이캅스에서 이번 홈커밍데이 때 프로젝트 발표자를 모집하길래,, 짧은 시간 안에 할 수 있는 정보보안 관련 프로젝트를 찾아보았다. 요즘 전공 관련 지식대화를 할 때 뇌 회전이 멈추고 말이 입밖으로 나오지 않는 기분이 든다. 아무래도 지식부족이 원인이겠지..
"인공지능 보안을 배우다" 선정이유
- 3-2에 배웠던 '머신러닝' 교과목과 접목시킬 수 있을 것 같아 보였다.
- 책에서 배운 개념을 토대로 쉬운(아직 모름) 인공지능 보안 프로젝트 2개를 제공해주기 때문에, 초보자(나)도 쉽게 책을 통해 프로젝트를 진행할 수 있을 것이라 생각했다.
- 인공지능이 세상을 지배할 것 같다..
1장. 정보 보안과 인공지능의 만남
1장에서는 인공지능에 대한 짧은 소개와 이를 정보 보안에 접목 시켰을 때의 상황에 대해 알려준다. 인공지능은 크게 2가지 방식으로 최적의 행동을 결정한다고 한다.
- 관찰과 가정을 바탕으로 한 경험을 통해 판단 : 데이터 중심 (Data-driven)
- 많은 데이터에서 '패턴'을 찾는 것이 주된 목표 ( 새로운 공격에 취약 )
- 수학과 공학적인 방식으로 판단 : 알고리즘 중심 (Algorithm-driven)
- 무수히 많은 경우의 수 중에서 '최적의 해'를 찾는 것이 목표
- 방어 관점 : 네트워크 침입 탐지, 악성코드 탐지, 침해사고 분석
- 공격 관점 : 탐지 모델 공격, 시스템 해킹 및 취약점 발견
정보 보안 분야의 특수성
1. 정보 보안의 궁극적인 목표는 '완벽한' 공격 차단이 아닌 '빠르고 정확한' 대처다. 그렇지만 공격 차단은 잘해야 한다.
