파른 방향으로 update
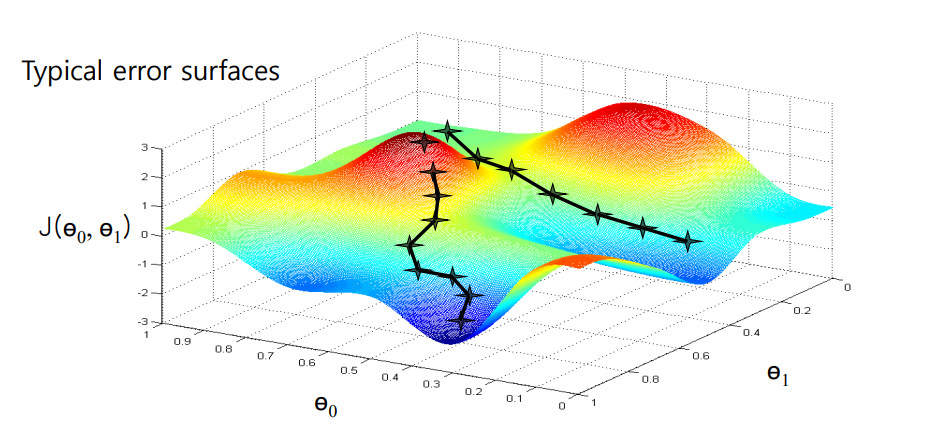
local optimum을 달성하기 쉽다
global optimum을 보장하지 못한다(stochastic gradient descent, mini batch algorithm을 통해 해결)
알파(learning rate)가 너무 작으면 수렴하는데 오랜 시간이 걸림
알파가 너무 크면 graident가 0인 지점을 놓치기 쉬움
Part 3. Gradient Discent
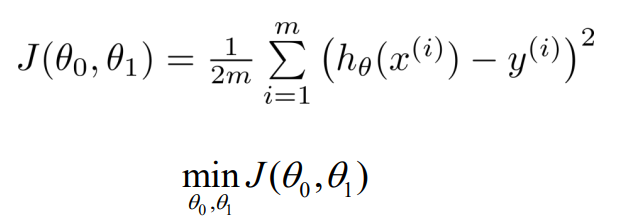
loss function을 최소화하는 ɵ0, ɵ1를 구하는게 목적
- inital ɵ0, ɵ1 값으로 시작
- loss function이 감소하는 방향으로 최소값까지 파라미터 변경
Gradient Descent Algorithm
gradient : 벡터 함수의 partial derivative 값. 함수의 변화량이 가장 큰 방향으로 update
알파 : parameter update의 정도를 조절. 학습 이전에(사전에) 설정.
세타 : learnable parameter
알파가 작을 때 : 수렴 형태가 안정적임.
알파가 클 때 : 최소의 지점을 찾기 어려움. 발산 형태. error loss가 늘어남 (학습이 진행되지 않고 있다)
Batch gradient descent
ɵ0, ɵ1를 수정하는 과정에서 모든 sample을 고려해야한다는 단점 존재
m, 즉 데이터가 증가할 수록 복잡도가 늘어남
Stochastic gradient descent(SGD)
m을 극단적으로 1로 줄임
빠르게 iteration을 돈다는 장점
각 sample 하나하나로 연산하다보니 noise의 영향을 크게 받는다는 단점
>>gradient algorithm은 local optimum에 빠지기 쉬움<<
이를 해결하기 위한 변형 algorithm
1. Momentum

과거 Gradient가 update 되어오던 방향/속도를 반영(ρ)하여 현재 point에서 gradient가 0이더라도 계속해서 학습을 진행
과거의 gradient를 누적해서 계산. 현재 시점에서 멀면 멀 수록 ρ값을 연속적으로 곱해짐.
ρ의 값은 1보다 작다. ρ를 연속적으로 곱하면 더 작아짐.
