오늘의 목표 : 특징 분석.. 할 수 있을까..?
8장. PJ1_악성코드 탐지 모델(특징 공학)
8-2. 특징 분석
이번에는 특징들을 분석해 각 특징이 어떠한 분류 알고리즘에 가장 적합한지, 어떠한 특징이 더 좋은 성능을 보이는지 살펴보고, 최적의 특징 조합을 찾는 분석을 수행해보자.
일반 모델에 던져보기
추출한 특징을 평가하는 가장 기본적이고 간단한 방법은 알고리즘에 넣어보는 것이다.
실습에서는 80%를 학습에 사용하고, 20%를 테스트에 사용했다.
뉴럴 네트워크를 제외한 svm, randomforest, naivebayes은 전부 클래스 초기화, 학습, 예측으로 가능하다. 이미지 특징 분류를 위해 CNN 모델을 사용하려고 하는데, 이를 model.py와 동일한 방식으로 작성해야한다. 모든 코드들은 기본적으로 제공되는 모델 코드들을 사용하였고, 이미지는 개별 파일 형태로 존재하기 때문에, 하나씩 자료형으로 변환하고, 훈련 데이터와 테스트 데이터를 분류하는 부분이 작성되어있다.
#model.py
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.naive_bayes import GaussianNB
import tensorflow as tf
import numpy as np
import pandas as pd
class Classifiers():
def __init__(self, X, Y):
self.x_train, self.x_test, self.y_train, self.y_test = \
train_test_split(X, Y, test_size=0.2, random_state=0)
def do_svm(self):
clf = SVC()
clf.fit(self.x_train, self.y_train)
y_pred = clf.predict(self.x_test)
return accuracy_score(self.y_test, y_pred)
def do_randomforest(self, mode):
clf = RandomForestClassifier()
clf.fit(self.x_train, self.y_train)
if mode == 1:
return clf.feature_importances_
y_pred = clf.predict(self.x_test)
return accuracy_score(self.y_test, y_pred)
def do_naivebayes(self):
clf = GaussianNB()
clf.fit(self.x_train, self.y_train)
y_pred = clf.predict(self.x_test)
return accuracy_score(self.y_test, y_pred)
def do_dnn(self):
if "Series" in str(type(self.y_train)):
self.y_train = self.y_train.to_frame()
self.y_test = self.y_test.to_frame()
input_len = len(self.x_train.columns)
else:
self.y_train = self.y_train.reshape(len(self.y_train), 1)
self.y_test = self.y_test.reshape(len(self.y_test), 1)
input_len = np.size(self.x_train, 1)
learning_rate = 0.001
batch_size = 128
training_epochs = 15
keep_prob = 0.5
x_train = self.x_train
y_train = self.y_train
X = tf.placeholder(tf.float32, [None, input_len])
Y = tf.placeholder(tf.float32, [None, 1])
W1 = tf.Variable(tf.random_normal([input_len, 1024]), name='weight1')
b1 = tf.Variable(tf.truncated_normal([1024]), name='bias1')
L1 = tf.sigmoid(tf.matmul(X, W1) + b1)
W2 = tf.Variable(tf.random_normal([1024, 128]), name='weight4')
b2 = tf.Variable(tf.truncated_normal([128]), name='bias4')
L2 = tf.sigmoid(tf.matmul(L1, W2) + b2)
W3 = tf.Variable(tf.random_normal([128, 1]), name='weight5')
b3 = tf.Variable(tf.truncated_normal([1]), name='bias5')
output = tf.sigmoid(tf.add(tf.matmul(L2, W3), b3))
cost = -tf.reduce_mean(Y * tf.log(output) + (1 - Y) * tf.log(1 - output))
train = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)
predicted = tf.cast(output > 0.5, dtype=tf.float32)
accuracy = tf.reduce_mean(tf.cast(tf.equal(predicted, Y), dtype=tf.float32))
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for epoch in range(training_epochs):
avg_cost = 0
total_batch = int(len(x_train) / batch_size)
for i in range(total_batch-1):
batch_xs = x_train[i*batch_size:(i+1)*batch_size]
batch_ys = y_train[i*batch_size:(i+1)*batch_size]
_ , c =sess.run([train, cost], feed_dict={X: batch_xs, Y: batch_ys})
print ("Epoch :", epoch, "cost: ", c)
acc = sess.run(accuracy, feed_dict={X: self.x_test, Y: self.y_test})
return acc
def do_all(self):
rns = []
rns.append(self.do_svm())
rns.append(self.do_randomforest(0))
rns.append(self.do_naivebayes())
rns.append(self.do_dnn())
return rns# cnn_model.py
import tensorflow as tf
import numpy as np
import glob
from PIL import Image
from tensorflow.keras.utils import to_categorical
from tensorflow.keras import layers, models
class CNN_Model:
def load_images(self):
nb_classes = 2
# For Normal making images into readable data type
b = glob.glob('images/normal/*thumb.png')
total_len = len(b)
BEN_TRAIN = int(round(total_len * 0.8))
BEN_TEST = total_len - BEN_TRAIN
X_train_benign = np.empty((BEN_TRAIN, 28, 28, 1), dtype="float32")
