0. Abstract
VAE 및 GAN 네트워크의 우수한 생성 특성으로, VAE-GAN 기반의 HI(health index) 곡선을 생성. BLSTM(bidirectional long short-term memory network)를 통한 센서 sequence 예측. 두가지 네트워크는 병렬로 진행되며 두 네트워크의 데이터를 합성해서 RUL 예측을 수행.
1. Introduction
VAE-GAN 및 BLSTM 기반 엔진에 대한 RUL 예측 프레임워크를 제안한다. VAE의 좋은 생성 특성을 이용하여 HI 값을 얻지만 단일 값 수치 예측이기 때문에 과적합 문제가 발생하기 쉽다. 따라서 GAN 판별기를 사용한다.HI를 생성하는 다른 모델과 비교하여 GAN은 데이터의 심층 기능을 추출하는 성능이 우수하고 생성된 HI도 특성화 능력이 더 뛰어나 나중에 RUL을 예측할 때 오류를 줄일 수 있다.
BRNN은 이전과 미래의 input data를 통해 현재의 output을 예측할 수 있고, 오로직 previous time input의 영향만 고려하고 later time input과의 상관도를 무시함으로써 발생하는 예측 오류를 줄이기 위해 시퀀스 이전과 이후의 timing correlation을 충분히 활용할 수 있다.
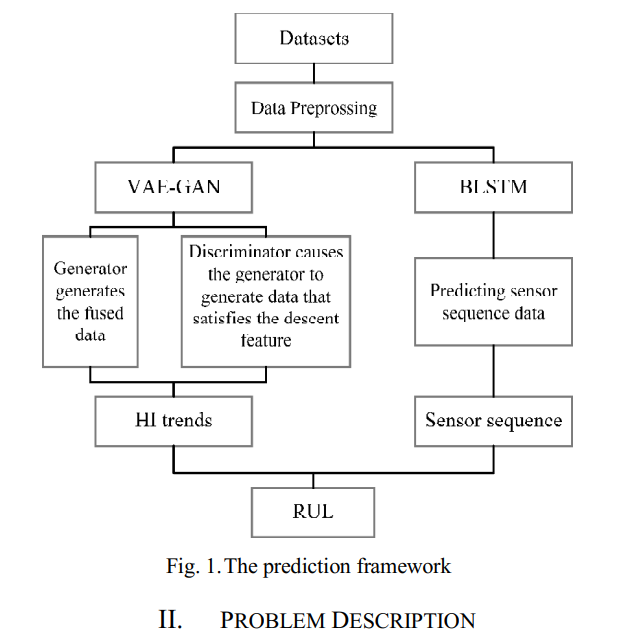
2. Problem Description
RUL 예측은 크게 두가지 카테고리로 나뉜다.
- 기존 데이터에 따른 상태 평가 곡선을 생성, 예측 중 상태평가곡선에 의한 외삽(관찰 범위를 넘어서서 다른 변수와의 관계에 기초하여 변수의 값을 추정하는 과정), threshold period와의 교차점을 찾는 것, 그리고 예측 값을 얻는 것.
- 기존 데이터에 따라 RUL과의 직접 관계를 찾는 것. 본 논문은 첫번째 방식을 사용하나 유사성 측정에 기반한 직접 외삽법을 사용하진 않는다. 이는 큰 예측 편차를 초래하기 때문.
센서 시퀀스 예측은 필요없지만, 오차가 작은 센서 시퀀스 예측 네트워크를 얻으면 현재 HI 곡선 세그먼트를 사용한 궤적 유사성에 기초를 둔 외삽법이나 HI 값과 RUL의 직접 매핑때문에 생긴 예측의 불안정성으로 인한 오차 축적을 피할 수 있고, 예측 오류가 적은 네트워크를 얻게 된다.
따라서 sensor time series가 먼저 예측되고, 합리적인 외삽을 수행하여 첫번째 방법의 정확성의 이점을 챙긴다.
3. Proposed method
VAE-GAN은 센서 데이터를 사용하여 장치의 HI 열화 곡선을 생성하는 데 사용, BLSTM은 각 센서 시퀀스의 데이터를 예측하는 데 사용된다. 그 다음 RUL을 예측한다.
Health Index Curve Generation
개선된 VAE-GAN은 이 문서에서 HI 곡선을 생성하는 데 사용된다.
VAE : AE의 feature 차원 축소 능력+GAN의 생성 능력
즉 센서 데이터의 차원 축소를 수행하여 계층별로 숨겨진 계층 정보를 추출할 수 있을 뿐만 아니라 생성된 곡선을 실제 HI 곡선에 더 가깝게 만들 수 있다. 따라서 VAE는 HI generator로 사용.
