오늘의 목표 : 2장 끝내기! 아자아자!
2장. 핵심 머신러닝 기술
모델링
특징 공학 단계를 통해 선별한 특징 조합 데이터를 분석해 최적의 모델을 찾는 단계
' 모델 구축 - 모델 평가 및 최적화 단계 '로 구분된다.
목적 : 데이터를 가장 잘 표현해주는 선을 찾는다 = 데이터를 대표하는 하나 이상의 함수를 찾는다 = 일반화를 한다.
머신러닝 모델 성능 개선 방법 : 데이터와 모델을 나누는 방법을 개선
1. Bagging (배깅) : 전체 데이터를 여러 개의 샘플 데이터로 나누어 여러 번 학습한 뒤 전체 결과를 집계해 판단하는 방법
2. Boosting (부스팅) : 각 샘플 데이터로 모델을 학습하고 최종 판단은 각 모델의 판단 결과를 더해 많은 쪽에 손을 들어주는 (가중치 부여) 방식
3. Stacking (스태킹) : 서로 다른 모델을 조합해 최고의 성능을 내는 모델을 만드는 방식
무조건 복잡한 모델을 사용한다고 해서 성능이 좋아진다고 보장할 수 없다
모델 평가를 할 때에는 이 세상 어디에도 완벽한 모델은 존재 하지 않는다는 사실을 받아들여야 하며, 항상 만든 모델이 정확하지 않을 수도 있다는 전제하에 모델을 평가해야 한다.
정보 보안 영역에서는 분류 알고리즘이 가장 많이 사용된다.
모델 정확도 측정 기준 : 혼돈 행렬 (Confusion Matrix)
Actual : 실제 정답 값 // Predicted : 모델 예측 값

ex ) 악성코드와 정상 프로그램을 분류하는 모델
False Negative : 정상으로 판단한 것(Negative)이 틀렸다(False) : 오탐(재현율)
False Positive : 악성코드로 판단한 것(Positive)이 틀렸다(False) : 과탐(정밀도)
정확도 (Accuracy) : TP + TN / TP + FN + FP + TN
재현율 (Recall) : TP / TP + FN
정밀도 (Precision) : TP / TP + FP
모델 성능 평가 후 개선 방법
- 모델 옵션 변경 (SVM의 C와 gamma, 랜덤포레스트 트리의 깊이 등)
- 모델 변경
- 특징 조합 변경 (불필요한 특징 제거 또는 새로운 특징 추가)
- 모델 옵션 + 모델 + 특징 조합 변경
- 특징 공학 단계부터 다시 수행 (특징 추출을 새로하거나 새로운 특징 조합 탐색)
모델 실전 배치 방식
- 온라인 방식 : 새롭게 유입되는 데이터를 새로운 학습 데이터로 활용해 지속적으로 모델을 업데이트하는 방식
- 오프라인 방식 : 학습을 통해 만든 모델을 일정 기간 그대로 사용하다가 정기적으로 모델링을 새롭게 하는 방식
통계학과 머신러닝
통계학 : 데이터에서 의미를 찾아내는 학문
머신러닝 : 데이터에서 찾은 의미를 활용하기 위한 학문
1) 데이터 중심 경향
-
평균
- 데이터의 모든 값을 더한 수 / 데이터의 전체 개수
- 데이터의 중심 경향을 나타내는 가장 기본적인 지표
- 평균의 함정 : 데이터의 주 분포에서 벗어난 이상치(outlier)로 인해 발생
-
중간값
- 전체 데이터를 정렬한 후 가운데에 위치한 값
- 데이터 값의 분포가 극단적으로 퍼져 있을 경우 데이터의 중심 경향을 판단할 수 없다.
-
최빈값
- 데이터에서 가장 많이 나타나는 값
- 실수형 데이터의 경우 정확히 동일한 값이 충분히 누적되기 어렵다.
-
범위 정보
- 데이터 최대값 - 최소값
- 평균, 중간값, 최빈값과 함께 사용할 경우 데이터 분포 파악에 효과적이다.
-
사분위 수
- 데이터를 4개의 조각으로 나눈 뒤 가운데 위치한 두 개의 조각 (Q1~Q3)
- 이상치 값의 분포 확인뿐만 아니라, 이상치를 배제한 데이터의 중심 파악, 왜도, 첨도를 쉽게 확인 가능하다.