y_train_benign = np.empty((BEN_TRAIN,), dtype="uint8")
X_test_benign = np.empty((BEN_TEST, 28, 28, 1), dtype="float32")
y_test_benign = np.empty((BEN_TEST,), dtype="uint8")
cnt = 0
for i in b:
im = Image.open(i).convert("L")
out = im.resize((28,28))
if cnt < BEN_TRAIN:
X_train_benign[cnt, :, :, 0] = out
y_train_benign[cnt] = 0 # normal
else:
X_test_benign[cnt - BEN_TRAIN, :, :, 0] = out
y_test_benign[cnt - BEN_TRAIN] = 0 # normal
cnt += 1
if cnt == (BEN_TRAIN + BEN_TEST):
break
# For malware making images into readable data type.
m = glob.glob('images/malware/*thumb.png')
total_len = len(m)
MAL_TRAIN = int(round(total_len * 0.8))
MAL_TEST = total_len - MAL_TRAIN
X_train_malware = np.empty((MAL_TRAIN, 28, 28, 1), dtype="float32")
y_train_malware = np.empty((MAL_TRAIN,), dtype="uint8")
X_test_malware = np.empty((MAL_TEST, 28, 28, 1), dtype="float32")
y_test_malware = np.empty((MAL_TEST,), dtype="uint8")
cnt = 0
for i in m:
im = Image.open(i).convert("L")
out = im.resize((28,28))
if cnt < MAL_TRAIN:
X_train_malware[cnt, :, :, 0] = out
y_train_malware[cnt] = 1 # malware
else:
X_test_malware[cnt - MAL_TRAIN, :, :, 0] = out
y_test_malware[cnt - MAL_TRAIN] = 1 # malware
cnt += 1
if cnt == (MAL_TRAIN + MAL_TEST):
break
# Split into training & testing dataset
X_train = np.empty(((BEN_TRAIN + MAL_TRAIN), 28, 28, 1), dtype="float32")
y_train = np.empty(((BEN_TRAIN + MAL_TRAIN),), dtype="uint8")
X_test = np.empty(((BEN_TEST + MAL_TEST), 28, 28, 1), dtype="float32")
y_test = np.empty(((BEN_TEST + MAL_TEST),), dtype="uint8")
y_train_benign = np.zeros(BEN_TRAIN,)
y_test_benign = np.zeros(BEN_TEST,)
X_train = np.concatenate((X_train_benign, X_train_malware), axis=0)
y_train = np.append(y_train_benign, y_train_malware)
X_test = np.concatenate((X_test_benign, X_test_malware), axis=0)
y_test = np.append(y_test_benign, y_test_malware)
X_train = X_train.astype("float32")
Y_train = to_categorical(y_train, nb_classes)
X_test = X_test.astype("float32")
Y_test = to_categorical(y_test, nb_classes)
self.x_train = X_train
self.x_test = X_test
self.y_train = Y_train
self.y_test = Y_test
def do_cnn(self):
learning_rate = 0.001
training_epochs = 30
batch_size = 100
keep_prob = tf.placeholder(tf.float32)
# input place holders
X = tf.placeholder(tf.float32, [None, 28, 28, 1])
Y = tf.placeholder(tf.float32, [None, 2])
W1 = tf.Variable(tf.random_normal([3, 3, 1, 32], stddev=0.01))
L1 = tf.nn.conv2d(X, W1, strides=[1, 1, 1, 1], padding='SAME')
L1 = tf.nn.relu(L1)
L1 = tf.nn.max_pool(L1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
L1 = tf.nn.dropout(L1, keep_prob=keep_prob)
W2 = tf.Variable(tf.random_normal([3, 3, 32, 64], stddev=0.01))
L2 = tf.nn.conv2d(L1, W2, strides=[1, 1, 1, 1], padding='SAME')
L2 = tf.nn.relu(L2)
L2 = tf.nn.max_pool(L2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
L2 = tf.nn.dropout(L2, keep_prob=keep_prob)
W3 = tf.Variable(tf.random_normal([3, 3, 64, 128], stddev=0.01))
L3 = tf.nn.conv2d(L2, W3, strides=[1, 1, 1, 1], padding='SAME')
L3 = tf.nn.relu(L3)
L3 = tf.nn.max_pool(L3, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
L3 = tf.nn.dropout(L3, keep_prob=keep_prob)
L3_flat = tf.reshape(L3, [-1, 128 * 4 * 4])
W4 = tf.get_variable("W4", shape=[128 * 4 * 4, 625], initializer=tf.contrib.layers.xavier_initializer())
b4 = tf.Variable(tf.random_normal([625]))
L4 = tf.nn.relu(tf.matmul(L3_flat, W4) + b4)
L4 = tf.nn.dropout(L4, keep_prob=keep_prob)
W5 = tf.get_variable("W5", shape=[625, 2], initializer=tf.contrib.layers.xavier_initializer())
b5 = tf.Variable(tf.random_normal([2]))
logits = tf.matmul(L4, W5) + b5
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=logits, labels=Y))
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
print('Learning started. It takes some time.')