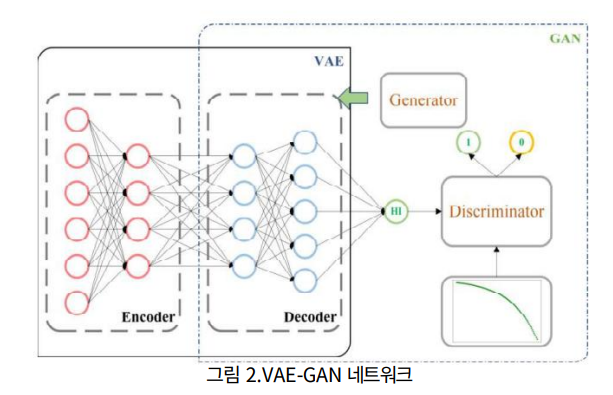
VAE의 디코더는 GAN의 엔코더이기도 하다. input 센서 값들은 인코더의 MLP를 통해 차원 축소된다. 그 다음 디코더에서 복원된다. 이 과정은 GAN에서 HI를 생성하는 과정으로 여겨진다. HI 값을 안정적으로 하기 위해 GAN의 D는 처음 하향 추세를 나타내는 rule function에 의해 학습되어 G에서 생성된 데이터가 요구 사항을 충족하는지 확인한다.
Predict Sensor Sequence
BLSTM은 반대 방향의 두 LSTM으로 구성된다. 즉 이전 데이터와 미래의 데이터를 모두 활용함
Predict RUL
HI 곡선은 현재와 후속 센서 시퀀스의 데이터 융합을 통해 얻어지고 HI의 임계값으로 외삽된다.
RUL = Cycle(threshold) - Cycle(current)
4. Experiments and Results Analysis
센서 1,5,6,10,16,18,19는 삭제
VAE-GAN Generates HI Curve
D의 real sample input으로 지수 함수가 사용되고, G에 의해 생성된 HI를 false sample input으로 사용한다. 대결(confrontation) 훈련을 통해 HI 곡선을 생성한다.
결정해야할 매개변수
- encoder와 decoder의 hidden layer / neural unit의 개수
- real sample f 생성 함수
- HI Degradation 임계값
연구자들이 엔진 유닛의 HI 곡선을 정의할 때, 노이즈를 추가한 후 지수 함수를 사용해 fitting했다. 따라서 지수 함수가 real sample input으로 사용되고 결과적으로 생성된 HI 곡선은 노이즈를 제거한 원본 HI 곡선과 유사할 것이다.
??? 이해 못함
BLSTM Prediction Sensor Sequence
CMAPSS 데이터 셋의 제한으로, 새 데이터 셋이 생성될 것이다.
BLSTM의 네트워크 매개변수가 너무 많아 과적합 문제를 해결하기 위해 Dropout 을 사용하며, 0.2의 매개변수로 설정된다.
실제값과 예측값 사이의 오류가 작은 것을 볼 수 있다.
RUL Prediction
예측에 오류가 있을 때, 사전 예측을 수행할 수 있는지 여부를 나타내는 index score라고 중요한 측정법이 있다. lag prediction이 높은 예측 score를 얻는 경우 (score가 낮을 수록 효과가 높다)
BLSTM이 센서 시퀀스를 예측하는데 사용될때 오류가 발생할 수 있고 외삽할때 오류 누적이 생길 수 있다. 이 문제가 최종 RUL 예측에 미치는 영향을 관측하기 위해 FD001의 cycle 50과 cycle 100에서 각각 예측을 비교한다.
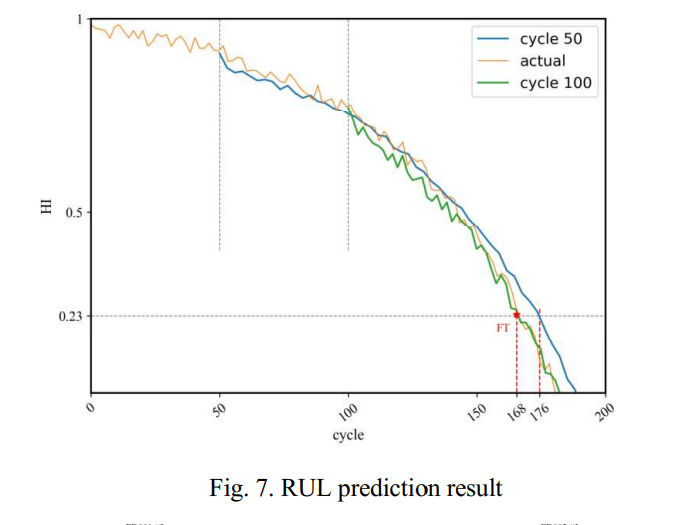
즉 실제 데이터가 충분할 때 생성된 곡선이(cycle 100 : 즉 100까지 실제데이터를 보고 100부터 예측을 시행) 실제 HI 곡선에 접근하게 된다.