머신러닝에서 확률을 크게 2가지 관점에서 사용한다. 분포 & 조건부 확률
2) 확률
조건부 확률 : 어떤 사건 B가 일어났을 때, 사건 A가 일어날 확률
이를 공식으로 잘 정리한 것 : Bayes Therorem (베이즈 정리)
대표적인 예시에는 스팸 메일 분류기가 있다.
3) 분포
데이터의 평균을 기준으로 넓게 퍼져 있는 경우 : 분산이 크다
데이터가 평균을 기준으로 밀집되어 있는 경우 : 분산이 작다
데이터의 분포는 수치상으로 판단이 어려운 정보도 쉽게 식별해낼 수 있도록 도와준다.
뉴럴 네트워크와 딥러닝(Deep Learning)
(참고로 이거 지금 머신러닝 시간에 배우고 있는거당 ㅎㅎ 반갑구만~)
뉴럴 네트워크
- 인간의 뇌를 구성하는 뉴런과 수많은 뉴런이 서로 복잡하게 얽혀 유기적으로 동작하는 매커니즘을 '인공적으로' 구현한 모델
- 내부 동작과 방식, 즉 모델이 최적의 선을 찾아가는 방법을 분석가가 결정하고 설계해야 하는 모델
- 최소 단위 : 퍼셉트론
- 퍼셉트론이 입력을 받아 그 입력이 특정 값 이상이 되면 다음 퍼셉트론으로 신호를 전달한다

- x1 (단일특징) : 실제 분석가가 제공하는 데이터
- x0 = 1 : 기본적으로 할당되는 요소
- w : 가중치
- 단일 퍼셉트 론을 하나 학습하면, 주어진 데이터를 표현하는 가장 최적의 직선 하나를 찾아낼 수 있다.
- 뉴럴 네트워크 = 퍼셉트론을 여러 개의 레이어로 연결한 구조
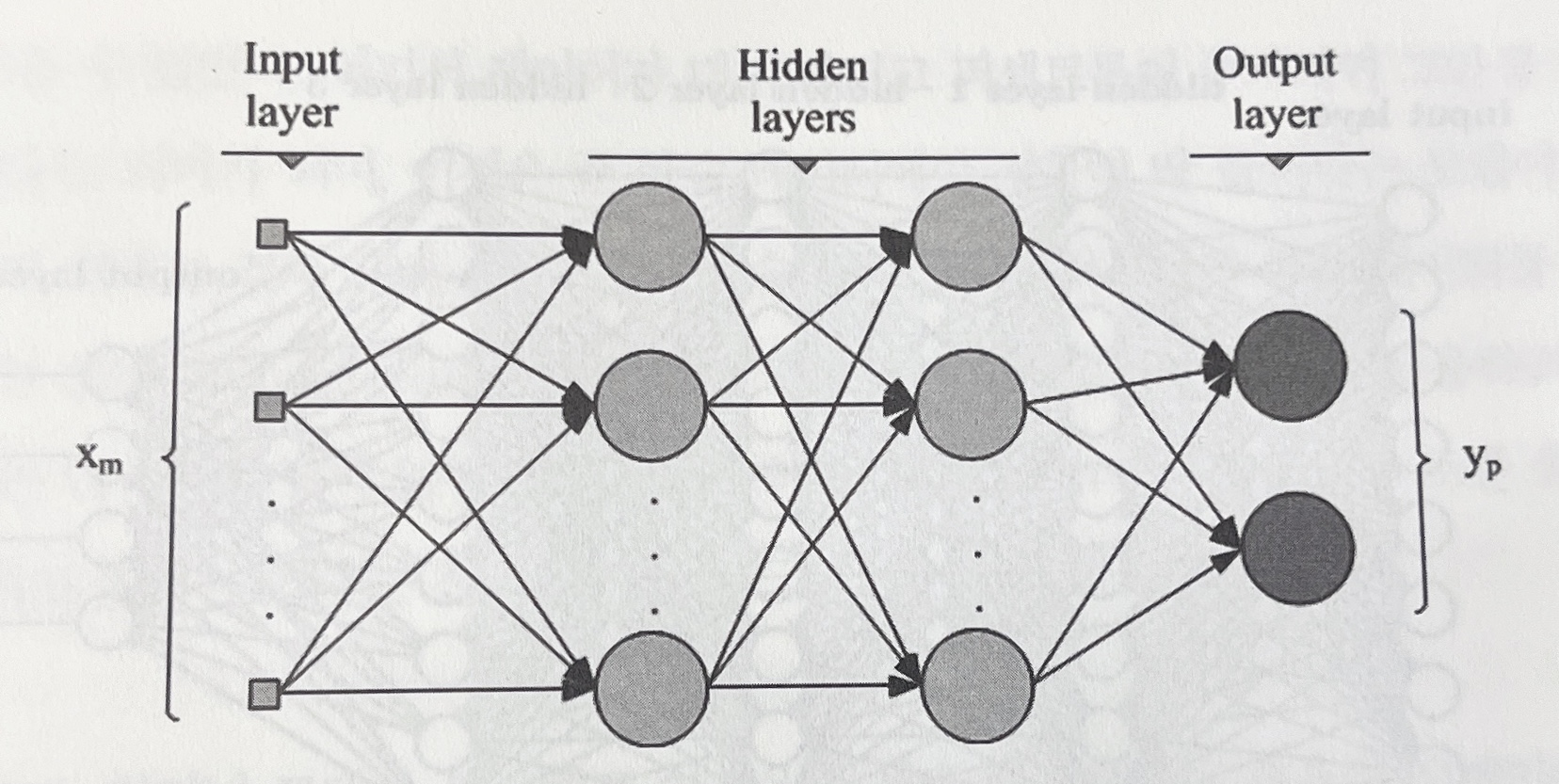
