이전 편에서는 FD002에 대한 lag MLP를 구현했다. 여기서는 6가지의 작동조건과 두가지의 결함 원인에 대한 FD004에 대한 LSTM을 구현한다.
Loading data
RUL(max_cycle - time_cycle) 계산
전처리 후 시각화 진행
Baseline model
기준 모델은 선형 회기를 사용. RUL을 125로 clipping.
returns
train set RMSE:21.437942286411495, R2:0.7220738975061722
test set RMSE:34.59373591137396, R2:0.5974472412018376
Ploting
condition-based standardization 사용. 동일한 작동 조건에서 실행되는 데이터 그룹에 standardscaler를 적용한다(train과 test 둘 다에). 다른 작동 조건들이 센서 값의 평균을 다르게 하기 때문에 이렇게 한다.
센서 1,5,16,19는 유사해보이나 유용해보이진 않는다(삭제)
센서 2,3,4,11,17은 유사한 상향 추세를 보인다
센서 6,10,16은 어떠한 추세를 보이는 것 같진 않다(삭제)
센서 7,12,15,20,21은 두가지 결함에 대해 명확하게 보여준다
센서 8,9,13,14는 유사하지만 결함 조건들이 추가되면서 결함을 잘 구별하지 못하고 있다. 이 신호들을 사용해 모델을 만든다면, 이 신호들의 포함 여부를 표시해야한다.
센서 18은 어떠한 정보도 보유하지 않는다(삭제)
센서 2,3,4,7,8,9,11,12,13,14,15,17,20,21 을 사용
LSTM
LSTM은 sequence로 작동하기 때문에 시계열의 데이터를 정렬하기 유용하여 이를 사용해보기로 했다.
Data preparation
exponential smoothing과 train-validation split 함수는 이전편에서 나온 함수를 재사용한다. Smooting의 경우 alpha값이 작을수록 smoothing 효과가 커진다. model validation에서는 단일 엔진이 train과 validation set에 나뉘지 않아야 한다. train_val_group_split는 단일 엔진의 모든 레코드가 train/validation 집합에 할당되도록 분할한다.
LSTM은 예측 오류에 대한 fault sense를 제공하는 interpolation(보간법)에 의해 예측을 정확하게 할 수도 있다. 모델이 보이지 않는 데이터를 사용한다면 보간으로 인해 더이상 RUL을 예측할 수 없게되어 성능이 더 나빠진다.
Sequences
timeseriesGenerator 등을 사용해서 sequence를 만드는 것도 좋지만, 사용자 정의 코드를 사용하기로 했다.
1. Sequence는 단일 unit_nr에 대한 데이터를 갖고 있어야한다. 정상적으로 실행되고 있는 train set의 다음 엔진에 대한 기록과, 오류가 임박한 레코드가 섞이는 것을 방지하기 위해서.
2. 시계열은 주로 X 시간대를 사용해 Yt+1을 예측하는 반면 우리는 Yt를 예측하려고 한다. Yt를 예측하면
- 우리가 여태 진행했던 이전의 Dataframe을 그대로 사용할 수 있다
- 알고리즘에 조금 더 많은 데이터를 제공할 수 있다.
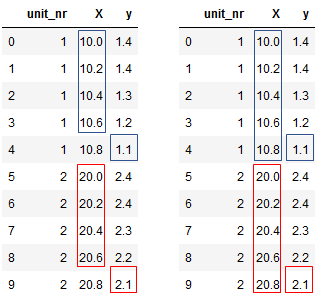
왼쪽은 Yt+1을 예측, 오른쪽은 Yt를 예측하는 경우다. 오른쪽을 보면 마지막 record를 통해 마지막 대상을 예측할 수 있다. 엔진 당 1개의 record가 추가되는 것이지만, 하위 집합에 대한 차이를 만들 수 있다.

gen_train_data는 단일 엔진의 record의 dataframe을 만든다. 예를 들어 길이가 4인 sequence를 만든다면, index 0~3까지의 배열 하나와 index 1~4까지의 배열 총 2개를 만든다.

