Remaining useful life prognosis of turbofan engines based on deep feature extraction and fusion 上
노이즈, 다양한 데이터 유형, 대용량인 데이터 용량, 복잡한 feature extraction, 열화 추세를 효과적으로 설명할 수 없는 것, RUL 예측과 같은 문제 해결을 위해 improved stack sparse autoencoder(imSSAE)를 RUL 예측 모델에 결합하고, improved echo state ntwork(imESN)이 제안된다.
처음 3-sigama 기준을 채택하여 노이즈를 제거하고 데이터를 재구성한 다음 imSSAE를 사용해 엔진의 심층 feature를 추출하며 열화 추세를 설명하는 Health Indicator(HI)곡선에 융합한다.
마지막으로 다양한 유형의 데이터를 처리하고 RUL을 얻기 위해 attention mechanism이 imESN에 도입된다.
1. feature extraction 방법 또는 모델의 선택은 형상의 효과를 직접 결정한다.
2. 터보팬 엔진의 열화를 반영하는 건강 지표(HI)가 예측 정확도를 결정한다.
현재 RUL 예측 방법에는 모델 기반 예측과 데이터 기반 예측의 두 가지 주요 유형이 있다. 모델 기반 RUL 예측은 수학적 또는 물리적 모델을 확립한다. 그러나 터보팬 엔진은 크고 정밀하며 복잡한 내부 구조 장비이다. 그러한 종류의 장비의 작업 환경, 제조 재료 및 기타 불확실한 요소들은 정확한 모델을 확립하는 것을 어렵게 한다. 따라서 데이터 중심 방식은 RUL 예측의 주류가 되었다.
딥러닝 모델은 효과적인 기능을 채굴할 수 있지만, 컨볼루션 신경망과 같은 지도 학습 방법은 미세 조정을 위해 많은 레이블링된 데이터가 필요하다. 실제로 레이블링된 데이터는 얻기 어렵다.
자동 인코더(AE)는 일반적인 비지도 네트워크 모델로, 비지도 학습을 통해 레이블이 지정되지 않은 입력 데이터의 심층 feature을 추출할 수 있다. AE의 주요 형태로는 noise reduction AE, sparse AE, stack AE 및 variational AE가 있다. sparse AE가 나쁜 조건에서 적절한 특징을 추출하고 차수를 희소 표현으로 줄일 수 있는 반면, stack 인코더는 unsupervised pretraining을 수행할 수 있음을 보여준다.
두 모델의 장점을 결합하여 희소 AE를 적용하여 센서 데이터 세트의 심층 기능을 추출한 다음 희소 AE를 스택하여 imSSAE라는 새로운 모델을 형성하여 다차원 심층 feature을 1차원 feature로 축소한다. 이 구조는 feature 차원을 감소시킬 뿐만 아니라 feature의 효과를 보장하고 후속 신경망에서 feature 처리를 단순화한다.
feature를 추출하는 것 외에도 RUL 예측은 HI를 구성해야 한다. 많은 예는 HI의 품질이 예측 방법의 효과에 큰 영향을 미치므로 효과적인 HI를 구성할 필요가 있음을 보여준다. echo state network(ESN)이 large-scale coefcient-linked 뉴런을 무작위로 배치하여 네트워크의 숨겨진 층을 형성하고 복잡한 시퀀스의 시간 역학 정보를 시뮬레이션할 수 있는 새로운 유형의 반복 신경망(RNN)이라는 것을 발견했다. ESN의 뉴런 간 연결은 sparse하며, 연결 관계는 무작위로 생성된다. 네트워크 훈련 동안 ESN은 가중치의 전역 최적화를 보장할 수 있고, 로컬 최적화를 극복할 수 있으며, 높은 일반화 능력을 가지고 있다. ESN은 수명 예측과 같은 시계열 예측 분야에 미리 적용되어 왔다. 그러나 전통적인 ESN 네트워크의 입력 계층이 동시에 다른 요소를 처리할 수 없다는 것을 발견했다.
