오늘의 목표 : 특징 추출 완료하기.. 프로젝트 기간 내에 완성할 수 있을까..?
8장. PJ1_악성코드 탐지 모델(특징 공학)
8-1. 특징 추출
프로젝트에서는 윈도우 32비트 실행 파일 형식(PE)에서 추출 가능한 세 가지 정적 특징에 초점을 맞춘다.
PE 헤더
PE 헤더 특징은 ClaMP라는 오픈소스 프로젝트에서 제공하는 스크립트를 이용했다. ClaMP 제작자는 PE파일에서 Raw 특징 60개, Derived 특징 9개를 뽑아냈다.
- Raw : PE 헤더의 필드 값을 단순히 파싱한 결과
- Derived : 필드 값을 한 번 더 가공한 특징
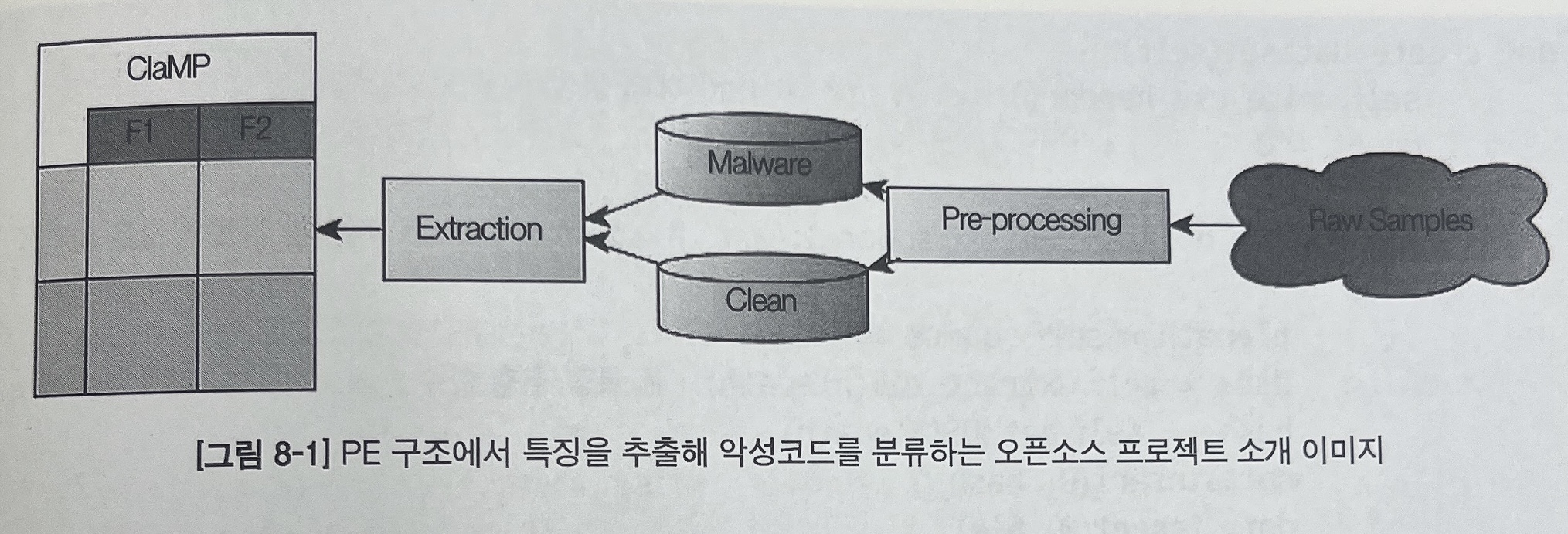
작성된 PE 특징 추출 코드는 크게 csv 헤더 이름 정의 부분, 헤더 정보 추출 부분, 추출한 특징 정보를 csv 파일에 기록하는 부분으로 구분된다.
main()는 특징을 추출할 파일이 위치한 경로, 결과를 저장할 csv 파일 이름, 카테고리 값을 입력 받아 PE_features 클래스를 생성하고, create_dataset 함수를 호출한다.