먼 과거의 값은 더 작아지고 가까운 과거 값은 적게 작아짐
--> exponentially weighted moving average
현재 포인트의 saddle point나 noise gradient 변화에 보다 안정적으로 수렴
SGD + momentum
2. nestrov momentum
gradient를 먼저 평가하고 update 함 --> look ahead gradient step
3. AdaGrad
각 방향으로 learning rate를 적응적으로 조절하여 학습 효율을 높임
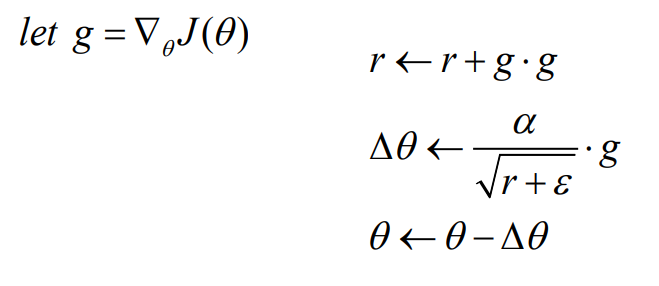
r은 gradient의 제곱, 즉 합이 누적이되면서 값들이 점차 커짐
반면 델타 세타를 update하는 과정에서 분모로 들어감으로서 델타 세타 값은 점점 작아짐
r, 학습이 많이 진행되어서 값이 크다면, 델타 세타 값이 작아져서 수렴 속도를 줄임
gradient 값이 계속해서 누적되어 learning rate 값이 작아짐. 즉 learning rate가 0에 수렴하여 학습이 그 지점에서 진행되지 않는다는 단점 존재.
4. RMSProp algorithm

r에 ρ값을, gradient 제곱에 (1-ρ)를 곱하여 r의 값을 조절
AdaGrad와 같이 극단적으로 gradient 값이 누적됨에 따라 세타 값이 줄어드는 것이 아니라 어느 정도 완충된 형태로 학습 속도가 줄어듬
5. ★Adam(Adaptive moment estimation)★
RMSProp + Momentum 방식
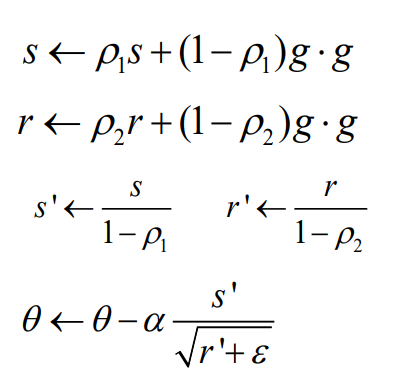
1. 첫번째 moment를 momentum 방식으로 계산
2. 두번째 moment를 RMSProp 방식으로 계산
3. bias를 고침
4. parameter update
Learning rate scheduling
하이퍼 파라미터 α를 학습과정에 따라 조정
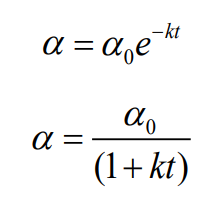
α를 학습 과정에 따라서 점차 줄여나감
초기에는 학습을 빠르게 진행하다가 learning rate를 점차 줄여서 학습함
Model 과적합(overfitting) 문제
model이 지나치게 복잡해서, learning parameter의 숫자가 많아서 제한된 셈플에 너무 과하게 학습이 되는 것
입력 feature의 숫자가 지나치게 많아지면, parameter 개수가 증가, curse of the demension problem에 의해 data 개수가 더 많아진다. 그러나 현실에서는 data 증가에 한계가 있기 때문에 overfitting이 발생. + mean squared error는 noise, outlier에 민감함
Regularization
모델의 복잡도에 대한 패널티를 줌
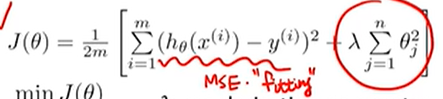
세타 j 값이 크면 클 수록 늘어나게 되는 오류
즉 모델 입장에서 가능한 세타를 사용하지 않으면서 loss를 최소화 하려고 노력
세타 값을 쓰지 않는다 = 어떤 특정한 세타 값들이 덜 중요하다면 0으로 보내버림 = 파라미터 개수를 줄임 = 모델의 복잡도가 줄어듬
