블로그에 포스팅하는 내용들은 강의 전체 내용이 아닌 내 기준, 나한테 필요한 내용들 기억하고 싶은 내용들 위주입니다
해당 내용의 출처는 LG Aimers(https://www.lgaimers.ai)에 있습니다
Part 4. Linear Classification
classification은 discrete output을 가짐 = category를 구성하고 분류
binary classification
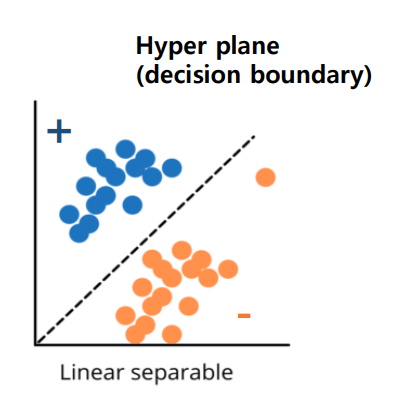
hyper plane을 구해서 dataset의 positive, negative sample을 linear combination에 의해서 구분
multiclass classification
hyper plane이 다수 존재
*score 값이 동일하다면, 해당 점에서 hyper plane까지 투영한 거리가 동일하다는 의미
- Which predictor?
hypothesis class- Loss fuction을 통한 predictor 성능 평가
Zero-one loss
Hinge loss
Cross-entropy loss- Optimization algorithm
Gradient descent algorithm
parameter W를 학습한다 -> W에 따라서 sample들의 판별 결과가 바뀜
- score 값은 결정 과정에서 model이 얼마나 confident한지를 측정
- margin은 score * y. 정답을 맞췄을 때 margin값이 증가하고(score가 1이고 정답도 1, score가 -1이고 정답도 -1), 틀렸을 때는 margin이 감소)
zero-one loss를 gradient descent algorithm에 적용하려면 loss function의 partial derivative term을 구해야함
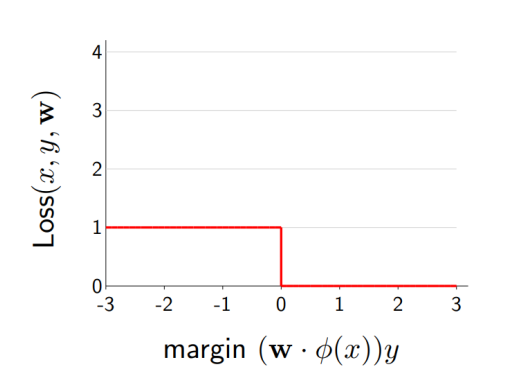
문제점 : 미분하면 모든 곳에서 기울기가 0이 됌
Hinge loss 를 사용한다
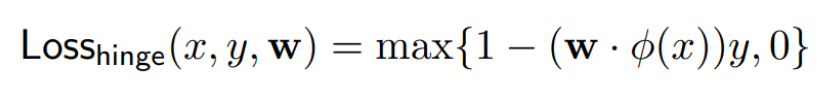
(1-margin) 값과 0 중 큰 값을 택함
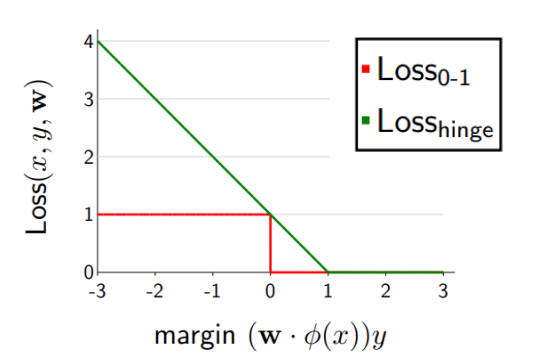
- 모델이 잘 예측하고 있어서 margin>0이라면 1-margin<0 이므로 그래프에서 0인 뒷 부분
- 모델이 틀리고 있어서 margin<0이라면 1-margin>0이므로 선형적인 앞 부분
Cross-entropy loss
classification model 학습에서 가장 많이 쓰는 대표적인 loss임
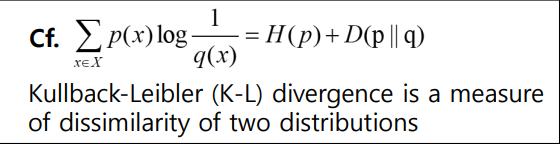
H(p) 즉 entropy 부분은 잘 바뀌지 않으므로 K-L divergence 부분에 의해 영향 받음. K-L divergence는 두개의 서로 다른 pmf 의 차이.
