Operating Condition-Invariant Neural Network-based Prognostics Methods applied on Turbofan Aircraft Engines
1. Introduction
PHM(Programmostics and Health Management) 기술은 예측 유지보수의 핵심 요소로서, 계획되지 않은 다운타임을 방지하는 시기적절한 개입을 가능하게 하여 의사 결정 과정에 도움을 주어 운영을 더욱 안전하게 할 뿐만 아니라 비용 효과도 높일 수 있습니다.
이 연구의 초점은 예측, 즉 RUL 예측, 특히 신경망을 기반으로 한 기계 학습 데이터 중심 방법에 있다.
2. Literature review
Physics-based method : 모델 기반 방법이라고도 하며, 시스템 동작을 라고도 하며, 시스템 동작을 나타내기 위해 명시적인 수학 공식을 사용한다. 더 정확한 경향이 있긴 하나 시스템 동작에 대한 물리적 심층적 지식이 필요하며, 분석적이고 정확하게 설명이 가능하다고 가정하기 때문에 항상 가능하거나 비용 효율적은 아님.
Data-driven method : 블랙박스 모델 사용. condition monitoring data를 통해 학습하며 기대 지식을 요구하지 않는다. general-purpose model는 유연성을 허용하고 다른 문맥에 적용 가능하나, 데이터의 양과 품질에 따라 정확도가 달라짐
Hybrid method : phsics-based 와 data-driven 함께 사용
해당 논문에서는 data-driven을 사용. 여러 문헌들을 보면 다양한 prognostics approach에는 공통점이 있다.
1. 건강 지수 (health index)는 많은 저자들에 의해 사용된다. 그 다음, predictor feature를 HI에 매핑하거나 HI를 RUL에 매핑하는 두가지로 나뉜다.
2. 센서 노이즈는 항상 존재한다. moving average filter, kernel filter가 사용된다.
3. NN 아키텍쳐가 사용된다. CNN, RNN, LSTM 등
3. Methodology
데이터는 CMAPSS 사용. 다변량 시계열로 구성되며 시간이 지남에 따라 엔진의 성능이 저하되기 시작하며, 목표는 모델이 고장까지의 주기(RUL)를 예측하는 것.
train 세트에서 모든 시계열은 실패할 때까지 계속된다고 가정, test 집합에서는 데이터가 중지되기 전에 중지.
TEDS 데이터 세트에는 남은 사이클 수에 대한 실측 정보가 제공, PHM2008에서는 그렇지 않으므로 결과를 얻으려면 리포지토리 웹 사이트에 결과를 제출.
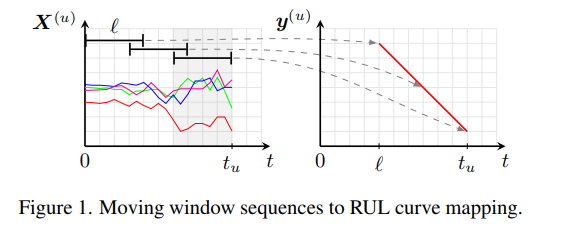
l 길이의 window로 u-th 엔진에서 시계열 경과에 따라 선형적으로 감소하는 RUL(스칼라 y)을 나타냄.
나머지는 operating condition과 데이터세트 얘기. 충분히 봤으므로 생략함
Data preprocessing
3가지의 전략이 사용됌. Feature selection은 시간의 흐름에 따른 개별 feature들의 행동을 시각적으로 검사해서 수동으로 수행한다.
세가지의 시나리오가 평가된다 : 모든 feature들을 유지, RUL과 직접적으로 상관 없는 feature들을 제거, 중복되지 않은 정보를 갖고 있는 feature만 남기고 대부분의 feature들이 제거.
Feature scaling은 gradient-based 학습 알고리즘의 convergence(수렴)을 개선하는데 바람직하다. Feature transformation은 처음 regular feature-wise standardization으로 수행되었다. 그러나, 예측이 operating conditino이 많은 영향을 미치는 것을 확인할 수 있다. 따라서 RUL과 연관된 모든 feature에 operating condition-specific standardization 방법이 사용된다.