뉴럴 네트워크 기반 모델은 퍼셉트론의 개수, 레이어의 개수, 네트워크 구조, 가중치를 계산하는 방식, 학습을 하는 방식, 성능 개선 방식 등 모든 것을 다 분석가가 직접 설계해야 한다.
레이어가 추가되고, 퍼셉트론이 추가된다는 것은 학습 데이터에만 딱 들어맞는 모델이 만들어질 가능성이 크다는 것 = 신규 데이터를 잘 판단하지 못하는 overfitting(오버피팅) 현상 발생 가능
이렇게만 보면, 딥러닝 모델이 매우 좋아보이지만, 정보 보안 분야에서는 널리 활용되지 못한다.
왜냐! 딥러닝 모델을 사용하면 특징과 모델의 결과값 사이의 인과 관계를 파악할 수 없다.
3장. 핵심 파이썬 기능
책에서는 활용성과 정보 보안 특수성을 고려해 모든 실습을 파이썬으로 진행한다.
머신러닝 모델링 시 모든 데이터는 테이블 형태로 존재한다는 가정으로 처리한다.
= 모든 데이터는 관계형 데이터베이스에 저장되는 형식을 가진다고 보면 된다.
필요에 따라 데이터의 특정 요소 또는 범위 데이터에 접근하고, 데이터를 분할, 병합, 수정할 수 있어야 한다.
이제! 환경 구축을 해보겠습니다~ 저는 M2 맥을 사용하기 때문에, UTM을 사용합니다.
기존에 사용하고 있던 Ubuntu(UTM Gallery를 이용한, Ubuntu 22.04)가 있기 때문에, 이를 활용한다.
sudo apt-get update
sudo apt-get upgrade
sudo apt-get install vm를 완료했으면, ubuntu 내의 firefox에 들어가 아나콘다를 다운로드 받아준다.
나는 아래의 사진에서 가운데에 있는 ARM64용을 다운받아주었다.
(Velog 사진크기 줄이는 방법이 뭘까..?)