2. 보안 시스템의 기능은 예측 가능해야 한다.
3. 과거의 데이터가 반드시 미래를 말하지는 않는다.
4. 결국 사람이다.
2장. 핵심 머신러닝 기술
머신러닝 프로세스를 간략하게 적어놓아주었다. ( 이 책의 굉장히대단한 장점이라고 생각한다 ) (근데 이거 그냥 막 올려도 되는건가..? 안되면 바로 삭제할게요ㅜㅜㅠ 죄송해요 무지했습니다..)
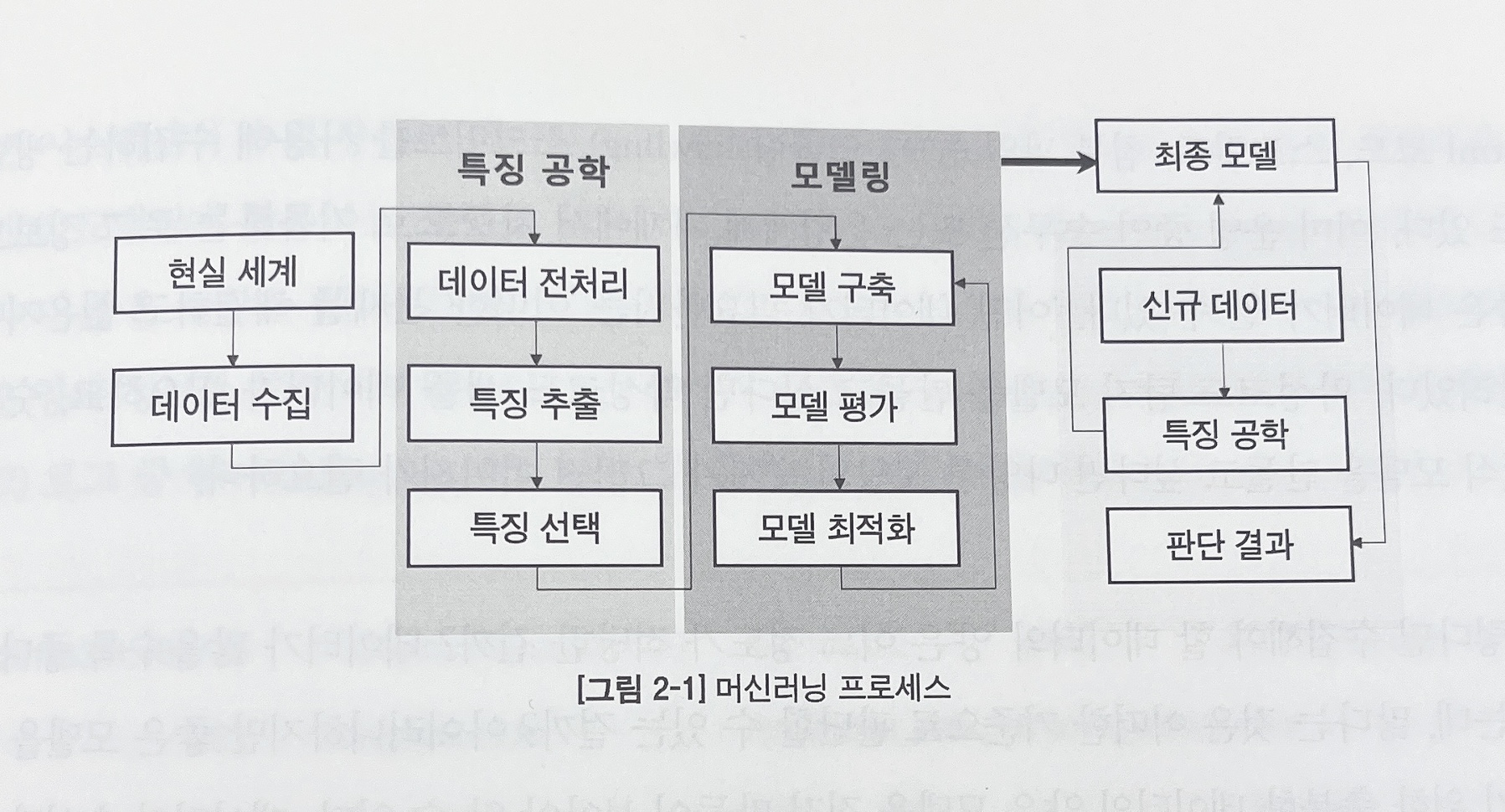
머신러닝 분야의 주인공은 '데이터' !! 가능한 많은 데이터를 확보하는 것이 우선시되어야 한다.
하지만 많은 양의 데이터가 반드시 많은 양의 정보를 보장하지 않는다.
특징공학 (Feature Engineering)
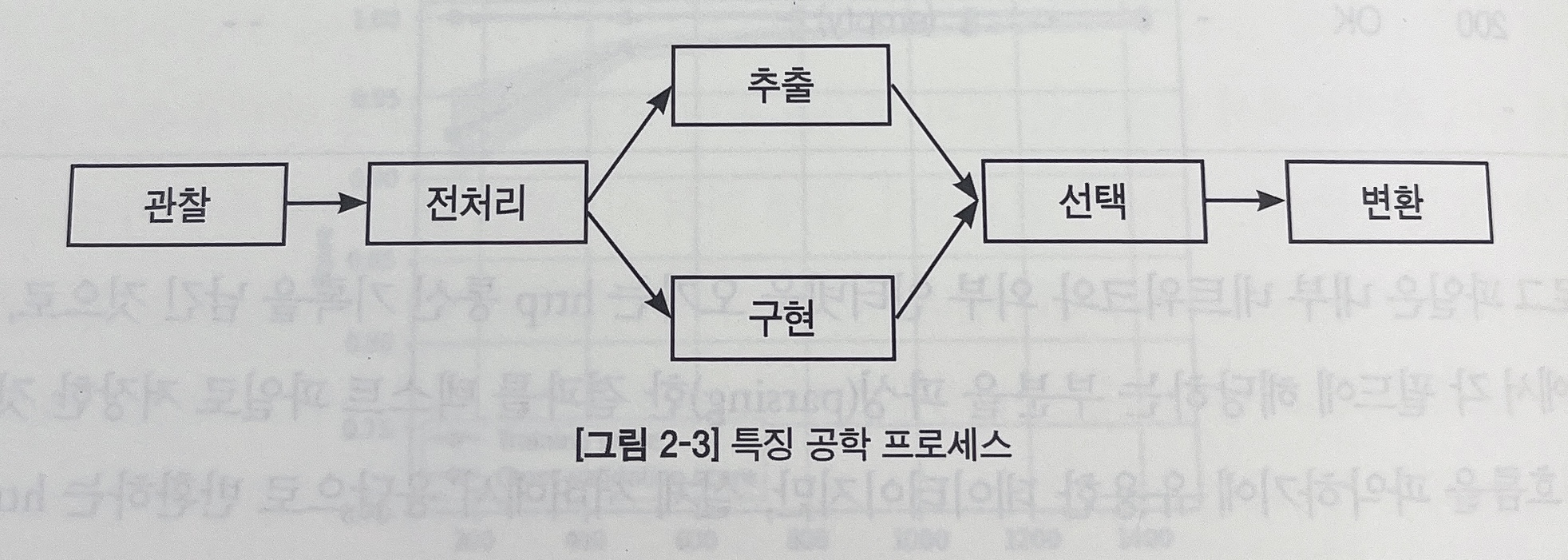
데이터의 의미를 이해하고, 조작하고, 특징을 추출하고, 변환하는 모든 과정을 포함한다. 보통 모든 도메인에 적용하는 가능한 공통적인 기술보다 특정 도메인에 특화된 기술들이 더 많다.
데이터 관찰은 머신러닝에 도움을 주는 정보를 찾기 위함이 아니라, 데이터 자체를 이해하기 위함이다. 데이터 관찰과 전처리 과정은 시각화와 함께 진행해야 한다.
데이터 전처리 완료 후, 특징 추출에는 크게 3가지 방법이 있다.
( 하지만, 3자기 방법 중 무조건 하나를 선택해야 하는 것은 아니다!! )
- 데이터를 그대로 특징으로 사용
- +) 추출이 간단함
- -) 대부분의 데이터는 그대로 사용이 불가능, 좋은 특징을 보상하지 않음
- 통계 수치 활용
- +) 추출이 간단함, 데이터 특성 반영