원래 코드는 원하는 sequence 길이보다 적은 개수의 레코드의 경우에는 이를 버린다. 모델이 길이가 다른 sequece를 해결할 수가 없기 때문이다. 따라서 패딩을 추가해서(-99.), 이를 보관하도록 하자. 이때 패딩은 다른 값들과 일치하도록 부동 소수점(.)을 사용했다
Model training
먼저 모든 전처리를 수행한다
condition-based, exponential smooting, train-val split, sequence
초기 모델은 single layer LSTM이다. Masking을 사용하면 패딩 값을 해석하지 않고 사용할 수 있다. 모델을 compile하고 가중치를 저장하라
*save_weights / load_weights
returns:
train set RMSE:16.55081558227539, R2:0.8388066627963793
test set RMSE:29.043230109223934, R2:0.7162618665206494
매개변수를 tuning하기 전에 주의해야할 것이 있다.
- 센서 8,9,13,14가 없다면 모델 성능이 어떻게 변화할 것인가
- epochs를 늘렸을 때 validation loss의 변화
먼저 1)을 수행하자
returns:
train set RMSE:17.098350524902344, R2:0.8279650412665183
test set RMSE:29.36311002353286, R2:0.709977307051393
미묘한 변화가 있다. 매개변수를 조정할 때, 2가지 버전(이 센서들을 포함 / 미포함) 둘 다 해봐야할 것 같다
2)를 수행하자 (epoch 5 -> 20)
returns:
train set RMSE:15.545417785644531, R2:0.857795579414809
test set RMSE:29.32099593032191, R2:0.7108086415870063
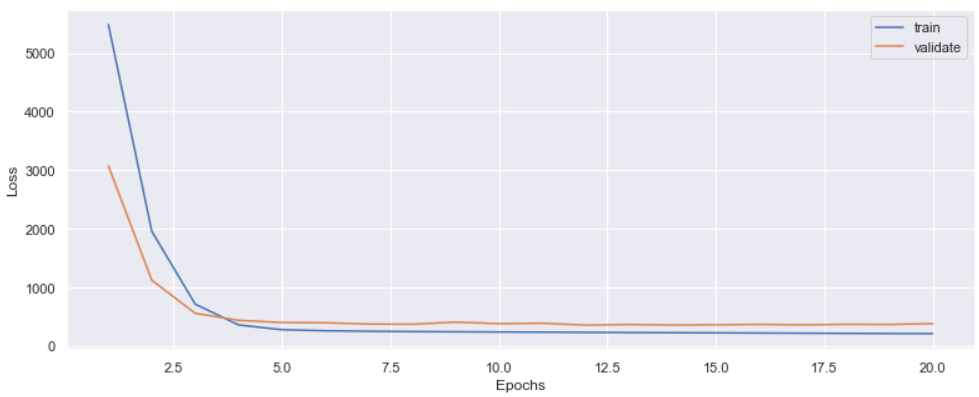
epoch 15 이후에서 약간의 overfitting이 보인다. 5보다는 크지만 15보다는 적은 epoch을 사용하자
Hyperparameter tuning
- alpha
- sequence_length
- epochs
- number of layers
- nodes per layer
- dropout
optimizerlearning rate- activation function
- batch size
- included sensors
모든 파라미터 range를 시험해보는 것은 시간이 너무 오래 걸린다. random gridsearch를 통해서 시간 소모를 줄여보자.
Groupshufflesplit의 경우 split=3이다. 즉 매개변수의 각 조합을 3번 학습하고 교차검증한다는 뜻이다. 유효성 검사 손실의 평균 및 표준 편차는 해당 특정 반복에 대한 하이퍼 매개 변수와 함께 저장된다.
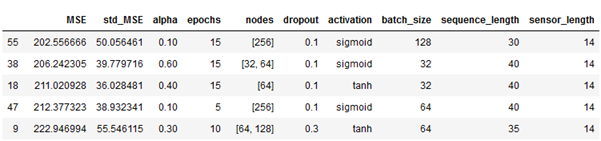

센서 8,9,13,14가 없는 시행은 상위권 안에 들지 못했다(sensor length) 즉 이 센서들을 포함하는 것이 낫다는 결과이다.
alpha = 0.1
sequence_length = 30
nodes_per_layer = [256]
dropout = 0.1
activation = 'sigmoid'
weights_file = 'fd004_model_weights.m5'
epochs = 15
batch_size = 128
위의 매개변수가 최상의 조합이다.
returns:
train set RMSE:12.35975170135498, R2:0.9112171726749143
test set RMSE:25.35340838205415, R2:0.7837776516770107
더 개선하고 싶다면 더 복잡한 전처리 및 신경망 아키텍처에 대한 몇 가지 논문을 읽고 오류 측정을 RMSE에서 late prediction에 불이익을주는 것으로 변경하는 것이 좋다. 다른 흥미로운 접근법은 calculate/predict the asset health index하는 것이다. 아이디어는 장비의 전반적인 상태를 알려주는 추상적 인 단일 KPI를 갖는 것이며, 전체 점수에 대한 각 센서의 기여도를 지정하여 이를 더 세분화 할 수 있다.
git 링크
stacked DCNN 코드와 상당히 유사하다
살펴볼 논문들
[3] Duarte Pasa, G., Paixão de Medeiros, I., & Yoneyama, T. (2019). Operating Condition-Invariant Neural Network-based Prognostics Methods applied on Turbofan Aircraft Engines. Annual Conference of the PHM Society, 11(1).
[8] https://www.researchgate.net/profile/Jianjun_Shi/publication/260662503_A_Data-Level_Fusion_Model_for_Developing_Composite_Health_Indices_for_Degradation_Modeling_and_Prognostic_Analysis/links/553e47d80cf20184050e16ea.pdf
[9] http://www.pubmanitoba.ca/v1/exhibits/mh_gra_2015/coalition-10-3.pdf
[10] https://www.wapa.gov/About/the-source/Documents/AMtoolkitTSSymposium0818.pdf