cd Desktop
chmod 755 ./Anaconda3-2024.10-1-Linux-aarch64.sh
sudo ./Anaconda3-2024.10-1-Linux-aarch64.sh라이선스를 열람하라는 말 > yes > Enter 누르고 한참 있다가 > yes > 아나콘다 설치 경로 확인후 > Enter
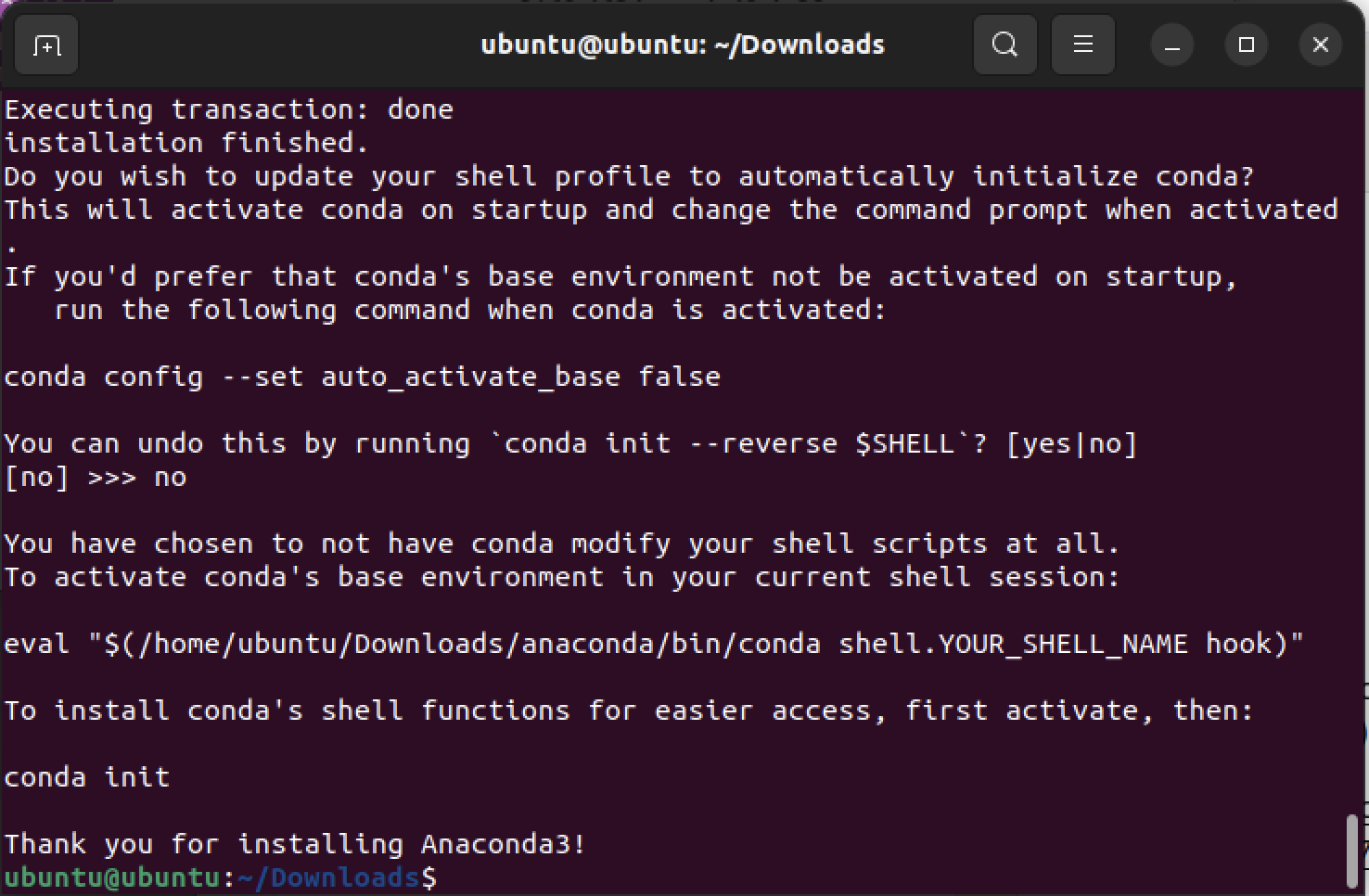
설치 후 이런게 뜨길래, 항상 anaconda를 사용할 건 아니라서 no를 했다.
터미널 재실행 후, 매번 anaconda 파일로 가기 귀찮아서
echo "source ~/Downloads/anaconda/etc/profile.d/conda.sh" >> ~/.bashrc
source ~/.bashrc코드를 입력해 주었다.
conda -V명령어 사용시, conda 24.9.2 가 뜨면, 설치 완료!
파이썬 가상환경 만들기
아나콘다를 이용해 가상환경을 만들어보자. 책에서는 파이썬 2.7 버전을 주로 사용할 예정이라고 하지만, 최신버전 아나콘다에서는 파이썬 2.7이 안되기 때문에, 나는 파이썬 3.9를 사용하겠다.
