
이미 1차 계획서를 제출한 관계로 필요한 내용들만 간단히 정리할 예정이다
SOTA는 가장 성능이 뛰어난 모델을 말한다
따라서 우리는 논문을 차용하여 이미 SOTA로 판명난 모델들과 차후 우리가 custom 할 모델들을 만들고 이들을 rmse, mae 등으로 평가하여 우리의 SOTA를 선정할 것이다.
첫번째 소개 모델은 RVE(Recurrent Variational Encoder) 이다.
데이터 셋 소개는 따로 작성할 예정이지만 여기선 우리 연구 과제에 주어진 데이터 셋인 CMAPSS를 사용한다.
Variational encoding approach for interpretable assessment of remaining useful life estimation
(잔여 수명 추정의 해석 가능한 평가를 위한 변형 인코딩 접근 방식)
RVE 모델의 구조
인코더 + 잠재 공간 + regressor
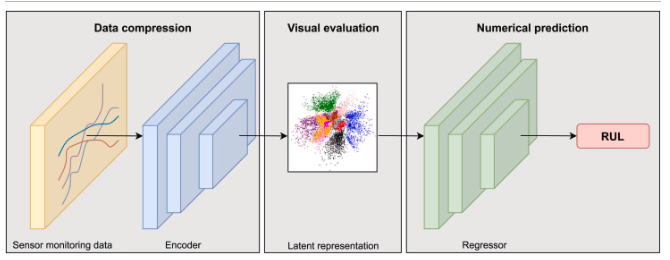
항공기 데이터가 인코더에 입력되고 인코더는 궤적의 진화를 반영하는 그래픽 맵을 구축하기 위해 열화 패턴을 기반으로 잠재 표현을 학습합니다. Regressor는 이러한 잠재 공간을 얻는 데 직접적인 영향을 미치며 각 엔진의 RUL을 수치적으로 보고할 수 있습니다.
인코더는 속성에 따라 데이터를 잠재 공간으로 압축하는 feature extractor 역할을 하며, 이는 엔진의 다양한 저하 단계입니다. 잠재 공간은 특히 2차원에서 항공기의 압축된 표현을 포함합니다. 이 표현은 훈련이 완료된 후 엔진의 성능 저하 패턴을 시각적으로 평가하는 데 사용됩니다.
마지막으로 수치예측모델(회귀모델)에 공급되는 각 엔진을 가장 잘 나타내는 RUL은 잠재 공간에서 학습된 function으로 회귀 모델을 직접 학습하여 제공됩니다.
VAE를 사용하지만 약간 변형한다.
왜?
기존의 VAE는
- 시스템 수명의 수치적 추정을 진행할 수 없다
- 궤적 예측의 시간 변화가 올바르게 분리된다는 보장이 없다
- RUL 예측은 online (실시간) 과정이다 즉 계속 업데이트 되어야 한다 그러나 latent space에서 시스템의 투영은 시간 경과에 따른 지속적 성능 저하가 발생한다
따라서 기존 VAE 대신 "순환 변이 인코더"를 기반으로 하는 신경 아키텍쳐 + 새로운 training 정규화 방법으로 위의 두가지 문제 해결
시계열을 처리하기 위한 순환아키텍처(Recurrent Network) function이 RUL 추정을 수행
시간열 데이터 처리를 위해 순환 아키텍쳐를 사용하기로 함 --> 대표적인 반복 네트워크인 LSTM 사용
보통 숨겨진 상태를 통해 과거의 정보를 보존하며 데이터를 역방향에서 순방향으로 처리함
우리는 양방향 LSTM 통해 과거에 대한 정보 + 미래에 대한 정보까지 받음
먼저 과거에서 미래로 처리하고 그 다음 미래에서 과거로 처리하여 두 기간의 정보를 보존 --> 예측 가능
기존 VAE와 어떻게 다른가?
* 디코더를 회귀 모델로 교체
* loss function을 다르게 설정
우리는 잠재 공간에서 엔진의 연속적인 상태의 투영(projection)이 연속 궤적을 구성하는 것을 선호하는 두 번째 항과 Kullback-Leibler 항의 연관과 관련된 새로운 비용 함수를 제안합니다. 이 두 번째 항은 나중에 설명하겠지만 시간이 지남에 따라 연속적인 RUL 예측 오류에 페널티를 부여하며, 엔진의 수명을 예측하는 새 네트워크의 능력과 잠재 공간의 품질 모두에 긍정적인 영향을 미칩니다.
