
https://github.com/facebookresearch/frankmocap
맨 처음했던 것은 해당 코드를 한번 돌려보는 것이었다. 해당 코드의 논문을 읽어보았는데, 수식적인 모델링 부분부터는 관련 지식이 없어서... 읽기가 어려운 관계로 introduction 정도로만 읽었다
frankmocap overview 포스팅
대충 whole-body 3D pose estimation system이며 모듈식 구조를 사용해 처음에는 개별적으로 얼굴, 손, 몸에 대한 3D pose regression을 한 후 integration module을 통해 SMPL-X 모델 형식으로 통합하여 결과를 생성한다!!
개별 모듈을 사용하는 이유로는
- whole body pose 관련 데이터가 부족함
- 개별 모듈을 사용해 SOTA 성능을 유지
- 빠르고 정확한 성능
깃클론 이후 먼저 환경을 세팅해야하는데 여기서 꽤 고생했다. 랩실 서버를 쓰기가 애매해서 window에서 anaconda로 설치하려는데 버전 충돌인지 뭔지... 휠도 안되고...
https://github.com/carlosedubarreto/frankmocap_win_install
여기 참고해서 겨우겨우 설치했다
실행을 해보자
miniconda를 열고 클론해온 디렉터리에 들어가서 가상환경을 켜준다(내 경우 가상환경 이름은 frankmocap)

Quick Start에 적힌대로
python -m demo.demo_bodymocap --input_path ./sample_data/han_short.mp4 --out_dir ./mocap_output요 코드를 실행해보자! 내 input 영상 경로와 output 경로를 지정해주면 된다
해당 코드는 output을 스크린에 띄워주는 코드이다 코드 맨 앞에 python 대신 xvfb-run -a python을 쓰면 스크린 없이 돌아간다


이런 식으로 입력 영상이 frame마다 왼쪽에는 원본 + detection box랑 오른쪽은 원본 + whole body pose mesh 이렇게 촤르륵 스크린에 뜬다
지정해준 output 경로에 가면
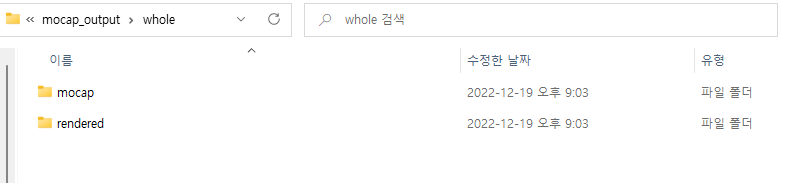
요렇게 mocap과 rendered 두 폴더가 생긴다 rendered에는 screen에 띄웠던 output이 frame마다 jpg로 저장된다
window에서 하는 경우
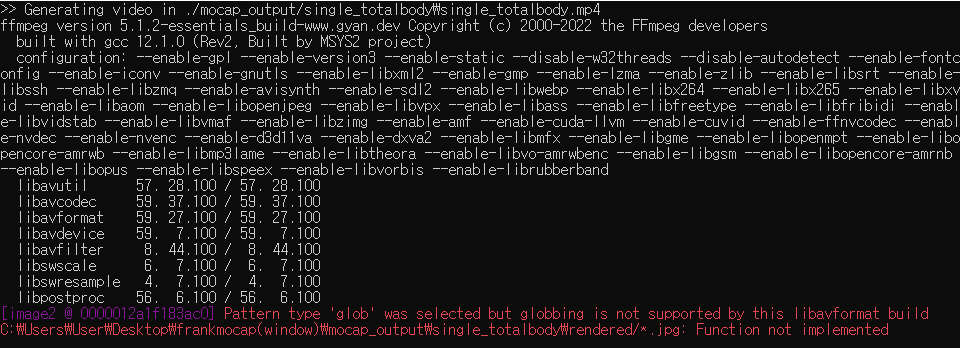
요런 경고가 뜨는데 원래는 자동으로 저 jpg들을 모아서 영상으로 해주는거 같은데 import glob이 윈도우에서 안되므로 오류가 뜬 것 같다
cat *.jpg | ffmpeg -f image2pipe -i - output.mkv요 코드를 써주면 output jpg들을 모아서 영상으로 output을 만들어준다!
(velog는 동영상을 못올리는거 같아서 영상을 gif로 바꿈)