K-Means가 각 데이터 포인트를 cluster에 배정하기 위해 사용된다. 그 다음 같은 cluster의 데이터들이 standardized 된다.
최상위 예측 알고리즘을 보면 모두 센서 노이즈 영향을 줄이기 위해 filter를 사용한다.
causal exponentially weighted filter - alpha가 낮을 수록 명확한 필터링을 제공하지만, longer delay가 도입된다.
targe RUL은 시계열의 마지막 부분에서 관측되므로, 선형 감소 추세를 가정하지 않고 earlier window는 임의로 정의된다. target RUL 곡선에 maximum RUL을 제한하기 위해 간단한 target transformation이 사용된다. 이 RUL 한계를 도입하면 초기 예측의 불확실성이 감소하여 모델을 더욱 신뢰할 수 있다. 130, 100, 80 cycle의 세가지가 사용된다.
Model Architectures
3가지의 NN이 사용된다.
처음은 MLP이다. 주목할만한 부분은, feature vector에 집중하여 다변량 input 시계열을 단일변량 input 시계열 배열로 flatten했다. MLP 구조가 단차원 입력만을 지원하기 때문이다.
두번째는 CNN이다. feature vector가 작아서, pooling을 포함할 필요가 없었다. 마지막에 적어도 한개의 fully connected layer가 사용되었다
세번째는 LSTM이다. 추가적 사항은 없다.
모든 아키텍쳐에 대해, number of layers, width per layer, filter length 등의 여러 구조들이 시도되었다.
Training and Evaluation