본 논문에서는 imESN의 입력으로 HI 곡선 값을 사용한다. imeESN은 네트워크 매개 변수를 최적화하여 서로 다른 입력 값을 적응적으로 처리하고 터보팬 엔진의 RUL 예측을 수행하여 수렴을 가속화하고 로컬 최적화 문제를 해결할 수 있다.
1. imSSAE는 사전 처리된 데이터의 심층 특징을 추출하고 축소하도록 설계되었으며 각 엔진의 해당 HI 곡선이 생성된다.
2. 엔진 유닛의 각 HI 곡선에 대응하는 Te RUL 값은 시간 ESN에 의해 예측된다.
본 논문에서 제안된 방법은 HI 곡선 효과, RUL 예측 정확도 및 오류 제어에서 다른 방법을 능가하여 우리 방법의 실현 가능성과 효과를 입증한다.
방법론
A. 제안된 RUL 예측 모델의 framework
본 모델은 feature extraction에서 SSAE의 장점과 시계열 데이터를 처리하는 ESN의 장점을 결합한다. 개선된 SSAE로 각 엔진의 feature와 고유값을 얻은 다음, 각 엔진의 HI는 데이터 세트의 서로 다른 엔진의 고유값으로 구성되며, HI는 개선된 ESN에 입력된다. HI 곡선은 시간에 따라 변하며, 이러한 변화는 연속적인 고유값으로 간주될 수 있다.
마지막으로, 이러한 고유값은 개선된 ESN에 의해 처리되고 해당 RUL 값을 형성한다.
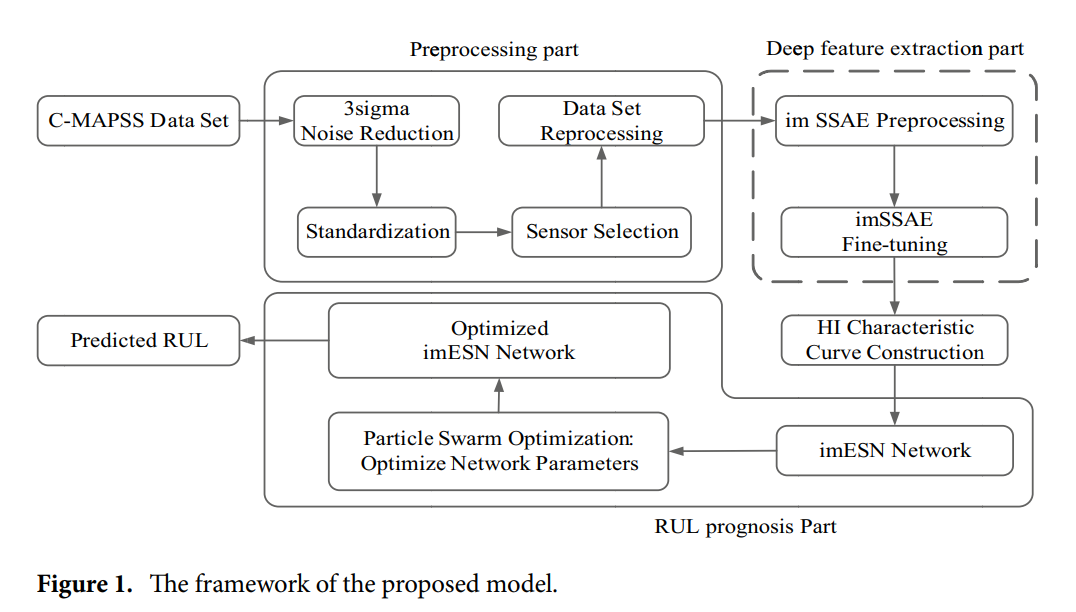
이 모델은 세 가지 주요 부분, 즉 전처리, 심층 feature 추출 및 RUL 예측으로 나뉜다.