즉 cross-entropy 역시 두 개의 서로 다른 pmf p와 q가 유사한지 그렇지 않은지에 따라 error가 바뀜
- p, q가 유사 : loss가 줄어듬
- p, q가 다르다 : loss가 증가
지금까지 우리가 계산한 모델의 score 값은 실수 값임.
cross-entropy는 확률 값임.
따라서 실수 값을 확률 함수를 통해서 매핑을 해야함.
이때 매핑에서 사용하는 함수가 Sigmoid 함수.
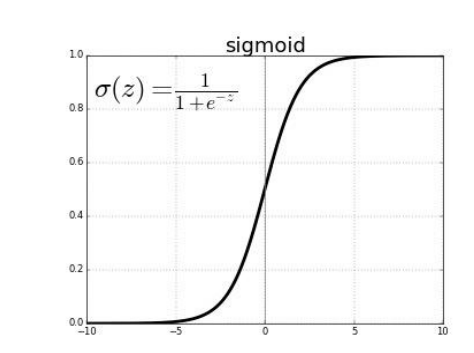
- + 방향으로 real 값이 증가시 확률값 1에 근사
- - 방향으로 증가시 확률값 0에 근사
- 0일 경우 1/2의 확률
= 실수 값을 0~1 사이 값으로 매핑 = logistic model
linear classifier 학습 과정
1. weight 초기화
2. gradient 계산
3. 움직일 방향 설정
4. update weight
5. 수렴할때까지 반복
Multiclass classification
One-VS-All
- binary classification을 multiclass classification으로 확장
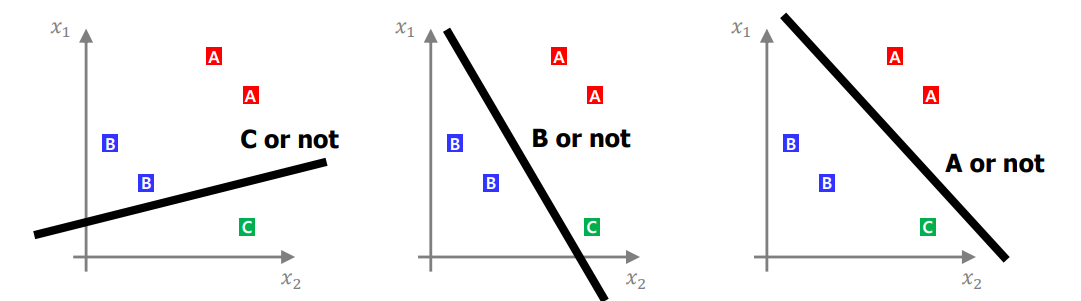
각각을 나누는 함수를 구하고 weight 값을 더하여 score를 구성
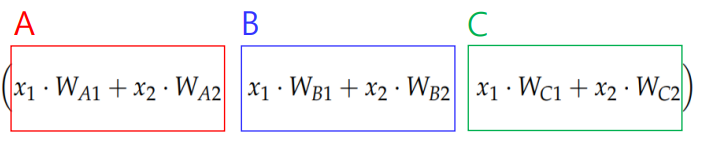
score 값에 sigmoid 함수를 사용하면 확률 값으로 매핑 가능
one hot encoding(두 개의 서로 다른 표 사이의 거리를 가깝게 하면서 학습)을 통해
one hot encoding 된 label 값과 sigmoid 함수가 출력하는 확률값을 비교하여 loss function을 통해 error를 개선해서 학습
장점
- 간단하다. 구현이 쉽고 테스팅이 쉽다. = 처음 시도하기 적합
- 해석 가능성(interpretability)가 좋다
Summary
- linear classification model에선, hyperplane이 decision boundary로 sample들을 classify하게 되며 이때 sample들은 선형적으로 분리가 가능하다고 가정한다. hyperplane은 입력변수와 파라미터의 linear combination이다.
- cross-entropy는 두 개의 서로 다른 pmf 사이의 dissimilarity를 측정하는 도구이다. 실수값은 sigmoid 함수 등을 통해 확률 값으로 매핑한 후 loss를 계산해야한다.