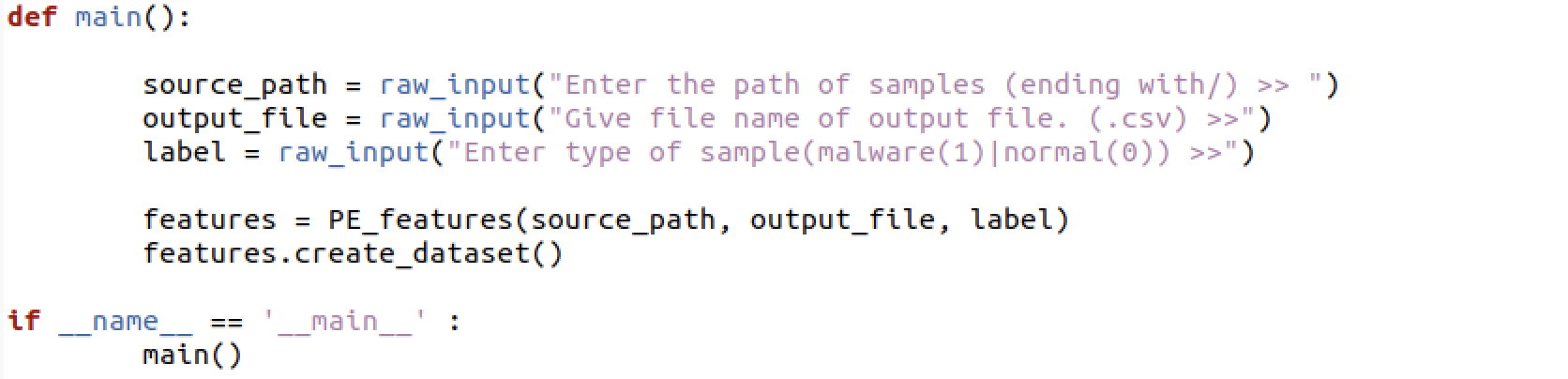
create_dataset()는 csv파일을 새롭게 생성하고, 헤더 이름을 기록한 후 메인 함수에서 지정한 경로에 있는 파일을 하나씩 가져와 특징을 추출한 후 그 결과를 csv 파일에 기록한다.
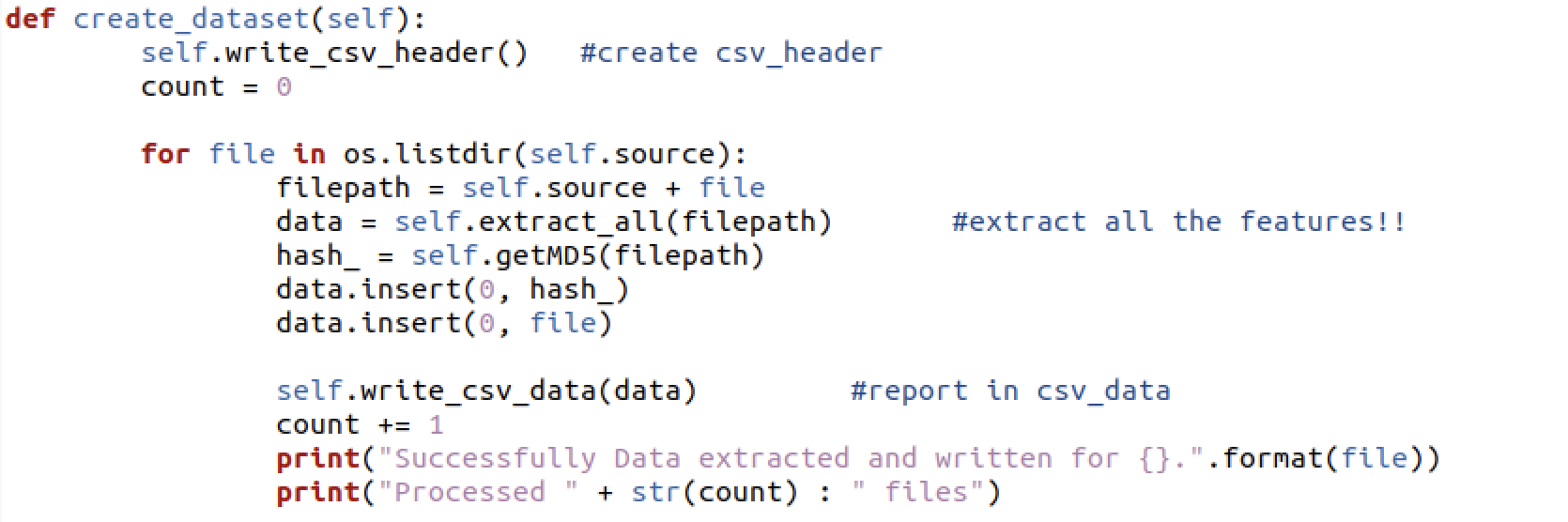
extract_all()은 파일에서 특징을 뽑아내는 역할을 담당하고 있다. PE 헤더 파싱으로 뽑아낼 수 있는 Raw 특징을 추출한다(extract_dos_header, extract_file_header, extract_optional_header) 그 이후에 실행되는 num_ss_nss는 PE 헤더 요소 값들을 한 번 더 해석해 의미있는 정보를 추출하는 Derived 특징 추출 부분이다.
