Remaining useful life prognosis of turbofan engines based on deep feature extraction and fusion 下
Experiment and analysis
A. Dataset description
C-MAPSS
FD001~FD004의 엔진 작동 조건은 서로 다르다. 이 데이터 세트의 각 엔진은 사용자가 사용할 수 없는 초기 마모 정도가 다르며 데이터 세트에 많은 무작위 노이즈가 혼합된다. 엔진이 고장날 수 있고, 시간이 지남에 따라 엔진의 작동 데이터가 멈추는 것을 관찰할 수 있으며, 이때 센서는 열화를 포착한다. 21개의 센서(팬 흡입구의 총 온도 센서 등), 3개의 실행 매개 변수(즉, 격투 고도, 마하 수 및 스로틀 리졸바 각도), 각 엔진의 엔진 식별 및 사이클이 있습니다. 센서는 엔진 성능 저하를 포착할 수 있으며, 이 능력이 RUL 예측을 실현하는 핵심이다.
B. Data preprocessing
상당한 랜덤 노이즈가 포함되어 있기 때문에 사전 처리가 필요하다. 사전 처리는 데이터의 유효성을 보장하고 실험 오류를 줄인다. FD001 데이터 분포는 (μ - 3μ, μ+3μ) 구간에서 거의 집중되어 있으며, 그 비율은 99.73%이다. 이 구간을 초과하는 나머지 데이터는 0.27%이며 이 부분은 총 오차에 속하여 원래 데이터의 노이즈로 간주된다.
원본 데이터의 노이즈를 줄이기 위해 3-시그마 기준을 채택한다. 3-시그마 기준은 모니터링 오류를 제거하고 데이터 오류가 예측 정확도에 미치는 영향을 피할 수 있으며, 다른 방법과 비교하여 원본 데이터에 영향을 미치지 않으며 입력 데이터의 신뢰성을 보장한다. 여러 측정 데이터의 정확도와 분포가 동일하다고 가정하면 3-시그마 기준을 사용하여 측정 데이터의 총 오차를 제거할 수 있다.
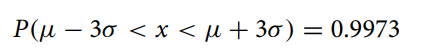
(뮤는 표본의 평균값, 시그마는 표준편차)
데이터 세트의 각 실행 주기에 대한 모니터링 데이터는 가우스 분포를 따른다. 모든 엔진 작동 주기의 21개 센서 신호에 대해 노이즈 제거를 위해 3-sigma를 사용하고, 동일한 조건에서 다중 데이터 샘플링을 수행하여 모니터링 데이터의 각 그룹의 오류와 노이즈를 제거한다.
노이즈 제거 후, 모든 엔진 수명 주기에서의 센서 모니터링 데이터의 추세를 분석하여 열화 데이터를 얻는다. 엔진 열화에 따른 센서 신호의 변화 추세는 단조 상승, 단조 하강, 불규칙 변화, 상수 값의 4가지 유형으로 나눌 수 있다. 일정한 추세를 보이는 데이터는 전처리 단계에서 삭제하고(14개의 센서만 남음) train, test 데이터 세트를 재구성한다. 센서간 차원 영향을 제거하고 수렴 속도를 개선하기 위해 정규화 방법 중 minmax scaler를 사용한다.
C. Parameter settings
매개 변수 설정에는 주로 imSSAE 및 imESN가 포함된다. five-fold cross-validation 방법이 서로 다른 파라미터를 가진 모델의 훈련에 사용된다. imSSAE의 구조는 14-8-4-1이며, 이는 입력 노드가 14(각 실행 주기의 14차원 센서 데이터 값), 숨겨진 두 레이어의 노드가 8, 4, 출력 노드가 1이며 HI 곡선을 구성하기 위해 하나의 출력 고유값을 채택한다는 의미이다. imESN에서는 particle swarm optimization algorithm을 사용해서 매개 변수를 최적화하고 검증을 위해 five-fold cross-validation을 적용하며 과적합을 완화하기 위해 두 번 실행된다. RMSE 값을 평가 지표로 사용하여 모수를 조정하고 예측 효과를 향상시킨다.