- binary linear classifier는 one-vs-all 방식(binary linear classifier를 여러개 사용함)을 사용하여 muticlass linear classifier로 확장할 수 있다
Part 5. Adavanced Classification
hyper plane을 선택하는데 많은 문제들이 발생
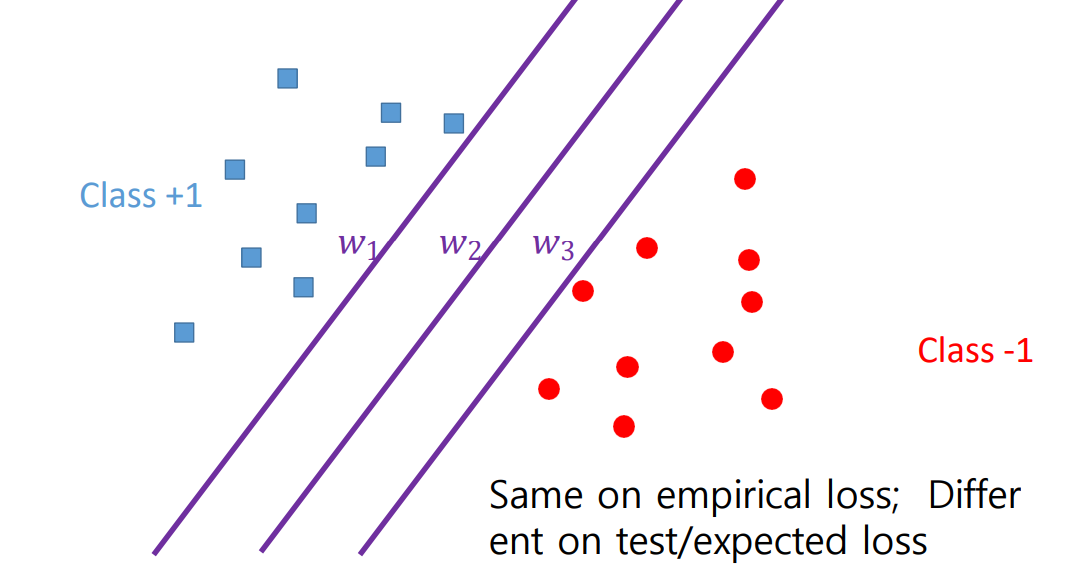
현재 존재하는 data sample들에 대해서는 유사한 loss를 제공할 것이다
그러나 실생활에 적용시 새로운 sample들이 생기며, 이에 대해서도 좋은 성능을 제공해야함
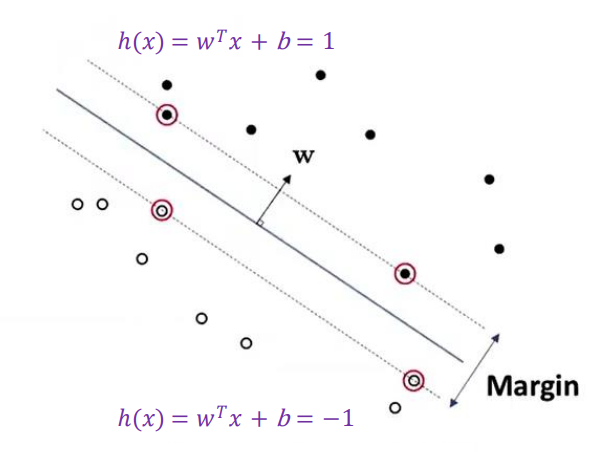
SVM (Supportive Vector Machine)
Margin
SVM에서 hyperplane을 결정하는 핵심적인 idea
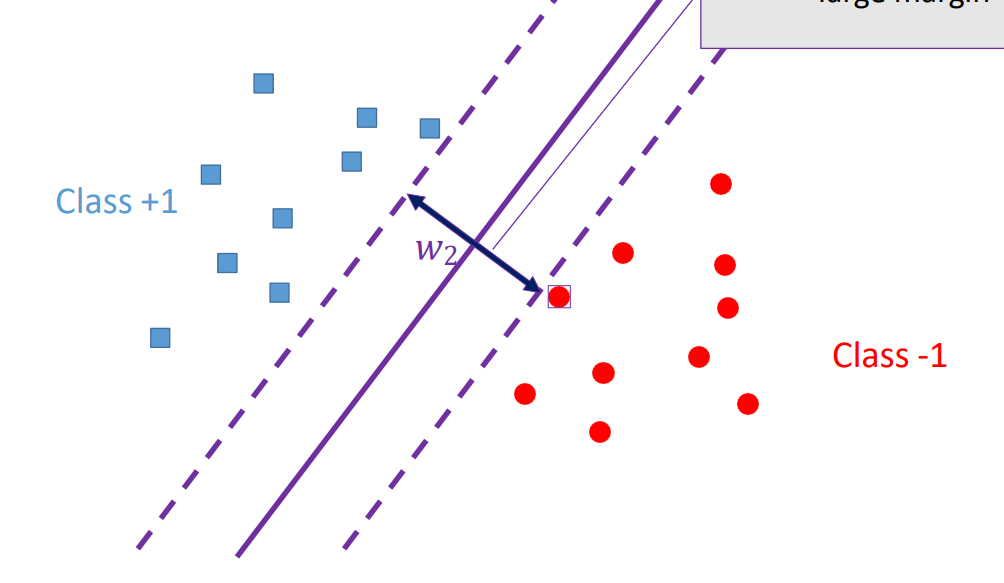
가장 hyper plane에 가까운 positive sample, negative sample을 지나가는 점선 2개 사이의 가장 가운데(서로간의 위치가 동일한)있는 hyper plane이 최대 margin을 갖는 최적화임
Support vector
positive sample/negative sample들과 hyper plane 사이의 거리 중에서 가장 가까운 margin을 갖는 vector, 결국 성능을 좌지우지하는 민감한 data point
이러한 support vector 사이의 최대 margin을 갖는 hyperplane을 선택
outlier들에 대해서도 보다 안정적인 성능을 제공함
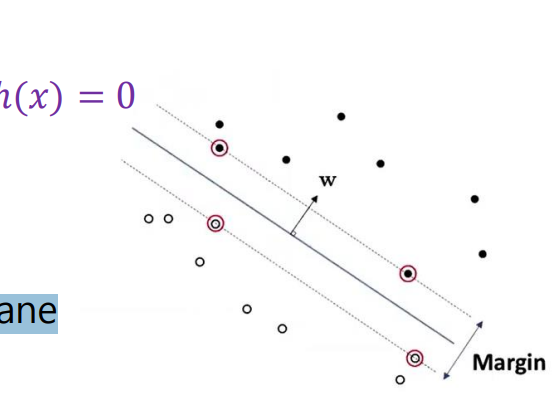
