https://github.com/NahuelCostaCortez/Remaining-Useful-Life-Estimation-Variational
논문에서 제공하는 코드
https://github.com/dangdang2222/skt_ai_fellowship/blob/main/CMAPSS_%EC%8B%9C%EA%B0%81%ED%99%94.ipynb
내가 작성한 시각화 코드
먼저 내가 쓴 코드에서,
크게는 아래 2가지 유형의 시각화를 볼 수 있다
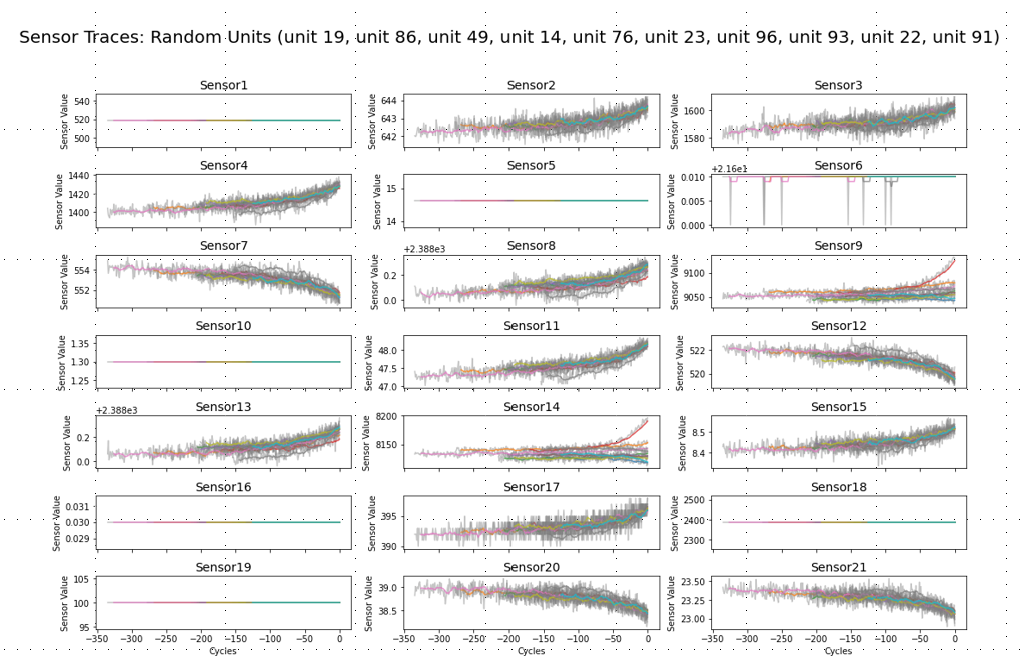
해당 그래프는 data set의 unit 중 random으로 10개를 뽑아서, 10개 unit의 각 sensor들의 sensor value를 나타낸 그래프이다. 보다 편한 시각화를 위해 각 sensor 값들을 이동평균 함수인 rolling을 이용하여 X축의 window 창을 이동하면서 y값의 평균 mean 값을 구하였다. 그래프를 보면 10개의 unit들의 센서 중 유사하게 상승/하강하는 센서가 있는 반면 sensor 1,5,6,16,18,19처럼 아예 변화가 없거나 sensor 9번과 14번처럼 unit별로 아예 다른 방향성을 보여주는 경우도 있다. 변화가 없는 sensor들의 경우 학습에서 제외시키는 것이 학습에 유리할 것이며 각각 다른 방향성을 보여주는 sensor들의 경우는 학습 및 예측을 어렵게 하는 요인으로 작용할 것이다