- get_count_suspicious_sections : 섹션 이름을 검사 (정상/악성에서 많이 보이는 이름을 확인)
- check_packer : 파일에 적용된 패커 알고리즘을 검사 (yara 룰셋 사용)
- get_text_data_entropy : 코드와 데이터 섹션의 엔트로피 값 계산
- get_file_entropy : 파일 전체의 엔트로피 값 계산
- get_fileinfo : 파일 버전, 제품 버전, 제품 이름, 회사 이름을 조회
PE 헤더의 섹션은 실제 프로그램 데이터가 들어가는 부분으로, 각 섹션은 고유의 이름과 영역을 가지고 있다. ClaMP의 저자는 benign_sections 목록을 정의한 후 프로그램 내의 모든 섹션의 이름 중 이 목록과 일치하는 이름이 있으면 개수를 더하는 방식으로 특징을 추출하였다.
benign_sections = set(['.text', '.data', '.rdata', '.idata', '.edata', '.rsrc', '.bss', '.crt', '.tls'])정보의 불확실성 정도를 측정하는 것으로, 데이터 안에 담긴 정보의 분포에 따라 값이 달라지는 정보 엔트로피라고 하는데, 코드 섹션, 데이터 섹션, 파일 전체에 대한 엔트로피 값을 특징으로 사용하였다.
check_packer()은 대상 프로그램에 적용된 패커를 식별하는 함수이다. 패커는 패킹을 수행하는 도구 및 방법을 의미하는 것으로, 여기서 패킹이란 실행 파일을 압축하는 기술을 의미한다.
rules라는 데이터 안에 담긴 정보와 파일을 비교하여 패커를 찾아낸다.

yara는 악성코드의 시그니처를 이용하여 악성코드의 종류를 식별하고 분류하는 목적으로 사용되는 오픈소스 도구이다.
머신러닝에서 사용하는 특징이라고 해서 기존에 사용하지 않았던 혁신적인 정보를 다루는 것이 아니라 추출한 정보를 처리하는 방식에서 차이가 있을 뿐이기 때문에 기존에 사용하던 yara 룰셋을 보조 도구로 하여 충분히 머신러닝에 사용할 수 있다.
코드를 실행시키기 위해서는
# pip install pefile
# pip install yara
# sudo find / -name libyara.so
# sudo cp /usr/lib/aarch64-linux-gnu/libyara.so.8* /home/ubuntu/anaconda3/envs/mlsec_27/lib/를 해야한다. 왜냐! 코드에서 yara를 사용하고 있으니까!
아니 근데 계속 yara에서 에러가 나서,, 이러지도 저러지도 못하는 상황..
cd /home/ubuntu/yara
./bootstrap.sh
./configure
make
sudo make install
export LD_LIBRARY_PATH=/home/ubuntu/yara/.libs:$LD_LIBRARY_PATH
pip uninstall yara
pip install yara-python
sudo find / -name "libyara.so"
export LD_LIBRARY_PATH=/usr/local/lib:$LD_LIBRARY_PATH진심으로 위의 코드만 10번 넘게 계속 시도하다가 문득, 호완성이 맞지 않아서 이런거 아닌가? 라는 생각이 들어서, 아나콘다 가상환경을 삭제하고 다시 설치했다.
conda deactivate
conda remove --name mlsec_27 --all
conda create --name mlsec_27 python=3.8
conda activate mlsec_27
pip install yara-python그렇게 고생을 한 시간들이 아깝게..
바로 성공을 해버렸다.
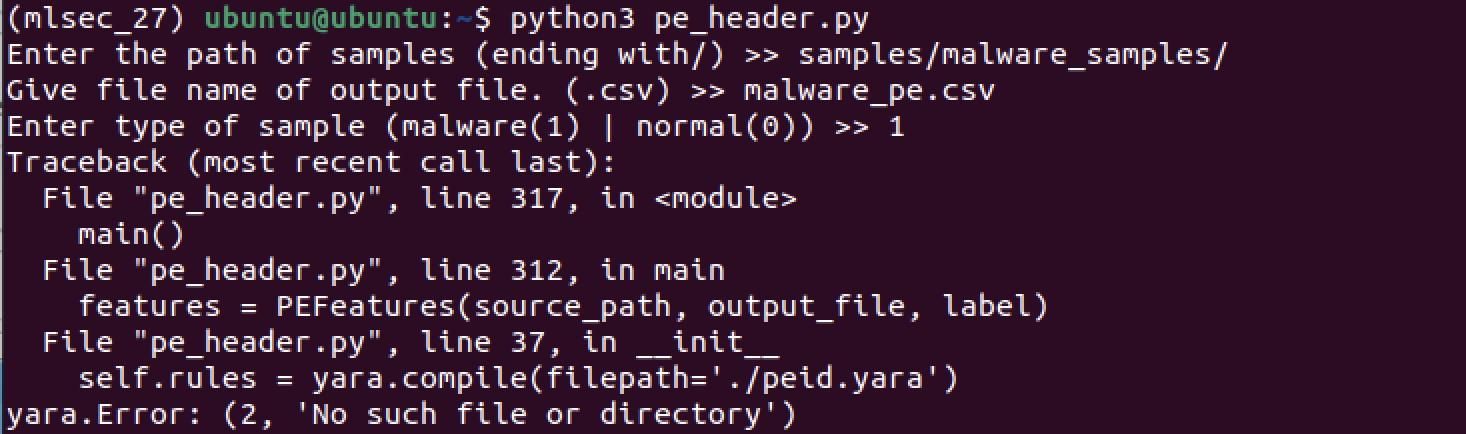
근데, peid.yara 파일이 없어서 실패해서,,
이건 챗지피티한테 코드 주고 대신 작성해달라고 부탁했다.