가운데 있는 hyperplane은 h(x)=0이다.
hyperplane에서 가장 가까운 support vector 간의 거리는 한 vector의 길이의 2배이다.
model parameter W는 hyperplane의 nomal(직각, orthogonal)한 방향으로 설정됌.
margin 즉 hyper plane으로부터 떨어져 있는 support vector 간 거리를 최소화하기 위한 optimization 방식
- Hard margin SVM
sample들이 linear separable함 = support vector 두 개 사이의 영역에는 어떠한 sample도 없다는 것을 가정- Soft margin SVM
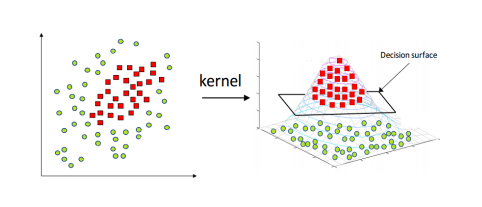
어느정도의 error를 용인- Nonlinear transform & kernel trick
SVM은 linear한 vector들을 사용. 즉 linear한 상황에서만 사용가능한 단점을 극복. kernel을 이용하여 2차원의 sample을 고차원으로 매핑.
Hard margin SVM
이때 y*score 즉 y(w^Tx+b)는 항상 1보다 크거나 같다
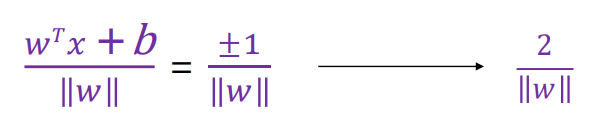
전자는 hyper plane에서 support vector까지의 거리이다. positive sample에서 hyperplane까지의 거리와 negative sample에서 hyperplane까지의 거리는 동일하므로 2/||w||라고 나타낼 수 있다.
margin 값을 maximization 해야한다
즉 ||w||를 minimize 해야한다. 다시말해서 w^2를 minimize 해야한다.