D. Experiments result analysis
각 running cycle이 하나의 feature를 가질 수 있도록 각 running cycle의 14 차원의 센서 데이터를 imSSAE의 인코더에 입력한다. 그 후, feature들에 따라서 HI 값을 구성하고 마지막으로 각 엔진의 HI 곡선을 구한다.
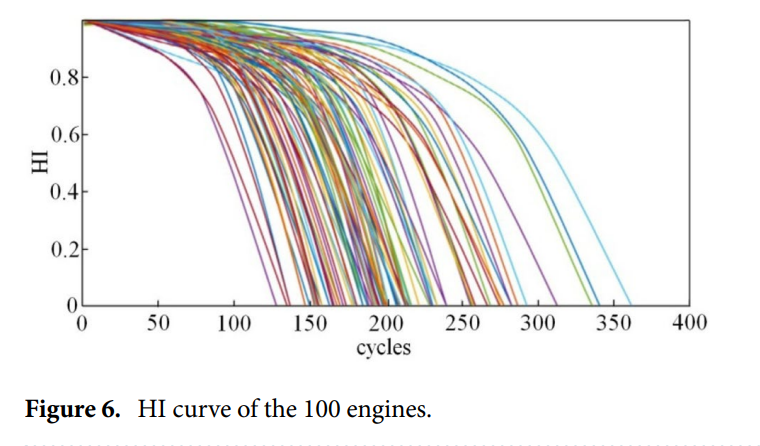
다음은 100개의 엔진의 HI 곡선이다. origin HI 곡선의 특징이 변경되지 않도록 fitting 및 smoothing이 수행된다. HI 곡선은 엔진의 열화 과정을 잘 설명할 수 있고, 단조도가 좋다.
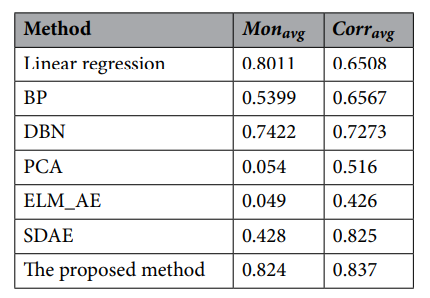
HI 곡선의 효과를 잘 측정하기 위해 HI 곡선 평가 지수를 이용하여, 다중 센서 열화 상태 모델링의 일반적으로 사용되는 방법과 본 논문에서 제안된 방법을 비교한다. 본 논문에서 제안된 방법이 시간 관련성 및 단조성 측면에서 다른 방법보다 우수하다는 것을 보여준다. 우리의 방법은 주로 데이터 처리 전에 노이즈 감소 및 데이터 세트의 재구성을 수행하여 단조성이 향상되고 간섭이 거의 없기 때문이다. 대조적으로, PCA와 ELM_AE는 노이즈 간섭으로 인해 단조로운 불일치를 가지고 있어 단조로운 감소를 초래한다. 높은 시간 상관관계는 잠재적인 성능 저하 feature를 포착하는 기능이 강력하다는 것을 나타냅니다. 요약하면, 본 논문에서 제안한 방법의 특징 추출과 HI 구성은 엔진의 열화 과정을 더 잘 반영할 수 있다.
각 엔진 유닛의 RUL을 분석하기 위하여, target RUL을 결정하기 위해 piecewise linear degradation model이 제안되었다. 엔진의 작동 상태는 초기 단계에서 정상으로 간주될 수 있으며, 일정 시간 동안 작동하거나 어느 정도 엔진을 사용한 후에는 저하가 명백하다. 즉, 엔진의 정상 작동 상태는 일정한 값이며, 일정 시간이 지나면 엔진의 RUL이 선형적으로 감소하게 된다.