rule UPX
{
meta:
description = "Detects UPX packed files"
strings:
$upx1 = "UPX!" ascii
$upx2 = "UPX0" ascii
$upx3 = "UPX1" ascii
$upx4 = "UPX2" ascii
condition:
any of ($upx*)
}
rule ASPack
{
meta:
description = "Detects ASPack packed files"
strings:
$aspack1 = ".aspack" ascii
$aspack2 = "ASPack protection" ascii
condition:
any of ($aspack*)
}
rule Themida
{
meta:
description = "Detects Themida packed files"
strings:
$themida1 = "Themida" ascii
$themida2 = "WinLicense" ascii
condition:
any of ($themida*)
}
rule FSG
{
meta:
description = "Detects FSG packed files"
strings:
$fsg1 = "FSG!" ascii
$fsg2 = "FSG packer" ascii
condition:
any of ($fsg*)
}
rule PECompact
{
meta:
description = "Detects PECompact packed files"
strings:
$pecompact1 = "PEC2" ascii
$pecompact2 = "PECompact2" ascii
condition:
any of ($pecompact*)
}
rule Armadillo
{
meta:
description = "Detects Armadillo packed files"
strings:
$armadillo1 = "Armadillo" ascii
$armadillo2 = "WinLic" ascii
condition:
any of ($armadillo*)
}
rule VMProtect
{
meta:
description = "Detects VMProtect packed files"
strings:
$vmprotect1 = "VMProtect" ascii
$vmprotect2 = "VMProtectVirtualization" ascii
condition:
any of ($vmprotect*)
}
rule GenericPacker
{
meta:
description = "Detects generic packing patterns"
strings:
$packer1 = "packed" ascii
