블로그에 포스팅하는 내용들은 강의 전체 내용이 아닌 내 기준, 나한테 필요한 내용들 기억하고 싶은 내용들 위주입니다
해당 내용의 출처는 LG Aimers(https://www.lgaimers.ai)에 있습니다
Part 1. 전통기계학습과 딥러닝에서의 비지도학습
전통기계학습에서의 비지도 학습
- K-means Clustering
데이터를 몇 개의 cluster로 나누어서, 비교적 비슷한 특징을 가지는 cluster로 모으는 것 - Hirarchical clustering
- Density estimation
- PCA
디맨션을 줄이기 위한 기법
특징
- low dimensional data
- simple concept
- 믿을만 한가? cluster validation이 꼭 필요함(숫자적으로도 의미가 있는지)
여러 연구가 많이 진행되긴 했지만 실제 application에 사용하기에는...!
딥러닝에서의 비지도 학습
feature engineering
- by human
- creativity + domain knowledge
딥러닝의 목표는 feature engineering 부분을 인간이 더 이상 안하고
알고리즘 스스로 중요한 정보를 잘 정리하여 처리하는 것
representation learning
- by machine itself
- deep learning knowledge + coding
- trial and error
특징
- high dimensional data
- difficult concept
- deep learning
Representation : 정보를 어떤 식으로 정리/표현할 것인가
Part 2. Representation과 딥러닝
representation이 어떤 조건을 만족하고 어떠한 properties를 갖고 있어야 할까?
formal system 및 specific한 것들이 없음
representation이 underconstrain 되어있다
특별히 어떠한 조건을 맞춰야 좋은 성능이 나오는 것이 아닌, 표현 방법에 따라 조금씩 다른 결과를 주지만 성능은 대체로 좋다
- 간단한 SGD만 사용해도 좋은 성능을 준다
- representation에 원하는 특성을 입힐 수 있다(flexibility)
- representation이 학습되는 방향을 수학적으로/구체적으로 설명하기가 어렵다
일반적인 문제에서 good represenation이란?
(supervised)
nn이 어떤 정보를 어떻게 정리해야할지를 모름
(unsupervised)
task, 즉 하려는 일 조차도 명확하지 않음
이러한 근본적인 원인에 접근하지 못한 채
(General purpose) Downstream task를 정함
그러나 이게 unsupervised representation learning이 맞을까?
representation
- what we want?
formal definition
evaluation metrics
"Interpretable & Explainable Representations"
인간처럼, NN이 정말로 제대로 학습을 했다면 의미있는 방식으로 정보를 정리할 뿐만 아니라 규칙들을 찾아내고, 의미있는 정보의 종류도 분리를 해내는 것도 스스로 해낼 수 있어야할 것이다
"Intelligence Without Representation"
Intelligence가 반드시 우리가 이해할 수 있는 방식으로 정리된 정보가 있을 필요는 없다. 상관 없는 문제이다.
인간이 개입해서(pre-processing) 해결한 문제는, ai가 푼 문제가 아니다. 어떤 식으로 표현할지 등의 문제는 ai가 해결해야하는 문제이지, 인간이 관심가질 영역이 아니다.
이 경우, evaluation은 task를 통해 측정하며 representation은 don't care! 인간이 하는 것과 같던 말던 상관없는 문제이다
Part 3. Unsupervised Representation Learning
Pretext Learning
잘 정리된 representation, 유용한 정보를 만들기 위한 학습 Task
ex 
저런 식으로 이미지를 재배열해내는 모델을 만들되(supervised), 실제 모델은 다른 task에 이용됌(unsupervised). 즉 저런 학습을 통해 생성된 모델이 충분히 다른 일도 해낼 수 있으며 좋은 성능을 낸다
self-supervised learning
인간이 label을 만드는 노동력을 들이지 않고 스크립트 하나만으로 Supervised Data set을 만들어 문제를 푸는 것
ex 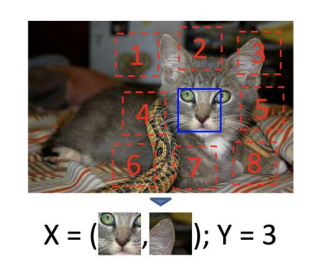
원래는 unlabeled 이미지였지만 label이 있는 문제로 바꿔버림
mutual information
variable 들 사이에 공유하는 정보의 양을 숫자로 계산해낼 수 있는가
multiview coding
같은 concept이라면(ex 같은 물체를 찍었다면) 어느 방향에서 찍은 사진이라도 결국은 같은 정보를 담고 있다. 따라서, NN을 통과시켜 정보를 정리한 activation 벡터는 비슷하게 생겨야한다
-> 따라서 augmentation을 통해 학습시키는...
Instance discrimination
개별 이미지를 하나의 class로 정의
augment한 이미지는 같은 class로