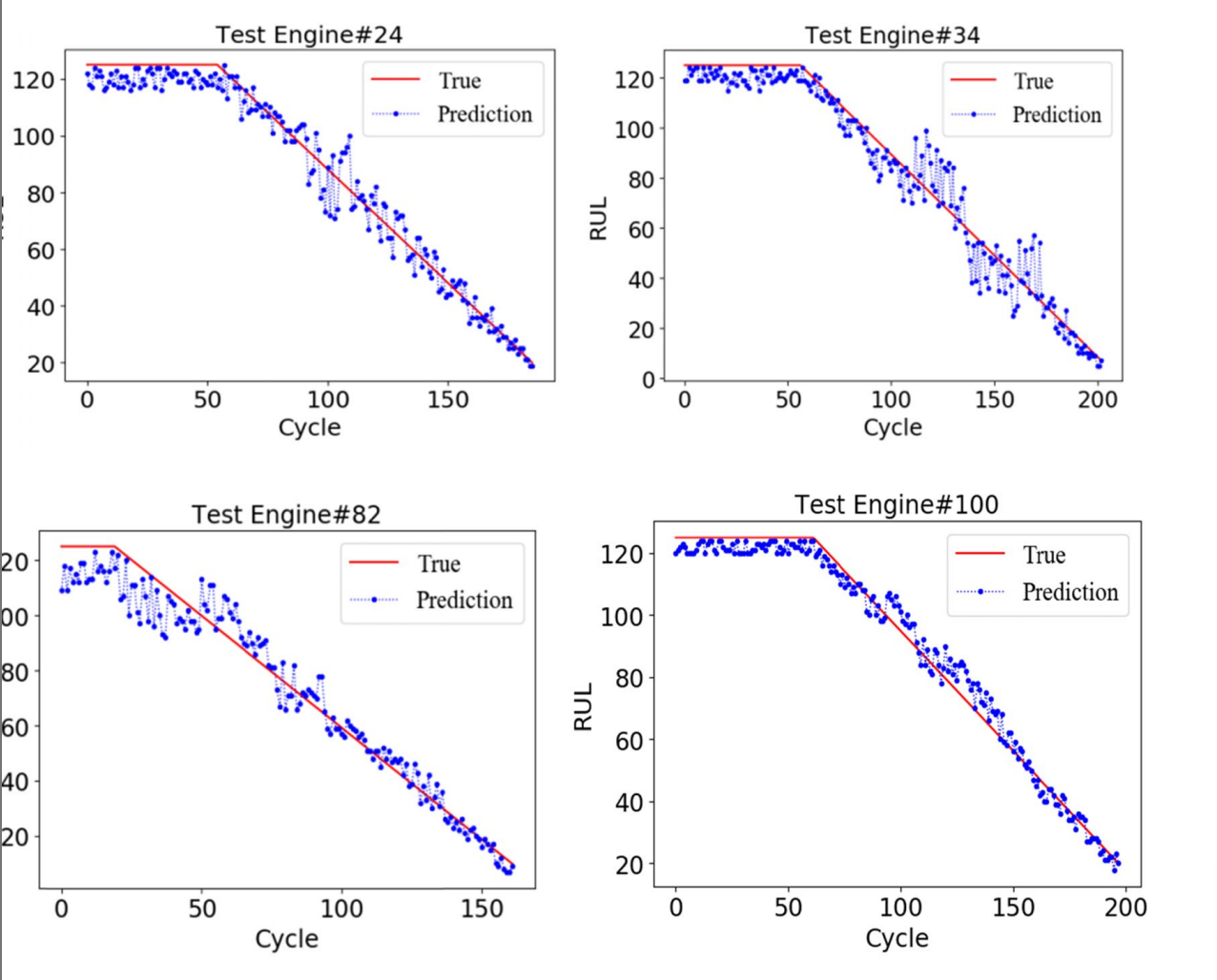
열화단계에서의 관찰 데이터의 초기 상수 RUL 값을 125로 하고, 4개의 unit의 RUL 예측 결과를 무작위로 선정하였다. 그림은 초기 RUL 예측이 상수 값에 가깝기 때문에 엔진이 정상 상태임을 나타내며, running 사이클이 증가함에 따라 고장이 발생한다는 것을 보여준다. 예측 결과는 기본적으로 고장이 발생할 때까지 선형적인 감소를 보여주며, 일부 엔진(82 등)은 초기 열화 추세가 미미하여 초기 예측 효과가 좋지 않다. cycle이 증가할수록 예측 오차는 감소한다. 엔진의 예측 효과는 고장이 가까울 때 가장 좋기 때문에 이때의 특징이 가장 두드러지는 것을 알 수 있다.