따라서, 우리는 시각적, 따라서 설명 가능하고 해석 가능한 진단을 제공하기 위해 적절한 속성을 가진 잠재 공간의 구성으로 인해 Representation Learning 속성을 포기하지 않고 새로운 순환 네트워크 아키텍처(recurrent network)의 사용을 최대한 활용합니다.
인코더는 데이터가 속한 확률 분포를 초기화하는 매개변수에 의해 설명되도록 데이터를 잠재 공간으로 압축하는 방법을 학습합니다. 위에서 언급한 매개변수를 학습하기 위해 하나의 확률 분포가 다른 확률 분포에서 얼마나 많이 발산하는지 측정하는 Kullback-Leibler divergence를 통해 손실 함수에 Variational Inference가 추가됩니다. 회귀 모델의 잘못된 추정에 penalty을 주기 위해 두 번째 항도 추가됩니다. 결국 이 모든 것은 유사한 데이터가 다른 작업을 효율적으로 수행할 수 있는 가까운 영역에 있는 잠재 공간을 학습할 수 있도록 합니다.
면접 전에 latent space, VAE 정의 공부하기
VAE에서 훈련 과정은 과적합을 방지하고 잠재 공간이 생성 과정 을 가능하게 하는 필수 속성을 갖도록 정규화됩니다 . 이를 얻기 위해 인코더는 유사한 데이터가 서로 가까이 있는 방식으로 잠재 공간의 데이터를 매핑해야 합니다. 이를 통해 디코더는 데이터를 효율적으로 재구성할 수 있을 뿐만 아니라 훈련 샘플의 인코딩에 해당하지 않는 잠재 공간의 지점에서 새 인스턴스를 생성할 수도 있습니다.
VAE는 왜 하는가
- Generative Model로 적은 data를 갖고 그 분포를 가깝게 근사하여 새 data를 만듬
- latent variable 분포를 통해 우리가 샘플링 할 값들의 분포를 control 할 수 있음 또한 manifold 학습에도 유리
즉 data의 특징을 알 수 있으며 그 분포에 맞게 control하는 동시에 새 값도 만들 수 있다는 장점
그렇다면 우리 모델과의 차이점은?
vae 인코더는 데이터를 가능한 압축된 상태로 투영하도록 하여 latent space를 정규화 함 -> 중복 발생 -> RUL 추정이 어려움
왜?
비슷한 RUL 값을 가진 항공기는 명확하게 구분되지 않음 -> 예측 실패
따라서 우리는 분류기가 아닌, 디코더를 회귀 모델로 교체함
정규화
1) Condition-Based 정규화를 사용
이 접근 방식을 사용하면 동일한 작동 조건의 모든 레코드가 함께 그룹화되고 표준 스케일러를 사용하여 크기가 조정됩니다. 이러한 유형의 스케일링을 적용하면 그룹화된 작동 조건의 평균이 0이 됩니다. 이 기술은 각 작동 조건에 개별적으로 적용되므로 모든 신호는 평균 0을 수신하여 비교할 수 있습니다.
2) 칼만 필터로 노이즈 감소 + exponential smoothing
센서 데이터는 일반적인 경향이 있지만 주로 고주파 센서에 의해 발생하는 국부 진동에 영향을 받아 노이즈가 발생하는 것으로 알려져 있다. 계열 처리를 쉽게 하기 위해 지수 가중 이동 평균이 수행됩니다. 필터링된 값을 계산할 때 현재 값과 이전 필터링된 값을 고려합니다. (Kalman Filter) -> 필터의 유일한 목적은 센서 측정의 진동을 줄이는 것
낮은 알파를 지정하면 더 강한 평활화(smoothing) 효과가 나타나, 정지상태를 잃어버린다.그럼에도 불구하고 더 강한 평활화는 더 나은 모델 성능으로 이어집니다. 우리가 모델링하려는 것은 고장 지점의 감지가 아니라 저하율 의 변화 , 즉 일정 시간이 지나면 엔진 부품이 이전과 다른 속도로 저하되는 중단점 이라는 점에 주목하는 것이 중요합니다.