$packer2 = "compressed" ascii
$packer3 = ".pack" ascii
condition:
any of ($packer*)
}
이렇게 작성이 되었고,,
malware.csv

첫 번째 에러는 빈 파일이 있을 때, 그냥 바로 종료가 되어버려서, 파일이 비어있으면 넘기는 코드를 작성하였다.
두 번째 에러는 decode()를 사용하여 바이트를 문자열로 바꿔주는 코드를 작성하였고,
여러 차례의 수정을 거쳐서 총 503개의 파일을 csv로 만들었다.
하지만 뭔가.. 군데군데 비어있는 곳들이 많아서 약간 의심스럽기는 하다.
normal.csv

오류들은 이미 malware.csv에서 수정하였기 때문에, normal.csv에서는 딱히 에러가 뜨지 않았다.
결과화면이다.
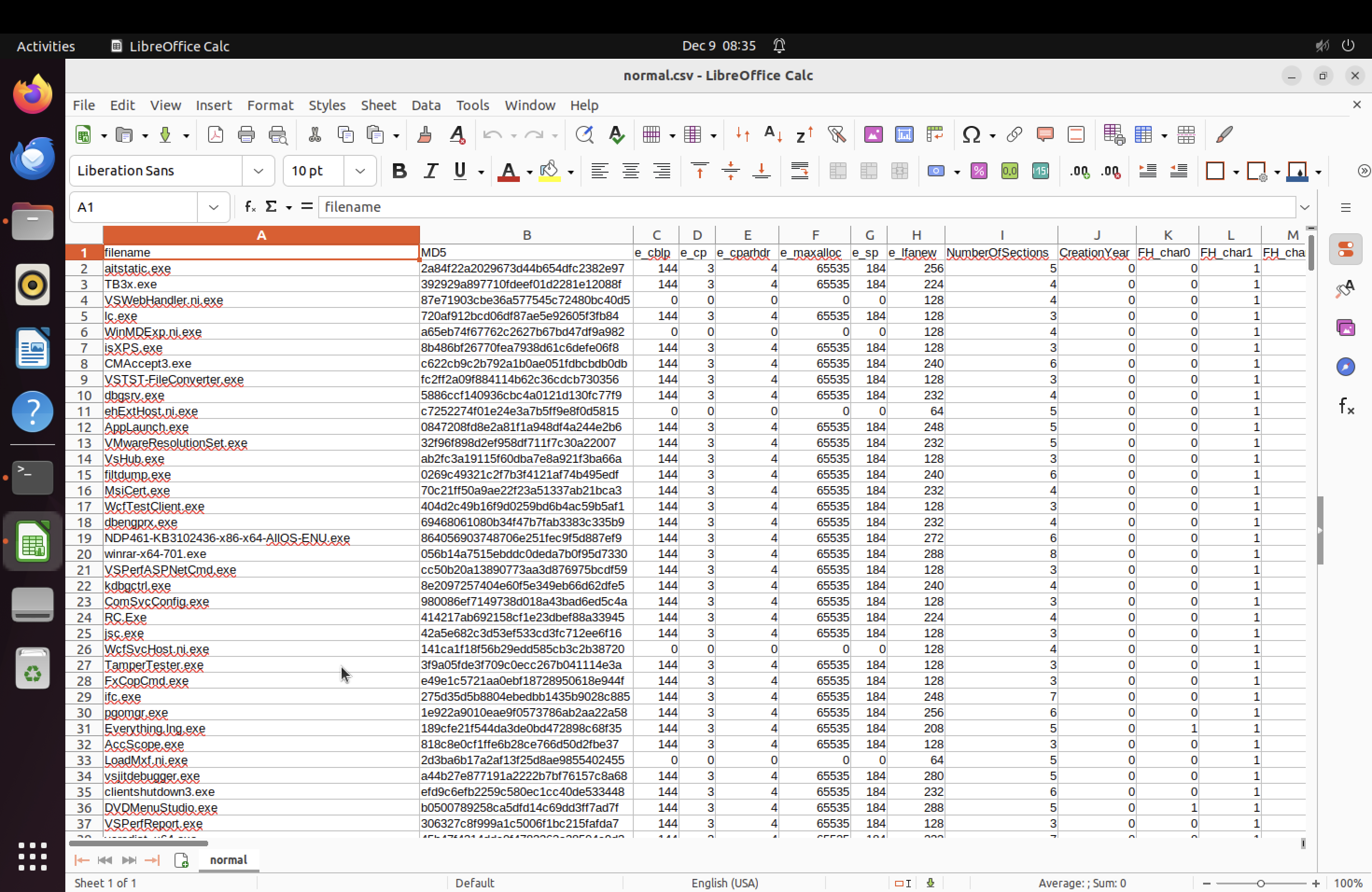
(드디어!!!!! 넘어갈 수 있어!!! 내가 진짜 오늘 하루를 다 이거에만 쏟아부었다;;;
PE헤더만 하고 싶은데, 그래도 특징 추출까지는 하고 싶어서 계속 하는중)
정적 코드 패턴
모든 프로그램은 헤더와 데이터 영역을 가지고 있다. 위에서 헤더 부분의 특징을 추출했으니, 이번엔 데이터 역역에 있는 프로그램의 실제 코드 부분에서 특징을 추출한다.
코드 섹션을 찾는 방법은 3가지가 있는데,
- 이름이 .text인 섹션
- 정확하지 않다
- 모든 프로그램에 적용하기 어렵다 (.text 섹션이 없는 경우도 있다.)
- 프로그램 진입점(AddressOfEntryPoint)이 가리키는 섹션
- PE헤더의 Optional Header 필드 중 하나를 이용한다.
- 프로그램에서 가장 먼저 실행되는 코드의 위치를 담고 있다.
- 패킹된 프로그램이 경우, 압축 풀기가 가장 먼저 실행되기 때문에 적용 불가능하다.
- 여러 개의 코드 섹션을 가지는 경우도 추출할 수 없다.
- 속성(Characteristics)에 CNT_CODE와 MEM_EXECUTE 플래그가 활성화된 섹션
- 모든 섹션은 나름의 속성을 가지고 있다.
- 일반적으로 코드 섹션이 활성화 되어있는 두 플래그를 통해 섹션을 찾으면 정보 누락 없이 모두 추출할 수 있다.
우리가 추출하고 싶은 것은 코드 섹션 안에 있는 '실제 코드' 부분이며, 이는 CPU가 이해할 수 있는 어셈블리 언어를 의미한다. 바이트 코드를 어셈블리 코드로 해석해주는 디스어셈블(disassemble) 과정을 거쳐야만 어셈블리 코드를 확인할 수 있다.
마지막으로, 어셈블리 코드 문자열의 의미를 머신러닝 모델이 이해할 수 있도록 변환 과정을 거쳐야 한다. 이번 프로젝트에서는 N-gram 분석을 이용하여 어셈블리 코드의 특징을 추출할 것이다.