SVM Primal problem
||w||^2를 minimize 하자.
y(w^Tx+b)>=1 즉 constrained optimization 문제를 푸는 것으로 바뀐다
Kernel 함수
linearly seperable 하지않은 data sample들이 있다고 할 때, 그 차수를 높여서 linearly separable하게 만든다
- polynomial
- Gaussian radial basis function(RBF)
- Hyperbolic tangent (multilayer perceptron kernel)
ANN
nonlinear classification model을 제공
DNN의 기본
고유한 파라미터를 이용한 linear combination을 통해 score 값을 만들어낸다
Activation function는 linear한 score를 입력으로 받아들여 sigmoid 함수 등을 통해 non linear하게 mapping 해줌
activation functions
- sigmoid
depth가 늘어갈 수록 효과적이지 못하다
z가 매우 크거나 작은 경우 gradient가 작아져서 학습량이 줄어든다 - ReLU
gradient 값이 1로 유지
Multilayer Perceptron(MLP)
DNN
계층에 따라서 학습을 하게되는 feature의 형태가 달라짐
그러나 accuracy가 낮아지는 문제가 발생
Gradient Vanising Problem
모델 학습 과정에서, 계층이 깊어질 수록 학습 parameter가 줄어들면서 깊은 layer에 대해선 학습이 효과적으로 진행되지 못함
breakthough
- pre training + fine tuning
- CNN
- dropout
Part 6. Ensemble
Ensemble Learning
알고리즘의 종류에 상관 없이 다양한 머신러닝 모델을 묶어 함께 사용하는 방식
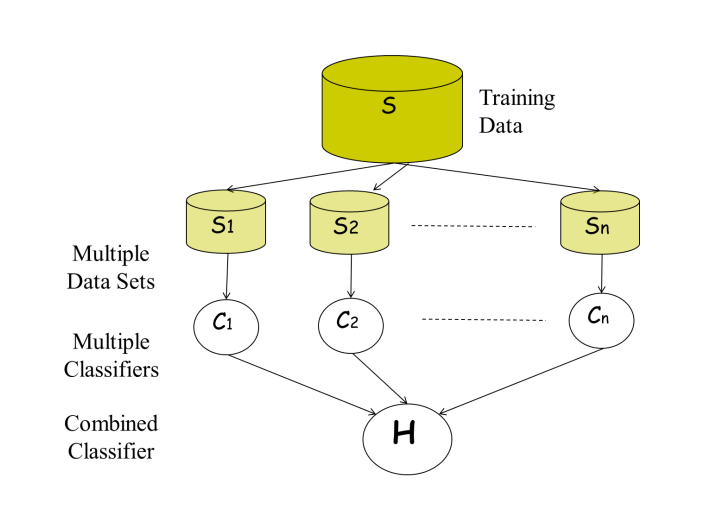
Dataset을 random하게 n가지로 나눠 학습을 진행, 다수의 모델이 각각 내린 결정을 다수결로 최종 결과를 제공
장점
다양한 여러개의 model의 결정으로 최종 예측 결과를 제공하므로 보다 안정적이며 쉽게 구현이 가능
각 모델은 독립적으로 작동하기 때문에 parameter tuning이 많이 필요없음
단점
model을 여러개 사용하므로 compact한 표현이 어렵다
Bagging(Bootstrapping + aggregating)
학습 과정에서 training sample을 랜덤하게 나눠서 선택
subset들은 서로 다르게 구성
다양한 classifier들이 다양한 subset data로 학습되기때문에 모델이 같더라도 서로 다른 특성의 학습이 가능함
병렬적인 모델 학습 가능
overfitting에 대해서, sample을 random하게 선택하는 과정에서 data augmentation 효과를 가짐
- Bootstrapping
다수의 sample data set을 생성해서 학습하는 방법
Boosting
다음 학습에 이전 학습의 결과를 사용, sequential하게 동작
- Weak Classifier
Bias가 높은 Classifier
모델이 단순해서, 성능이 낮음
Cascading을 통해 연쇄적으로 연속적으로 작용하면 성능을 올릴 수 있다
Random Forest
Bagging과 Boosting을 활용한 대표적 algorithm
decision tree의 집합
Supervised learning에서의 model 성능 평가
- Accuracy