for epoch in range(training_epochs):
avg_cost = 0
total_batch = int(len(self.y_train) / batch_size)
for i in range(total_batch):
batch_xs = self.x_train[i * batch_size:(i + 1) * batch_size]
batch_ys = self.y_train[i * batch_size:(i + 1) * batch_size]
feed_dict = {X: batch_xs, Y: batch_ys, keep_prob: 0.7}
c, _ = sess.run([cost, optimizer], feed_dict=feed_dict)
avg_cost += c / total_batch
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.9f}'.format(avg_cost))
print('Learning Finished!')
# Test model and check accuracy
correct_prediction = tf.equal(tf.argmax(logits, 1), tf.argmax(Y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
acc = sess.run(accuracy, feed_dict={X: self.x_test, Y: self.y_test, keep_prob: 1})
return acc정말 늘 느끼는 것인데, 프로젝트가 몇 년전이다 보니, 그동안 바뀐 것들이 너무 많아서 하나하나 오래된 것들을 수정하는 게 너무 번거롭다.. 그래도 해야겠지.. 어쩌겠어..
쥬피터 노트북을 통하여 코드를 하나하나 실행해보았는데..

그동안 모은 특징 데이터들을 로드하는 작업. 여기까지는 무난했다.

여기서부터 문제다.. Pandas 내장 기능을 사용하여 누락된 값들을 제거하는 코드인데.. 무려 14947..ㅎ 값이 누락이 되어서.. (130,72)개가 남았다. 이게 맞나???? 진짜로? 이게 맞아? 데이터가 너무 부족해서 당황을 해버렸다.
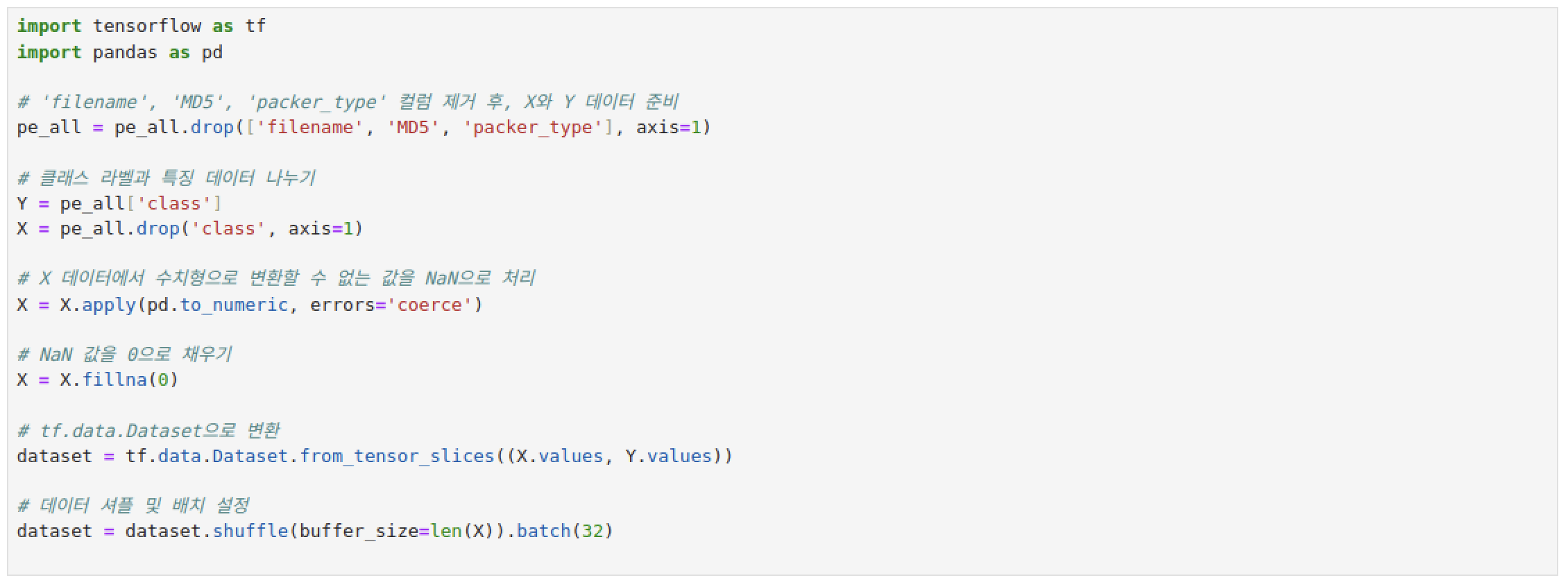
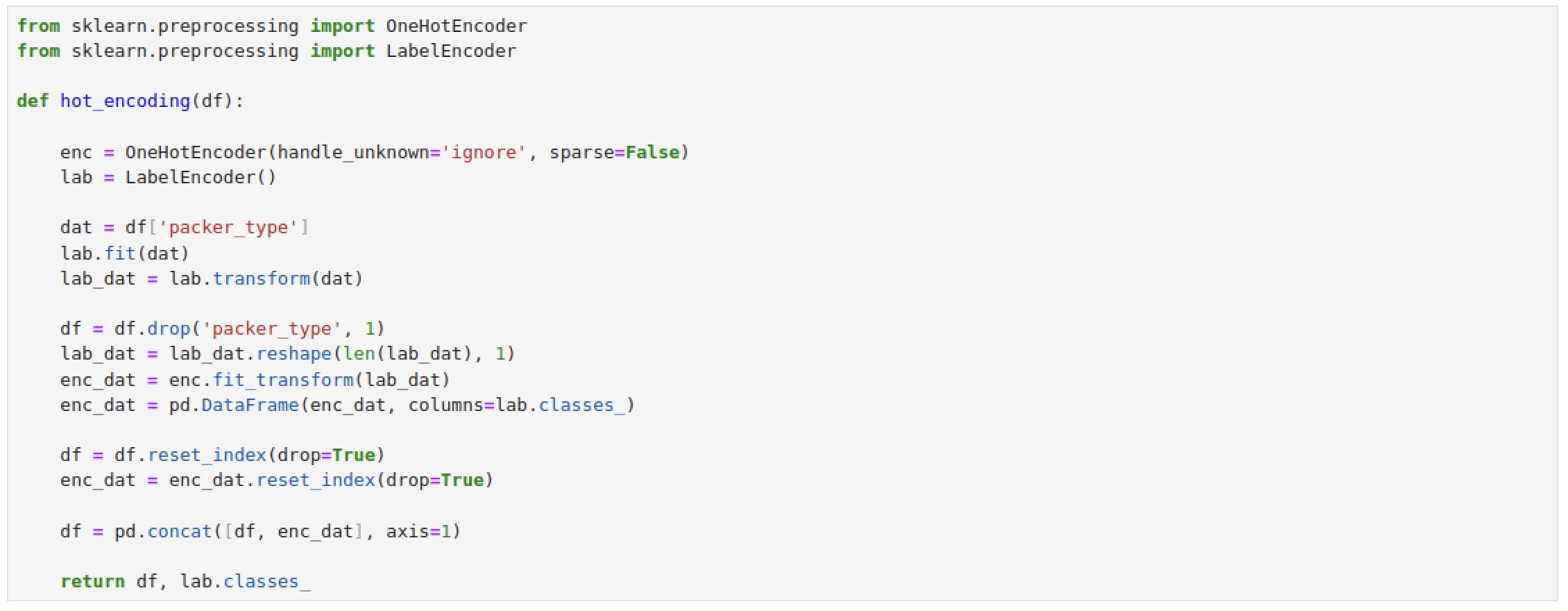
열심히 내 방식대로 수정에수정에수정 작업을 한 코드들.
핫 인코딩까지 했는데.. 시험기간 이슈로 이 이상을 하기는 힘들 것 같아서 멈춘다..
갈길이 너무 멀어..ㅠㅠㅠㅠ