모든 실험에 대해 Adam optimizer가 사용되었다. train set은 train에 80% validation에 20%로 나뉜다. loss function은 MSE가 고려되었다. 예측 업무는 late prediction이 매우 좋지 않기때문에, asymmetric score는 late prediction에 불이익을 더 강하게 주도록 고려되었다. 또한 서로 다른 ㄷ이터 집합 간의 비교를 위해 표본 크기에 대한 불편함을 줄이기 위해 정규화를 진행한다.
Hyperparameter Search
해당 논문에서는 random search가 결과적으로 사용되었다. 매우 간단하고 계산적으로 저렴하며 중요하지 않은 매개변수들의 존재에도 불구하고 search space를 잘 탐색한다. 예를 들어 GA(genetic algorithm)과 같은 복잡한 최적화는 더 나은 결과를 만들 수 있지만 그들 스스로 다른 하이퍼 파라미터를 도입하기도 한다.
Experimental results
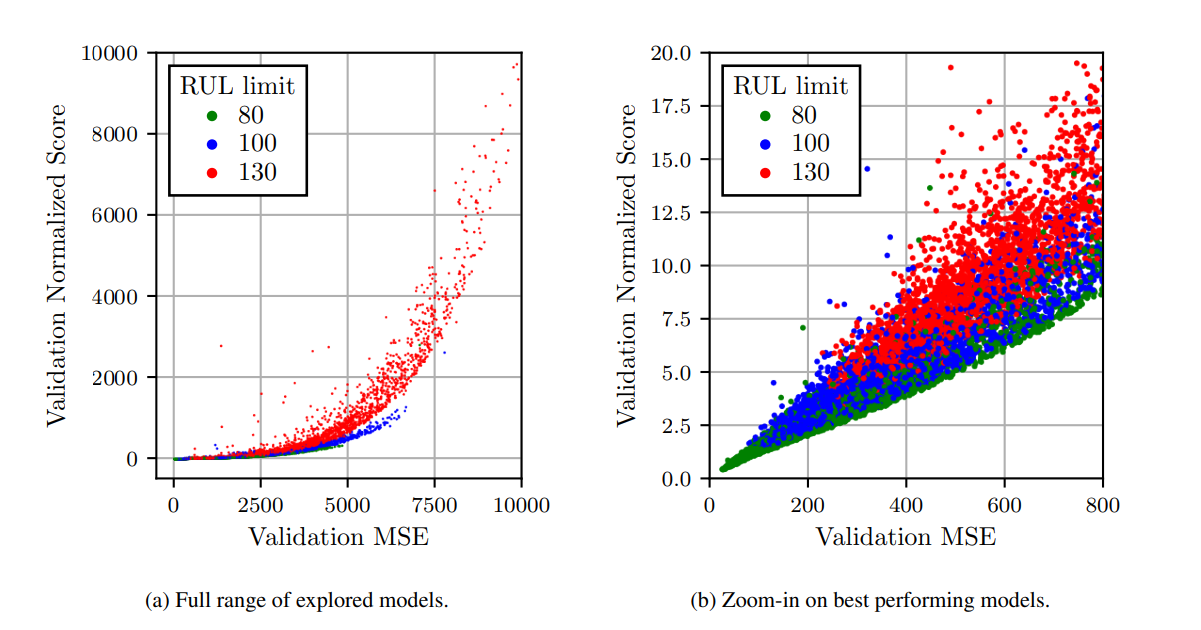
MSE와 validation set에 대한 정규화된 점수에 비춘 모델 결과 평가
낮은 RUL limit이 MSE와 score을 낮출 수 있음을 보여준다. 이것은 예측 정확도와 timeliness 사이의 trade-off를 보여준다. 모델이 너무 이른 예측을 하도록 강요된다면 불확실성은 높아지므로 오차가 커진다. 그러나 limit이 너무 낮으면 모델은 non-trival(사소한 예측)을 내게 된다.
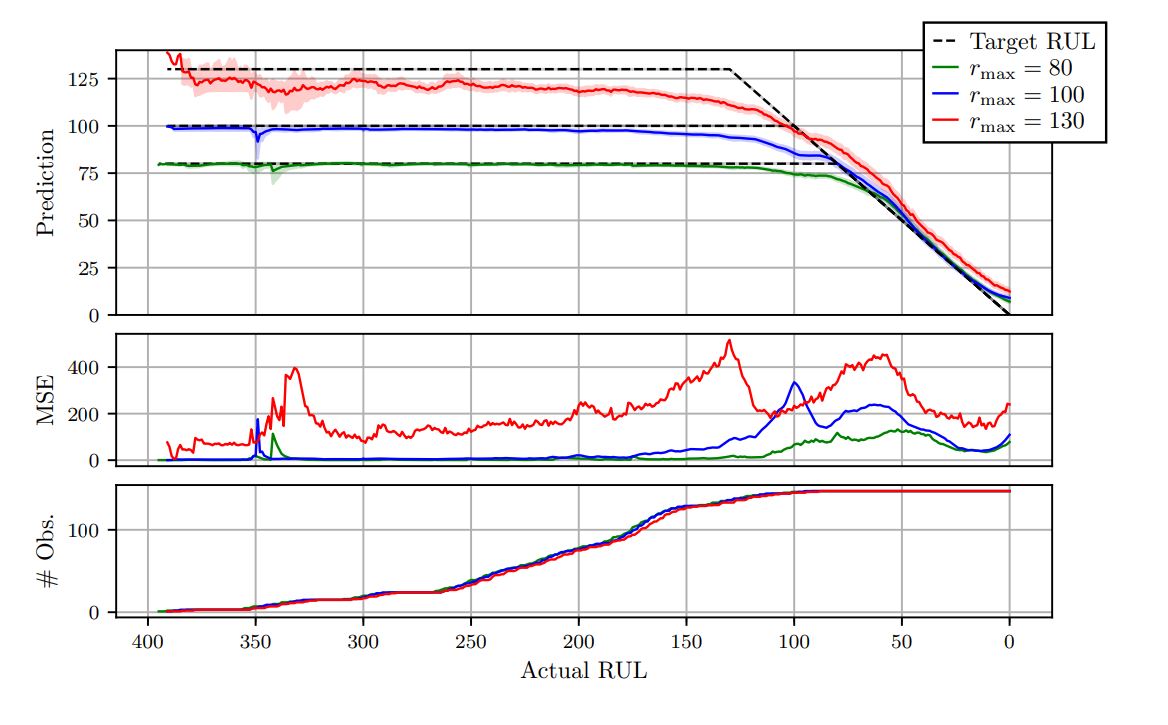
첫번째는 FD004에 대한 MLP,CNN,LSTM에 대한 평균 output을 보여준다. 음영처리된 부분은 각 time step의 예측에 대한 표준 편차이다. 점선은 R(max)제한된 target RUL을 보여준다.