N-gram 분석은 문자열에서 N개의 연속된 요소를 추출하는 방법으로 언어 및 텍스트 분석 분야에서 많이 활용되는 방법이다. 띄어쓰기를 기준으로 하며, gram 앞의 숫자가 늘어나면 그만큼 한 번에 많은 단어를 포함한 고유의 패턴을 추출할 수 있다. 숫자 N은 분석을 적용하는 분야와 목적에 따라 최적의 개수가 달라진다.

프로젝트에서는 전체 데이터셋을 대상으로 고유한 4-gram 개수를 뽑아낸 뒤 그중 상위 빈도를 가지는 패턴을 특징으로 사용해 특징이 가지는 정보의 양을 최대화한다.
충분히 데이터가 많아야 한다는 전제가 있지만, 이 방식을 사용하면 개별 파일 내에서 비중을 차지하는 명령어뿐만 아니라, 전체 샘플 데이터에서 공통적으로 중요하게 사용되는 명령어 패턴도 함께 구할 수 있다.
- 악성코드와 정상 프로그램 저체를 대상으로 4-gram 패턴 추출
- 패턴 개수 상위 100개의 특징만 선택 : 패턴 이름만 남기고 개수는 제거
- 개별 파일을 대상으로 100개 특징에 해당하는 패턴 개수를 실제 특징 값으로 사용
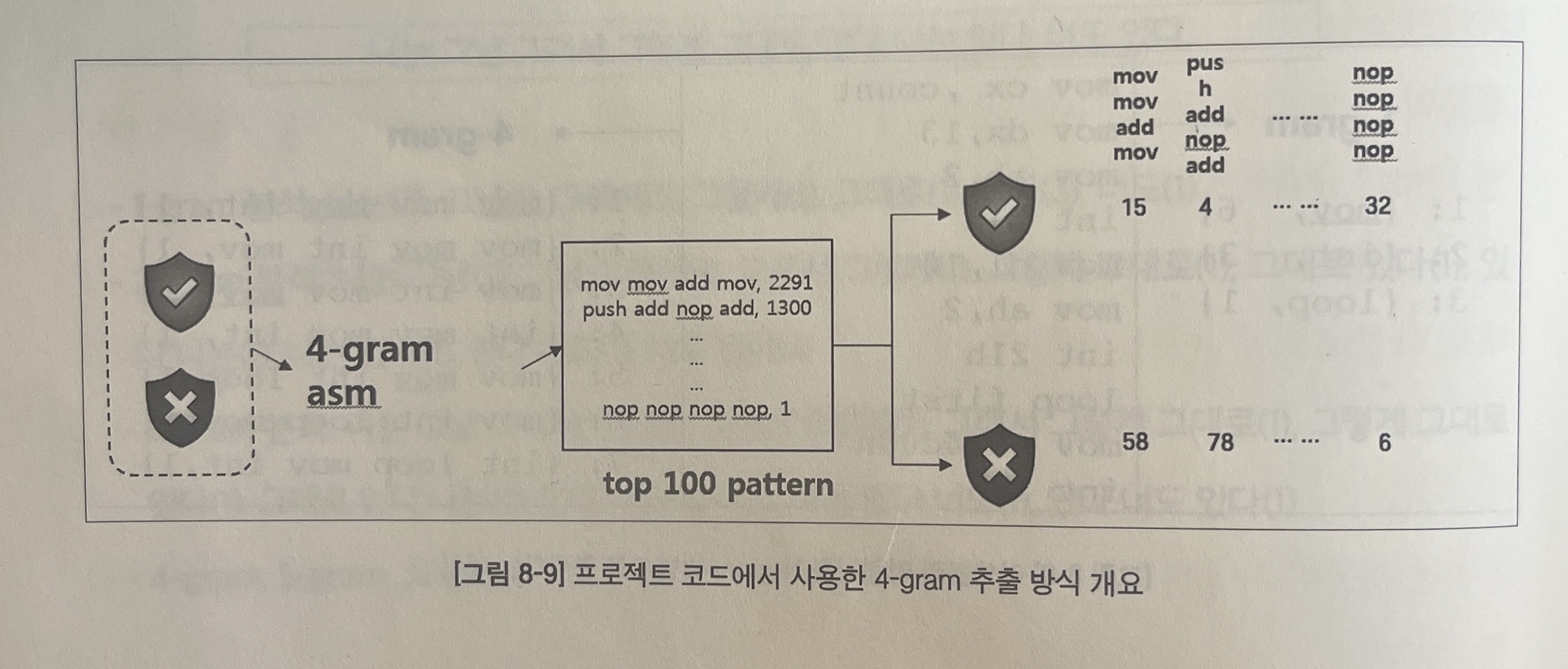
메인 함수는 크게 3부분으로 나뉘어 진다.