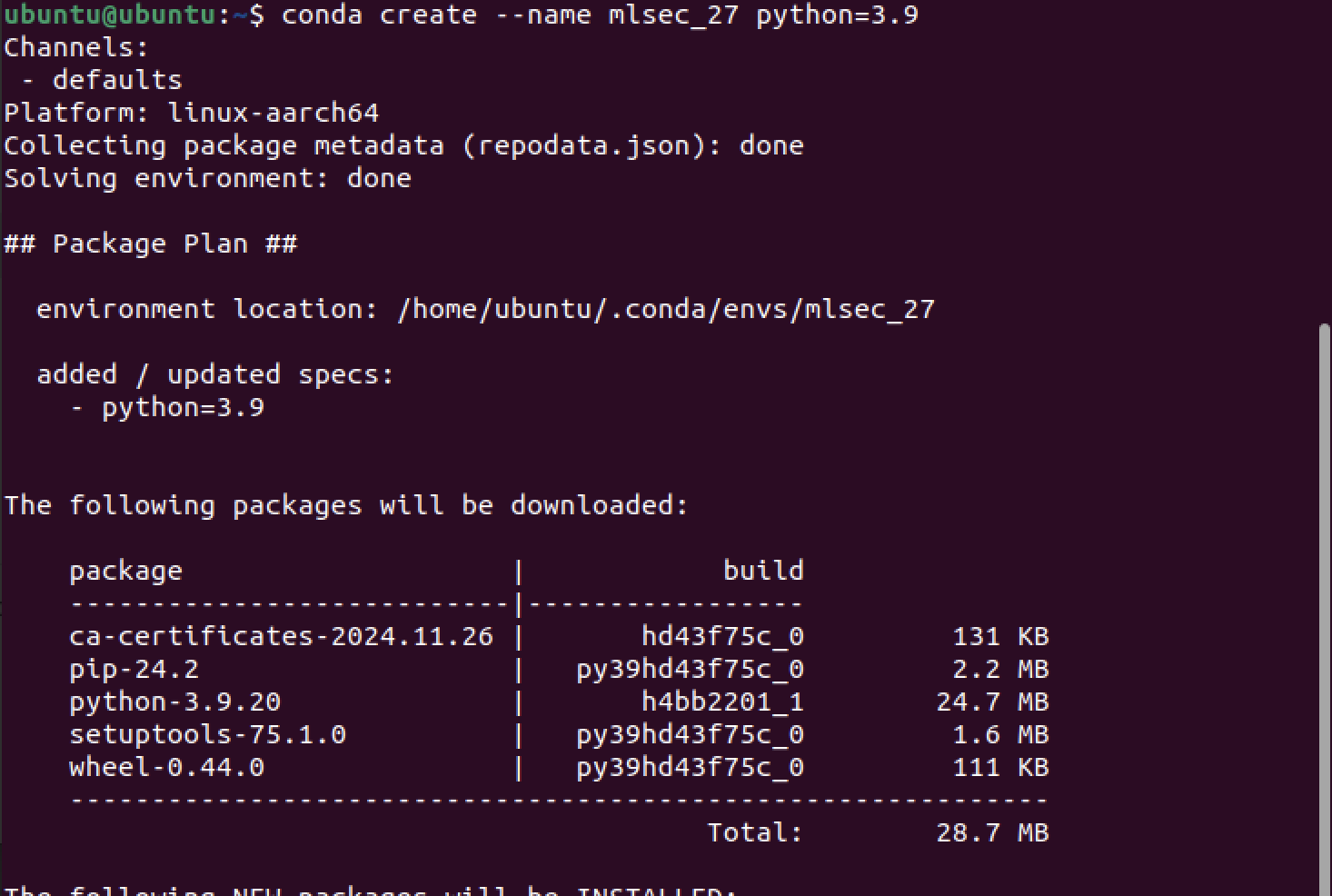
# To activate this environment, use
#
# $ conda activate mlsec_27
#
# To deactivate an active environment, use
#
# $ conda deactivate주피터(jupyter) 환경 설정
주피터는 코드, 공식, 시각화 기능을 포함한 문서를 지원하는 오픈소스 웹 애플리케이션
일반적으로는, 아나콘다 설치 시 기본적으로 설치된다고 하지만, 나는 안되었기에 따로 설치했다ㅠ
conda install -c conda-forge notebook~$ which python
home/ubuntu/.conda/envs/mlsec_27/bin/python
~$ pip install ipykernel
~$ sudo mkdir Downloads/anaconda/share/jupyter/kernels/mlsec_27
~$ sudo vi Downloads/anaconda/share/jupyter/kernels/mlsec_27/kernel.json
# kernel.json 파일 내용
{
"argv": ["/home/ubuntu/.conda/envs/mlsec_27/bin/python", "-m", "ipykernel", "-f", "{connection_file}"],
"display_name": "mlsec_27",
"language": "python"
}
# ESC -> :wq -> Enter
jupyter notebook --ip=0.0.0.0
# 나가고 싶을 땐, Ctrl + C
mlsec_27 가상환경 등록 성공!!!