두번째는 시간에 따른 예측값의 평균 제곱오차(MSE)를, 세번째는 각 time step마다 존재하는 data point를 보여준다. Data point는 각 3개의 평가 모델의 validation set data sequence에서 추출된다.
2번째 plot에서는 오차는 데이터 세트에 포함된 거의 전체 시간 범위 동안 rmax 값이 높을 때 일반적으로 더 높다. 오차의 피크는 상수/선형 감소 사이의 불연속성에서 볼 수 있다. 다른 rmax값에 따른 오차의 차이는 이 불연속 이후(RUL이 일치함에 따라) 더 작아지지만, 여전히 존재한다.
constant target regime에서의 더 큰 rmax 값에 대한 RUL 예측은 상당히 과소평가되는 경향이 있는데, 지연 예측을 penalize하는 asymmetrical loss function과 이른 성능 저하 상태에 대한 큰 불확실의 결과이다.
첫번째 plot을 보면, 더 높은 Rmax를 가진 모델이 RUL 값을 과소평가하는 경향이 있음을 알 수 있다. asymmetrical loss function에 의한 것이다.
Hyperparameter Effect
random search로 많은 분석을 함으로써, 예측 결과에 평균적으로 미치는 전반적인 영향을 평가할 수 있다. 매개변수가 random하게 선택되므로 각 효과는 개별적으로 나타나지는 않는다. 대신, 다른 매개 변수의 변경에도 유지되는 효과는 볼 수 있다.
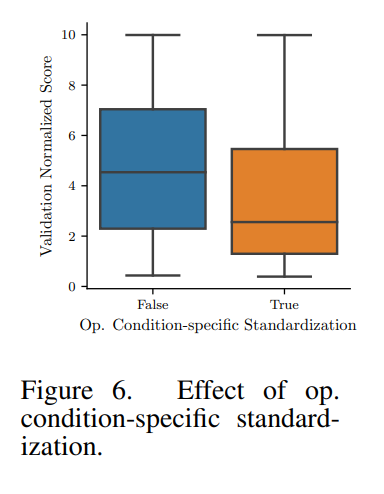
operation condition의 개별 standardization이 모든 데이터 하위 집합과 모든 모델 아키텍처에서 집계된 유효성 검사 결과에 미치는 영향을 보여준다. 평균적으로 정규화된 점수는 이 방법이 쓰일때 더 낮아지는 경향이 있으며, 여러 작동 조건을 가진 집합에서 더 나은 결과를 보여준다.