1. 전체 정상 프로그램과 악성코드 파일에서 고유한 4-gram을 추출하는 부분
# From here - Step1 : Extract own 4-gram pattern from malware/normal files
for file in os.listdir(mal_path):
i += 1
print ("%d file processed (%s)," % (i, file))
file = mal_path + file
byte_code = ef.get_opcodes(0, file)
if not byte_code:
continue
grams = ef.n_grams(4, byte_code, 1)
print ("%d patterns extracted" % (len(grams)))
print ("- Malware Completed")
for file in os.listdir(nor_path):
i += 1
print ("%d file processed (%s)," % (i, file))
file = nor_path + file
byte_code = ef.get_opcodes(0, file)
if not byte_code:
continue
grams = ef.n_grams(4, byte_code, 1)
print ("%d patterns extracted" % (len(grams)))
print ("- Normal Completed")2. 패턴 빈도 상위 100개의 패턴을 추출해 특징으로 만드는 부분
# From here - Step2 : By extracting Top 100 patterns, Make those into Features
print ("[*] Total length of 4-gram list :", len(grams))
sorted_x = sorted(grams.items(), key=operator.itemgetter(1), reverse=True)
print ("[*] Using %s grams as features" % (num_of_features))
features = sorted_x[0:num_of_features]
headers = list(chain.from_iterable(zip(*features)))[0:num_of_features]
ef.write_csv_header(headers)
print ("#" * 80)3. 각 파일에서 100개 패턴에 해당하는 빈도를 뽑아 csv에 기록하는 부분
# From Here - Step3 : Selecting the patterns (which is Top 100) in each file, record the frequency in csv
i = 0
for file in os.listdir(mal_path):
i += 1
print ("%d file processed (%s)," % (i, file))
filepath = mal_path + file
byte_code = ef.get_opcodes(0, filepath)
if not byte_code:
continue
grams = ef.n_grams(4, byte_code, 0)
gram_count = ef.get_ngram_count(headers, grams, 1)
hash_ = ef.getMD5(filepath)
all_data = [file, hash_]
all_data.extend(gram_count)
ef.write_csv_data(all_data)
for file in os.listdir(nor_path):
i += 1
print ("%d file processed (%s)," % (i, file))
filepath = nor_path + file
byte_code = ef.get_opcodes(0, filepath)
if not byte_code:
continue
grams = ef.n_grams(4, byte_code, 0)
gram_count = ef.get_ngram_count(headers, grams, 0)
hash_ = ef.getMD5(filepath)