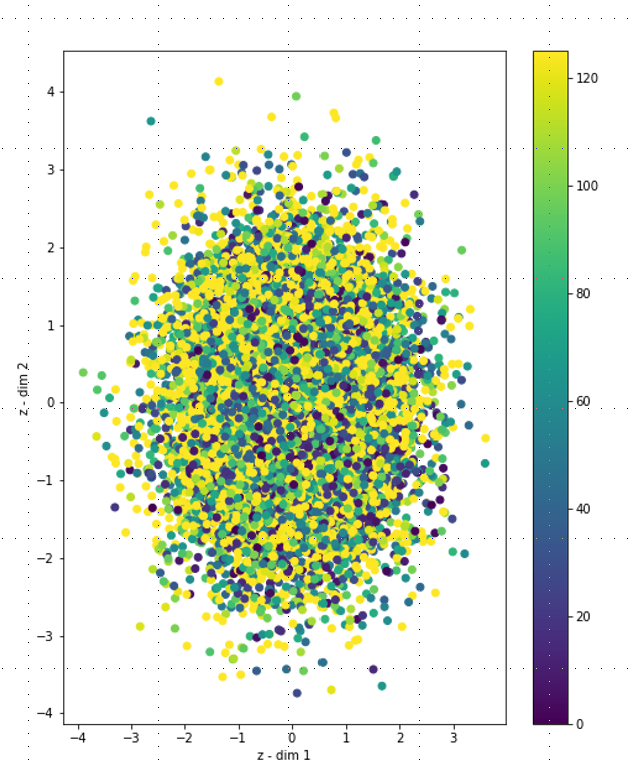
존재하는 RUL 값들을 2차원 Latent Space에 매핑했을 때의 산포도.
노란색으로 갈수록 RUL이 크고 파란색 쪽은 RUL이 작다.
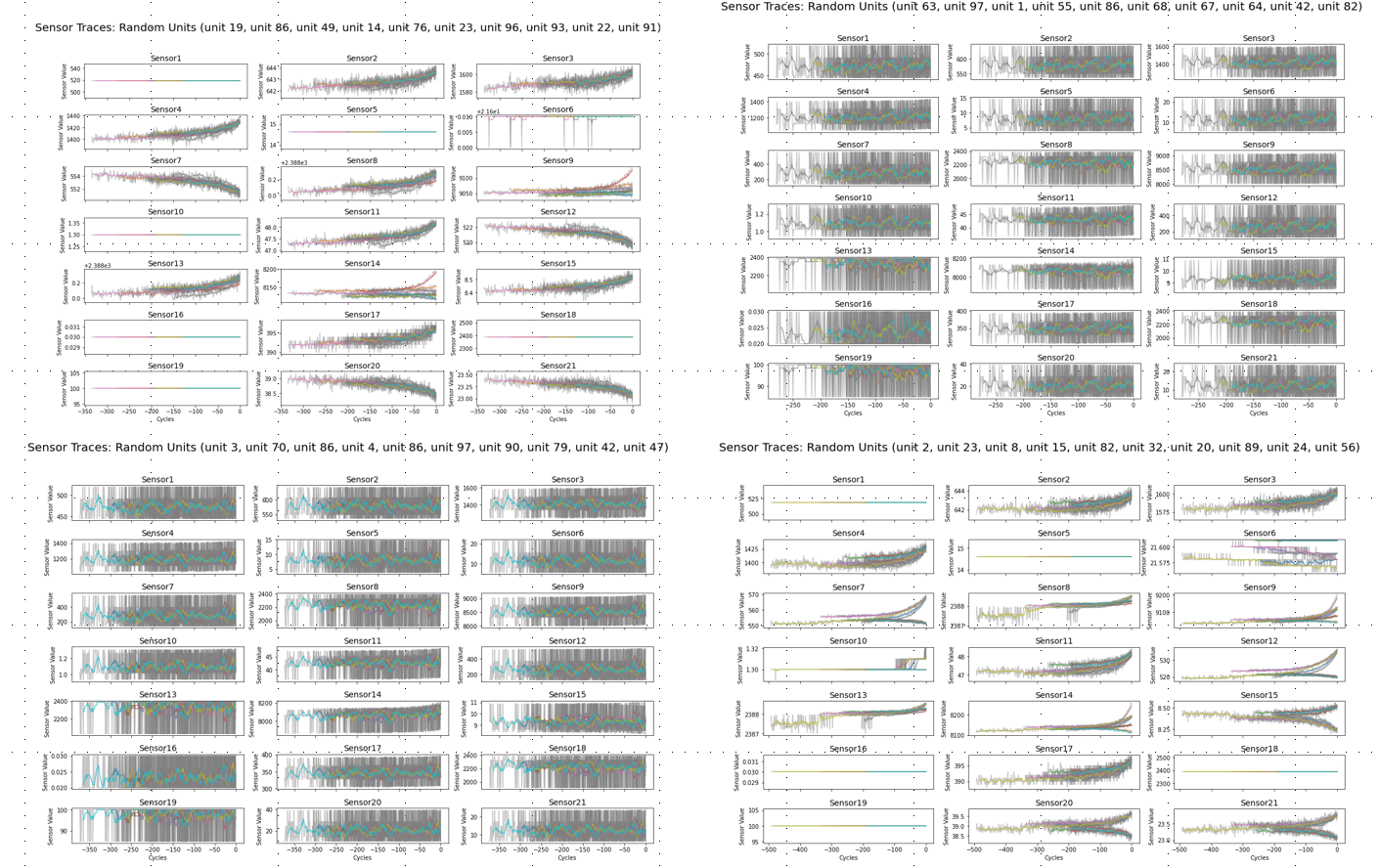
Data set 1번과 3번 그리고 Data set 2번과 4번의 시각화 그래프를 비교해보면 후자가 보다 복잡한 형상을 띄는 것을 알 수 있다. 2번과 4번의 경우 기계 고장 요인이 2가지로, sensor value에 이러한 복합성이 반영되었기 때문으로 원인을 추정할 수 있다.
논문의 코드를 뜯어보자
캡쳐해오기 귀찮은 관계로,,, 함수 이름으로 표기함
먼저 uitls.py를 보자.
get_data : 여기서부터 시작이다. 데이터를 읽어오는 파트인데 개인적으로 내 코드가 더 간단한 것 같다^!^
add_remaining_useful_life : 학습에 필요한 남은 lifetime을 구하여 dataframe에 붙이는 과정이다. 이 값들이 label이자 target 값으로 사용되기에 중요한 값들이다. 주의할 것은 test 데이터는 우리가 이 값을 예측해야하기에 train 데이터 셋에 대해서만 할 것.
add_operating_condition+condition_scaler : 필요없는 sensor들을 drop한 dataframe을 넣고, 데이터 정규화 중 condition-based를 하는 부분. 레코드가 함께 그룹화되고 표준 스케일러를 사용하여 크기를 조정.