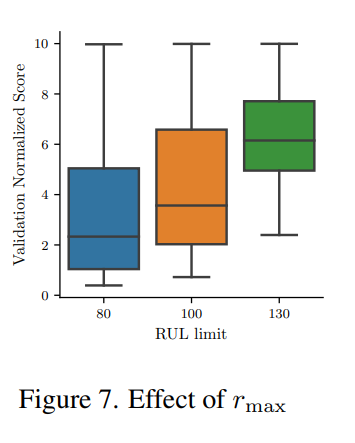
Rmax 선택의 영향을 보여준다. limit이 낮을 수록 score는 평균적으로 더 좋아지며, 이전의 accuracy, timeliness trade-off에서 봤던 관측을 보여준다
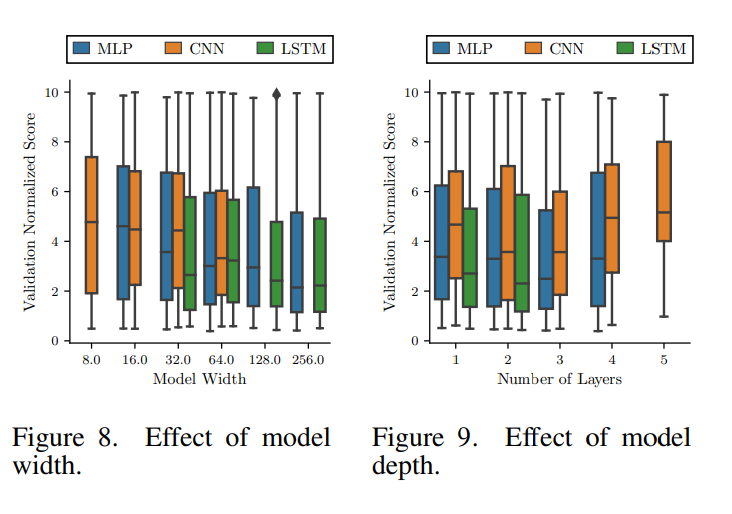
매개변수 중 특히 model width와 model depth에 관련된 효과를 보여준다. 다른 아키텍쳐들의 뉴런과 layer은 반드시 비교할 수 있지 않으며, 예를들어 LSTM 계층의 계산 비용은 같은 폭을 가진 MLP보다 높다. 각 아키텍쳐의 depth와 width는 모델을 사소한 솔루션(과적합 또는 과소적합이 아님)으로 수렴하고 훈련 시간을 비슷하게(계산 시간의 공정한 분할) 만드는 방법으로 손으로 선택되었다.
8번 그림에서 표시된 너비는 가장 좁은 layer에서 taken되며 너비는 layer 깊이에 따라 증가한다. 평균적으로 모델은 넓은 layer을 가질수록 이익을 얻는 것처럼 보이나 training time과 overfitting 가능성이 증가한다. 따라서 그림 8의 추세는 폭이 증가함에 따라 무한정으로 지속되는 것은 아니다.
9번 그림에서는 평균적으로 2,3개의 layer를 가진 얕은 모델이 훈련하기 쉽고 좋은 점수에 닿을 수 있음을 알 수 있다.
Comparison with Literature Results
단일 조건인 FD001, FD003의 경우 (listou ellefsen)이 최상의 결과를 달성.
FD002, FD004의 경우 CNN, MLP, LSTM 모델이 선두를 차지. 하위 집합 FD002 및 FD004에서 관찰된 더 나은 성능은 작동 조건별 표준화를 사용하여 크게 설명되며, 이는 기능이 작동 조건에 다소 불변하므로 모델이 열화 추세를 더 쉽게 감지할 수 있게 한다.
Conclusion
데이터 기반 방법의 중요한 세일즈 포인트 중 하나는 시스템의 내부 작동에 대한 컨텍스트별 지식이 거의 필요하지 않다는 사실이다. 그러나 신경망은 자유 매개 변수가 많고 훈련에 대한 계산 비용이 높아 매개 변수가 거의 없는 RULCIPPER(Ramasso, 2014)와 같은 보다 전문화된 알고리듬과 비교할 때 단점이 될 수 있다. 예측 적시성과 정확성 사이의 절충이 확인되었으며, 여기서 모델의 예측 지평을 감소시켜 그 대가로 더 낮은 예측 오류를 얻을 수 있다. 원시 데이터를 예측 모델에 직접 공급하는 것과 비교할 때 견고한 탐색 분석에 기초한 적절한 데이터 정리 및 전처리가 상당한 개선으로 이어질 수 있다는 결론을 제시한다.