B. IMSSAE
기존의 SSAE는 전체 네트워크 계층을 계층별로 훈련시킨다. SSAE는 먼저 각 hidden layer의 sparse AE unit을 사전 훈련한 후 스택한 후, 마지막으로 전체 역 최적화 훈련을 수행하여 여러 idden layer가 있는 SSAE를 얻는다. 이러한 구조는 훈련 효율을 향상시킬 수 있지만 불충분하다.
imSSAE의 구성 단위는 deep feature 처리 효과를 향상시키기 위해 개선되었다. 다음은 imSSAE의 추론 과정이다.
sparse AE는 AE와 같이, encoder의 가중치와 offset을 update하고 반복적으로 최적화하고자 back propagation과 gradient descent 알고리즘을 적용한다. 이때 MSE는 최소화된다. AE의 목표는 input X와 output X'를 근사하게 만드는 것이다.
actiavation function의 세팅도 hidden layer, output layer 그리고 MSE function의 결과에 영향을 준다. 주로 sigmoid가 사용된다. 뉴런의 입력값이 zero point에서 멀 때, sigmoid의 미분값은 거의 0에 가깝게 작다. 터보팬 엔진 데이터 셋에선 지나치게 많은 샘플들의 수렴이 느려지고 gradient가 사라질 것이다. 이를 해결하기 위해 우리는 sigmoid 대신 tanh를 사용한다. sigmoid와 비교해서 tanh는 saturation 기간을 지연시킨다. 또한 tanh는 feature들이 뚜렷하게 다를때 잘 작동한다.
training 동안 입력 값의 분포는 깊이가 증가함에 따라 편향되고 back-propagation 동안 기울기가 쉽게 소실된다. 기울기 소실을 피하기 위해 SSAE의 hiddenlayer 앞에 BN(batch normalization layer)를 추가하여 "input layer-BN layer-hidden layer" 구조를 만든다. 각 hidden layer에 BN layer가 추가된 후, 입력값의 분포는 nonlinear functon에 매핑한 이후 점차 값 범위의 limit saturation area에 도달하여 standard normal distribution(평균이 0이고 분산이 1인)으로 강제된다. 따라서 nonlinear transformation function의 input이 model learning을 가속화하고 네트워크 파라미터 조정을 단순화시켜 sensitive area로 떨어지도록 만든다.
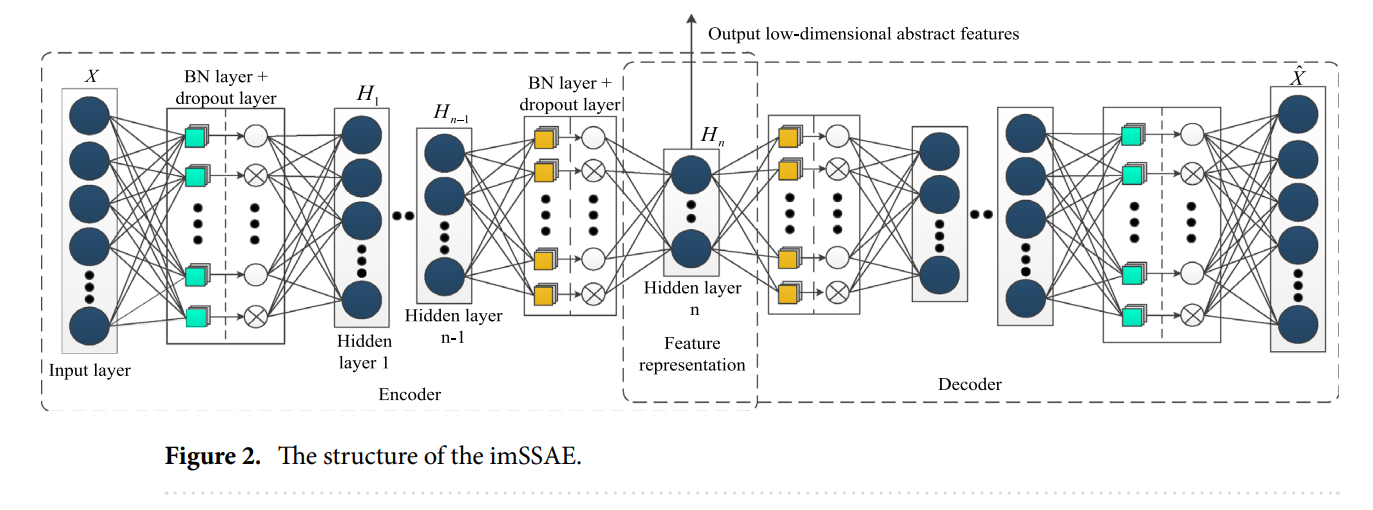
기울기 소실 문제에 추가로, SAE는 loss function에 KL 분산을 regular term으로 추가하여 전체 네트워크의 희소성을 제한한다. 그러나 터보팬 엔진 데이터셋은 preprocessed되었고, deep effective feature들이 추출되어있다. 그래서, normalization은 deep effective feature와 subsequent HI를 [0,1] 사이의 범위로 제한한다.