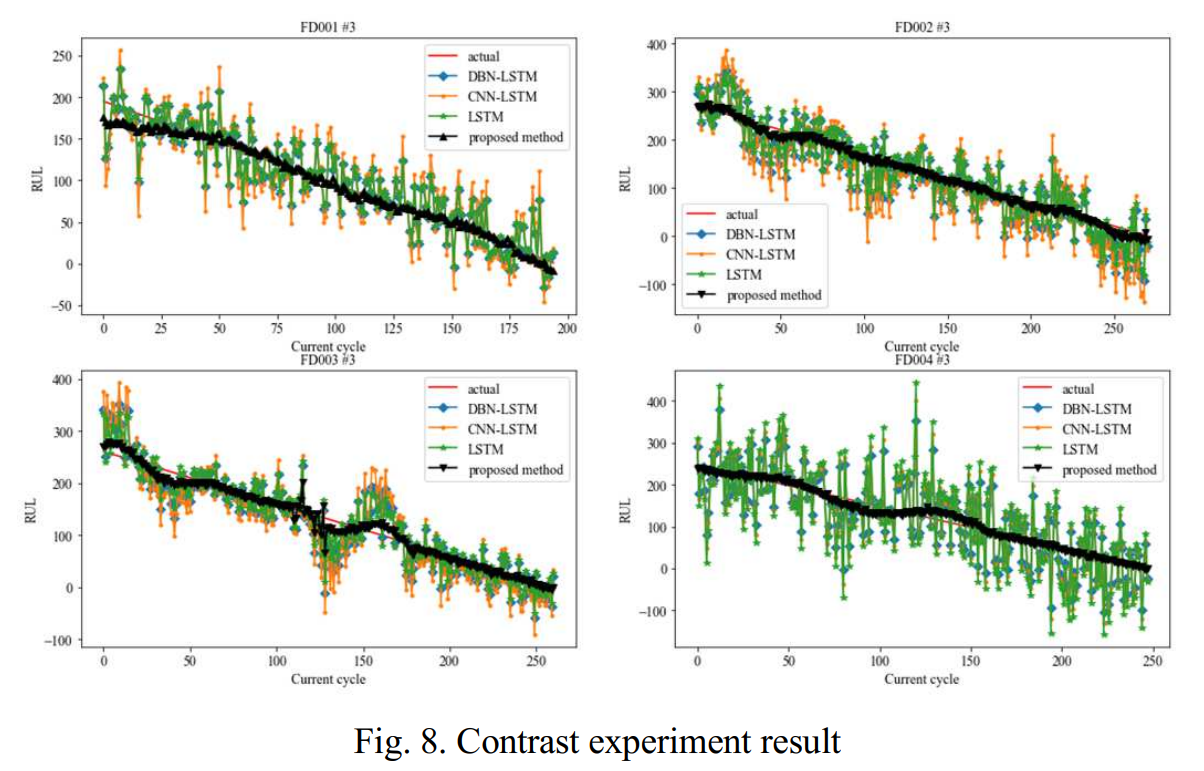
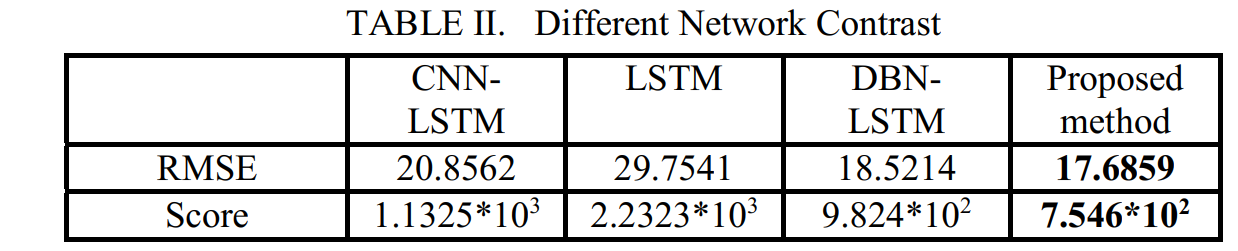
타 네트워크와 동일한 조건 하에서 실험했을 때, 우리의 방법이 더 나은 것을 볼 수 있다.
5. Conclusion
LSTM과 비교하여 BLSTM 예측 센서 시퀀스의 정확도는 평균 20% 이상 향상되었으
며 현재 RUL 예측의 총 점수는 다른 네트워크에 비해 거의 5% 감소하여 제안된 방법
의 효과와 우수성을 입증합니다
