optimizing LR (cyclic learning rate)
learning rate tuning에 대해서 알아보자
기본적으로 0.1이나 0.01로 설정한 후 callback 함수에 넣어서 ReduceLROnPlateau를 사용해왔었는데 다른 방법을 발견했다
딥 러닝 모델은 일반적으로 stochastic gradient descent optimizer에 의해 학습된다. Adam, RMSProp, Adagrad 등의 다양한 변형이 있으며 learning rate(LR)을 설정할 수 있다. LR은 optimizer에게 weight를 얼마나 움직일지 설정하게 한다.
LR이 낮으면 신뢰도가 높지만 시간이 오래 걸리고
LR이 높으면 훈련이 수렴되지 않거나 발산할 수도 있다. 즉 변화하는 weight값이 너무 커져서 어려움을 겪는것.
훈련은 상대적으로 큰 lr에서 시작해서, 훈련 중에 감소하며 세분화 된 weight update를 하는 것이 일반적이다. 시작 lr값을 선택하는 방법은 여러가지가 있다. 0.1에서 시작해서 0.01, 0.001 등을 시도하는 방법.
더 나은 방법은 없을까?
낮은 lr에서 시작해 네트워크를 훈련시키고 모든 배치에 대해 lr을 기하 급수적으로 증가시키는 것이 방법이다.
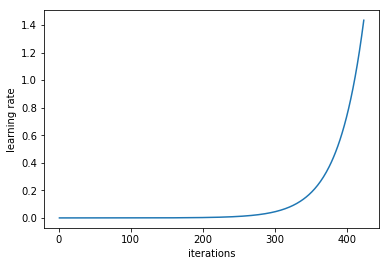
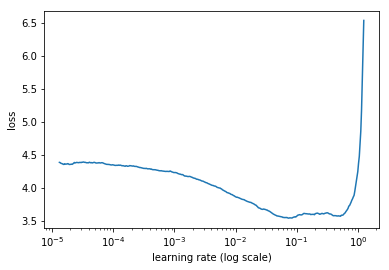
lr이 낮을때는 loss가 천천히 향상되다가, lr이 커지고 loss가 커질때 학습은 가속화된다. 우리는 여기서 fastest decrease in the loss 시점을 선택해야한다. 해당 그래프에서는 0.001과 0.01 사이임.

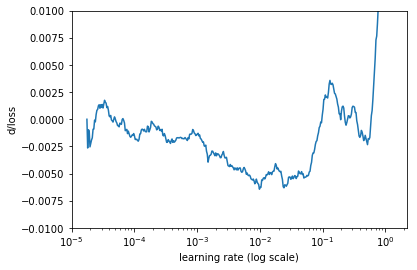
또 다른 방법은 loss의 변화율 (iteration에 대한 loss 함수의 미분)을 계산하는 것. 그래프의 노이즈를 감소시켜보면, 최소값을 찾을 수 있다. 즉 lr = 0.01 쯤.
learn.lr_find()
learn.sched.plot_lr()이 두 줄이, 위의 과정을 통해 lr finder를 구현한다.
https://arxiv.org/pdf/1506.01186.pdf
cyclical LR 논문
모든 lr finder 최적화 글에서 해당 논문을 추천하고 있음
cyclic LR finder 리뷰
아직 위 논문을 읽어보진 못했고 간단한 리뷰만 읽어봤는데
대충 fastest decrease in loss 시점의 lr이 최적화 된 값이라고 lrfinder가 찾는데
local minimum인 부분에 빠져들어서 거기가 최소라고 생각하고 멈춰버리는 문제 <-- 딥러닝에서 흔히 발생하는 그 국소값 문제
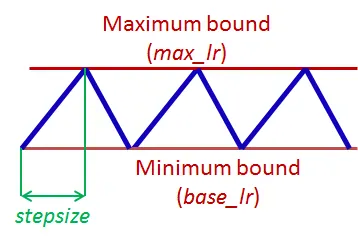
이거때문에 cyclic하게 lr을 최솟값 최댓값 사이에서 증가 감소하는 것을 반복해서 최적을 찾는 느낌임!
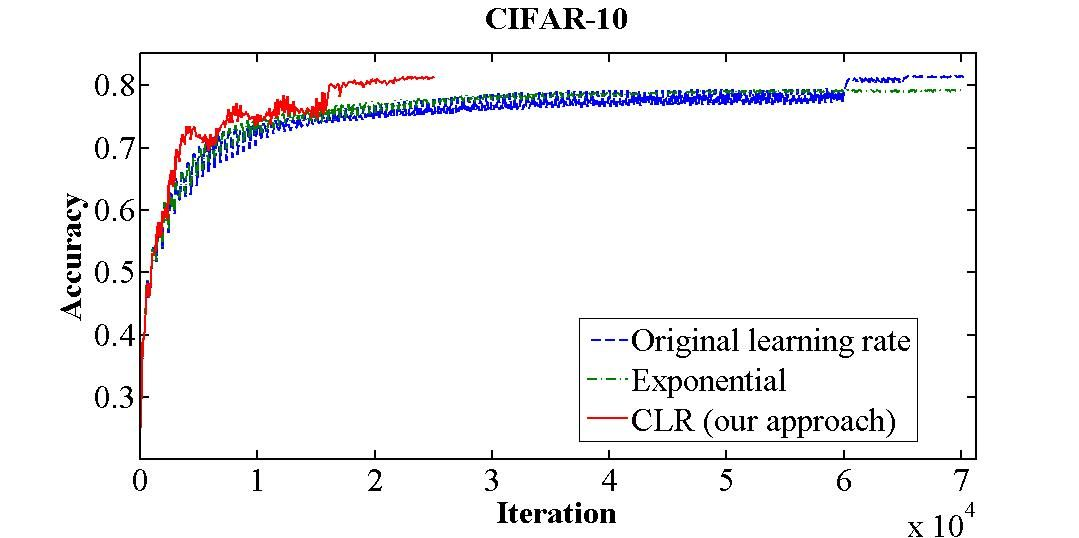
주기적 학습률은 안장점 대응에 효과적입니다. 안장점에서는 기울기가 작아(평면 등) 학습률이 작을 때 학습이 느려질 수 있는데, 이런 장애물을 넘어가는 가장 좋은 방법은 기울기가 높은 곡면을 만날 때까지 학습률을 높이는 것입니다. CRL의 학습률 증가는 바로 이런 일을 하는 것입니다. 효과적으로요.
차후에 논문을 읽게된다면 다시 포스팅함
*관련 글들
https://iconof.com/1cycle-learning-rate-policy/