SAE의 희소 제약 조건으로서의 KL 분산은 주로 값이 0 또는 1인 분류 문제에 적용된다. 따라서 average activity는 네트워크에 패널티를 줄 basis로 사용할 수 없다. 이 문제를 해결하려고, dropout layer를 추가하여 SAE의 희소성을 실현시킨다. BN layer와 유사하게 dropout layer는 hidden layer의 encoding, decoding 중 activation function 이전에 도입된다. Dropout 매커니즘은 encoding과 decoding 중 무작위로 뉴런 활성 값을 비활성화하며 희소성 제약 조건을 달성한다. 활성화 값을 0으로 세팅하면, 가중치와 offset은 학습 중 업데이트되지 않으며 원래의 encoding과 decoding 과정에 영향을 주지 않는다.
C. HI construction
대부분의 RUL 예측 모델은 RUL 값을 표시하기 위해 목적함수를 사용하는데, 센서 데이터를 신경망에 입력해서 RUL을 직접(바로) 예측하는 것이다. 이는 목적 함수 하에서 같은 health level인데 다른 RUL 값을 초래한다. 이를 해결하고자 엔진의 열화 추세를 설명하는 HI 곡선을 구축하기 위해 engine feature를 채택한다.
imSSAE에 의해 featuer extraction 이후, 각 엔진에 따라 1차원 고유값이 얻어지고 각 고유값은 고장과 열화 상태를 구별할 수 있는 엔진 수명 주기의 multisensor 데이터 정보를 나타낸다. data training동안, 1차원 고유값에 따라 엔진 수명 주기의 실시간 상태 특징, 과거 열화 특징 및 엔진 고장 특징을 얻는다.
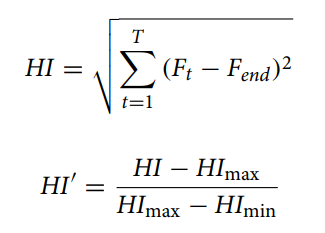
HI 값이 0이면 엔진이 완전히 고장났음을 나타내고 HI 값이 1이면 엔진이 정상임을 나타낸다. HI 곡선의 효과를 정량적으로 평가하기 위해 시간 관련성(상관관계)과 단조성을 평가 지표로 제안한다.
D. imESN
전통적인 ESN 네트워크는 입력 계층의 요소들을 동일한 유형의 전체로 간주한다. 터보팬 엔진의 데이터 세트에서 신경망의 입력은 엔진의 HI 곡선 값으로, 본질적으로 엔진의 다양한 특징을 나타낸다. 따라서 ESN을 개선해야한다.
추출한 엔진의 다양한 feature을 적응적으로 처리하고 요소가 신경망에 완전히 입력되고 올바른 결과가 출력되도록 하기 위해 본 논문에서 ESN 네트워크에 attention 메커니즘을 추가한다.
imESN의 예측 정확도를 향상시키려면 imESN의 내부 매개 변수를 최적화하여 모델이 최상의 상태를 달성하도록 해야 한다. improved particle swarm optimization algorithm은 imESN의 매개 변수를 최적화하기 위해 채택된다.
E. Model training
훈련의 목표는 비용 함수와 손실 함수를 최소화하고 최상의 매개 변수를 얻는 것이다. 모델의 훈련은 주로 imSSAE 훈련과 imESN 훈련으로 나뉜다. imSSAE의 fine tuning 단계에서는 Adam 알고리즘을 사용하여 매개 변수를 최적화하며 전체 training 과정은 early stopping을 채택하여 모델의 효과를 검증하고 과적합을 방지할 수 있다.
다음에서 계속