시계열 데이터 window, time step
시계열 데이터에서는 예측을 위해 데이터를 시퀀스로 분할함
고정된 크기의 window로 slice함
각 time step에서 데이터는 RUL을 예측하기 위한 네트워크에 대한 입력으로 사용되는 고차원 특징 벡터임
마지막 몇 주기의 특정 엔진에 대한 시퀀스 분할에 창 길이를 완료하기에 충분한 데이터가 없을 수 있음. 이러한 경우 마스크된 값이 사용되며 해당 값을 단순히 무시하여 모델의 첫 번째 레이어에서 처리함.
window 길이, smoothing 강도 또는 순환 계층(Recurrent layer)의 내부 뉴런 수가 핵심 요소입니다.
Hyperopt 베이지안 최적화 라이브러리에서 하이퍼파라미터 설정에 대한 참고사항을 얻는다.
LR의 정확한 선택이 특히 중요하므로 이 매개변수에 대해 적응형 LR 옵티마이저인 Adam과Cyclic Learning Rate 기법을 사용합니다.
또한 콜백을 사용하여 Epoch 수 대신 Early stop 조건을 유효성 검사 오류로 분류하는 측면에서 실험을 사용자 정의했습니다.
추가
- 센서의 선택 : 논문에서는 21개 중 6개만 선택함 -> 그럼에도 충분한 정보를 제공했다고 함
- 훈련 데이터의 20%를 검증 데이터로 사용
- SOTA인 이유
기존 방법들은 데이터를 나타내지 않고 다음 단계에 해당하는 RUL만 예측한다는 점을 언급할 가치가 있습니다. 그런데 우리 방법은 데이터를 나타내어 시각화 진단 지도까지 제공하므로 대단하다.
데이터 세트 FD001 및 FD003의 경우 메트릭이 양호한 것으로 간주되지만 최고가 아님을 빠르게 알 수 있습니다. 그러나 FD002 및 FD004에 관심이 집중됩니다. 작동 조건 및 고장 모드의 수가 증가함에 따라 이 두 데이터 세트에 더 복잡한 다중 스케일 저하 기능이 포함되기 때문입니다. RVE는 Score와 RMSE 모두에 대해 이 두 가지 예측 정확도를 크게 향상시킵니다.
결론과 향후 과제
우리는 항공기 엔진 진단 을 해결하기 위해 잠재 표현을 정규화하는 새로운 방법으로 변형 인코딩(variational encoding)을 기반으로 하는 새로운 아키텍처를 제안했습니다 . 이는 변동 추론(variational inference)을 통해 얻어지며 잘못된 RUL 추정에 불이익을 주는 비용 함수의 항에 의해 형성됩니다. 그 결과 VAE와 같은 다른 모델과 마찬가지로 급격한 점프 없이 엔진 궤적의 이력을 지속적으로 투영할 수 있는 잠재 공간이 생깁니다 . 결과적으로 인코더가 학습한 잠재 공간은 진단 도구로 사용됩니다. 보이지 않는 엔진이 주어지면 유사한 저하 패턴을 가진 엔진 근처에서 인코딩을 투영하기 위해 서로 다른 열화 단계를 가진 엔진 데이터의 2차원 표현(시각화 진단맵)을 학습합니다. 따라서 설명 가능한 진단이 지배적입니다.
마지막으로, 향후 작업에서 상태 모니터링 및 예측 유지 관리 (https://www.sciencedirect.com/topics/engineering/predictive-maintenance)와 관련된 다른 영역에서 모델의 적합성을 탐색하는 것을 목표로 합니다 . 또한 모델이 저하 단계를 구별하는 것 외에도 다양한 분야의 실패원인(예방적 유지보수)을 설명할 수 있는 잠재 기능을 학습하도록 동기를 부여하는 것이 흥미로울 것입니다.
- Introduction
RUL과 같은 지표가 유지보수 일정을 개선하고 엔지니어링, 안전 및 신뢰성 고장을 방지하기 위한 핵심 요소로 확립되었다. 결과적으로, 이를 통해 엔진의 성능 저하를 확인할 수 있다. 엔진 비행 시간을 늘리고 유지 비용을 절감한다.