- -) 통계 수치 해석 능력 필요, 적용 가능 영역이 제한됨
- 도메인 특성을 토대로 추출
- +) 좋은 특징 추출 가능, 최소 특징 최대 효율
- -) 도메인 지식 필요, 해당 분야 전문가의 도움이 필요
좋은 특징 = 좋은 성능을 보장해주는 모델 구축에 도움이 되는 특징
특징 추출 단계에서는 모델링 정확도에 주는 영향도를 고려할 필요가 없다. 데이터에서 추출할 수 있는 가능한 모든 특징을 뽑아 두는 것이 가장 좋다.
특징선택은 이전 단계에서 추출한 특징 중 모델링에 사용할 특징 조합을 선택하는 단계를 의미한다. ( 무작정 특징을 골라내는 방법보다 후보군을 선정한 후, 전진선택 또는 후진제거 방식 적용 추천 )
가능한 모든 특징을 판단에 사용하는 것은 좋지 않을 수 있다. '하나의 특징 = 하나의 정보 = 1차원' 너무 많은 정보는 모델 성능에 독이 될 수 있다.
특징선택을 위한 모델링은 해결하고자하는 문제에 적용 가능한 모델은 3~5가지 정한 다음에 선택한 특징 조합을 대입해보는 방식이다.
변환은 특징 값을 모델링에 적합한 형태로 변환하는 과정이다.
- 정규화 : 모든 특징의 값 범위를 동일한 범위로 맞춰주는 과정
- 스케일링 : 특징 데이터를 정규 분포 형태로 변환해주는 과정
- ex) 데이터를 로그 변환
- 범주형 데이터 처리 : 특징 값이 범주형 데이터일 경우 수치형 데이터로 변환하는 것
- ex) One-Hot 인코딩 : 개별 특징 내에 포함된 유일한 문자의 개수만큼 특징을 추가한 뒤 각 특징을 0 또는 1로 표현하는 방식