실험에 따르면 SAE는 특징을 추출하고 고차원에서 저차원으로 매핑한다. 차수 차이가 너무 크고 hidden feature가 부정확하면 실험 결과가 이상적이지 않다. 그러나 imSSAE는 stacking 형태로 feature를 한 층씩 추출하고, 훈련 효율성을 향상시키며, 최종 hidden features가 원본 데이터를 더 잘 표현할 수 있다.
attention mechanism이 없는 ESN은 feature들을 adaptively하게 처리할 수 없으며 따라서 해당 데이터를 처리할수 없다. attention meachanism이 있는 ESN은 feature들을 적응적으로 처리하고 네트워크의 내부 매개 변수를 최적화 및 업데이트할 수 있으므로 네트워크의 내부 매개 변수가 최적의 상태에 도달하고 예측 정확도를 향상시킬 수 있다.
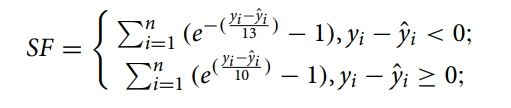
scoring function(SF) : RMSE는 예측의 측면에서 조기 예측과 나중의 예측에 대한 처벌이 동일하다. SF는 후발 예측보다 조기 예측(RUL 예측 값이 실제 값보다 작음)에 더 치우친다. 즉 과대평가된 값에 대해서는 더 큰 벌칙을 적용하고 과소평가된 값에 대해서는 더 작은 벌칙을 적용한다.
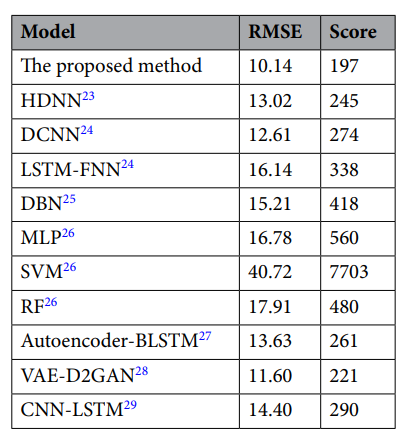
본 논문에서 제안된 방법은 다른 방법과 비교하여 RMSE와 점수라는 두 가지 점수 지표 중 최소값을 갖는다. 신경망 구조가 엔진에서 다양한 특징을 적응적으로 추출하고 네트워크 매개 변수를 최적화하여 모델의 예측 효과를 향상시킬 수 있기 때문에 이러한 결과를 얻는다.
IMSAE의 인코더가 저차원이며 더 효과적인 feature을 얻을 수 있다.
feature 추출 전의 데이터 전처리가 더 유리하고, C-MAPSS 데이터 세트에서 이 방법의 예측 정확도가 향상되며, 이 방법을 사용하여 전문 지식과 물리적 지식 없이 터보팬 엔진의 유지 보수 시간을 예측할 수 있음을 보여준다.
Conclusion
본 연구에서는 사전 지식이 거의 없는 feature을 자동으로 추출하고 HI 곡선을 구성하는 심층 feature 추출 기반 방법을 제안하고, 또한 입력 데이터에 존재하는 상이한 feature 정보가 존재하는 현상에 직면하여 터보팬 엔진인 RUL 예측의 성능을 향상시키기 위한 attention 메커니즘을 제시하였다. 그러나 여전히 개선의 여지가 있으며 추가 연구가 필요하다.
본 연구에서는 데이터 집합의 표본이 균형을 이룬다고 가정하였는데, 불균형 표본은 예측 효과에 영향을 미칠 것이며, 데이터 집합의 불균형을 고려하도록 현재의 접근 방식을 수정해야 한다.
또한, 실험에서의 고장 임계값은 데이터 세트에 주어지는데, 서로 다른 데이터 세트에 따라 고장 임계값을 적응적으로 계산하는 방법이 새로운 연구의 주제이다.
추가로 공부해볼 내용 : 3-시그마, ESN, 종류별 AE, HI curve, monotonicity