exponential_smoothing : 열 처리를 쉽게 하기 위해 지수 가중 이동 평균 수행, 센서 측정의 진동을 줄이는 것. 낮은 알파를 지정하면 더 강한 smoothing 효과가 나타나며 더 나은 모델 성능으로 이어진다. 왜? 우리가 모델링 하려는 것은 저하율의 변화니까. (즉 일정 시간이 지났을 때, 엔진 부품이 이전과 다른 속도로 저하되는 중단점)
자 이제 우리가 해야할 것은 무엇일까
이미 SOTA라고 판명난 이 모델을 더 개선해 보는 것이다.
1. 모델의 핵심 구성 요소 개선
- Window 길이
- Smoothing 강도
- 순환 계층(Recurrent layer)의 내부 뉴런 수
- Hyperparameter 및 Early stop 조건 변경
2. 데이터 셋 보완 및 변경
- 데이터셋 및 feature에 대한 분석 추가 진행
- N-CMAPSS, Li-ion 데이터세트 등 더 다양하고 많은 양의 데이터로 학습
- 항공기 Turbofan Engine 뿐 아니라 다른 도메인의 기기/설비 특성 파악
3. 평가 지표 파악
- RUL 예측에 대한 RMSE, MSE, MAE
- Overfitting 여부
- Throughput, Latency, Capacity, GPU 사용량 등을 측정
4. 모델 성능 향상을 위한 기법 추가 적용
- 모델의 layer 구조 변경, 타 모델에서의 기법 추가 적용 등 모델의 알고리즘 자체에 대한 수정을 통한 성능 향상