all_data = [file, hash_]
all_data.extend(gram_count)
ef.write_csv_data(all_data)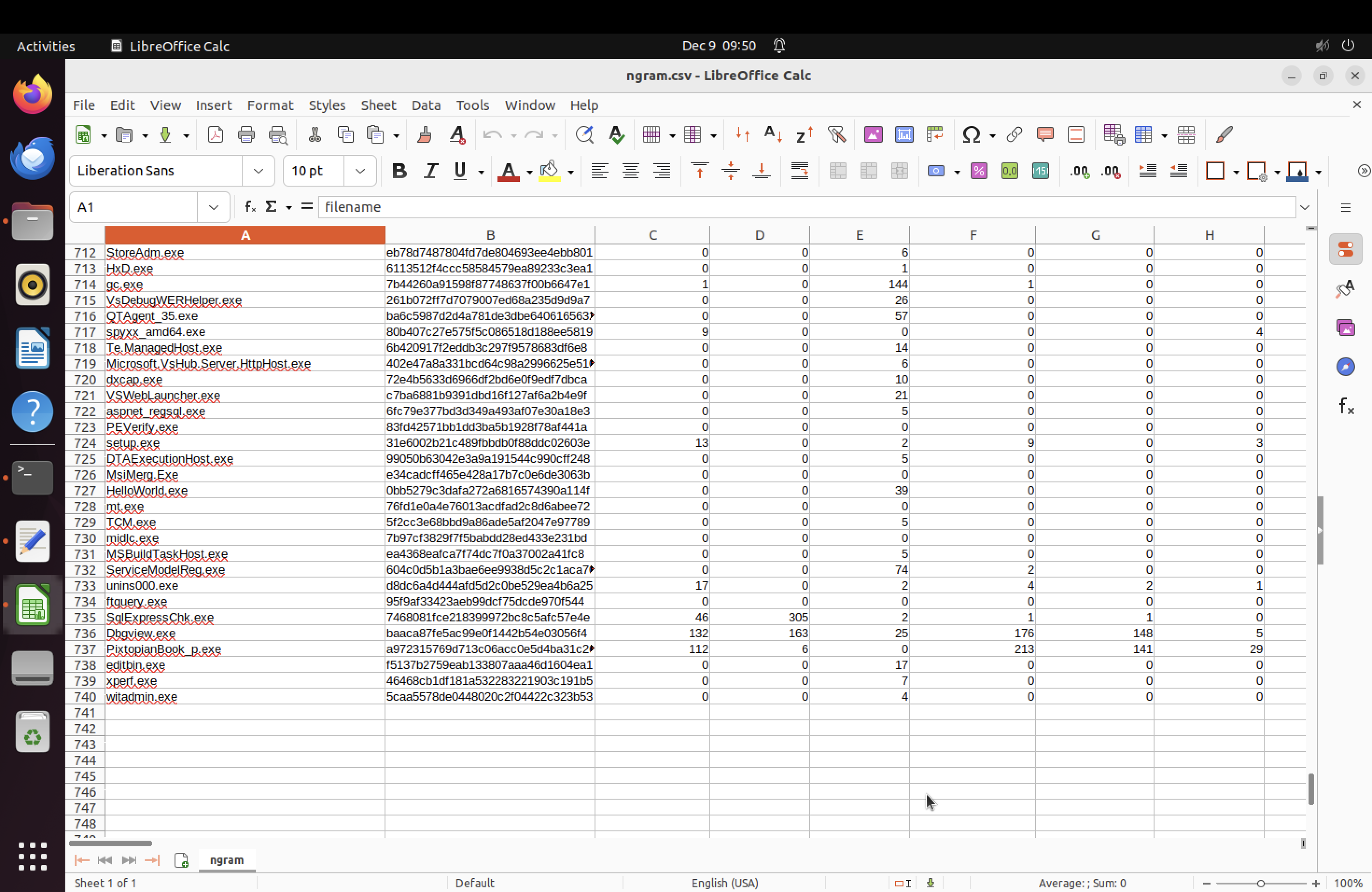
생성된 ngram.csv 이다. 샘플들이 사라지고 없어져서 740개 정도 남은 것을 볼 수 있다..ㅠ
바이너리 이미지
마지막으로!!! 프로그램 파일(바이너리)을 통째로 이미지로 변환해 특징으로 사용해본다.
이미지는 사람이 인지하는 형식일 뿐, 컴퓨터의 입장에서 이미지는 의미 없는 연속된 바이트의 모음일 뿐이다. 하지만 CNN을 사용하면 이미지에 대한 이해 없이도 의미 있는 많은 특징을 자동으로 추출할 수 있다.
파일 전체를 이미지화하는 방식은 다음과 같은 문제점을 내포하고 있다.
- 프로그램 파일의 크기는 다양하다.
- 모델은 동일한 개수의 입력 값을 필요로 한다.
- 서로 다른 크기의 이미지를 고정된 크기로 변경하는 방법은 픽셀을 조정하는 방법밖에 없다.
- 이렇게 처리할 경우 동일한 잣대로 이미지에서 특징을 뽑아낼 수 없다.
- 패킹이 적용된 경우 동일한 프로그램도 완전히 다른 모양을 가질 수 있다.
- 충분히 많은 샘플을 확보한다면 영향력이 그리 크지는 않겠지만, 충분히 정확도를 떨어뜨리는 요인으로 작용할 수 있다.
- 결과 해석이 불가능하다.
- 모델 성능을 올리는 방법이 새로운 데이터를 추가하는 것밖에 없는 상황이 발생할 수 있다. ( 시그니처 기반 형식의 한계점을 그대로 가지게 된다)
바이너리 이미지 프로그램의 경우 책에서 제공하는 코드를 그대로 가지고왔다.
import numpy as np
import os
import array
import imageio
from PIL import Image
class IMAGE_feature():
def __init__(self, in_path, out_path):
self.in_path = in_path
self.out_path = out_path
def get_image(self, path, file):
filename = path + file
try:
f = open(filename, 'rb')
ln = os.path.getsize(filename)
if ln == 0:
print(f"[ERROR] File {file} is empty. Skipping.")
return
width = int(ln**0.5)
if width == 0: # if file = 0 skip!!
print(f"[ERROR] Invalid width for file {file}. Skipping.")
return
rem = ln % width
a = array.array("B")
a.fromfile(f, ln - rem)
f.close()
g = np.reshape(a, (int(len(a) / width), width))
g = np.uint8(g)
fpng = self.out_path + file + ".png"
imageio.imwrite(fpng, g)
outfile = self.out_path + file + "_thumb.png"
print(outfile)
size = 256, 256
if fpng != outfile:
im = Image.open(fpng)
im.thumbnail(size, Image.Resampling.LANCZOS)
im.save(outfile, "PNG")
except Exception as e:
print(f"[ERROR] An error occurred while processing file {file}: {str(e)}")
def get_all(self):
path = self.in_path
for file in os.listdir(path):
self.get_image(path, file)
def main():
mal_path = 'samples/malware_samples/'
nor_path = 'samples/normal_samples/'
mal_out_path = 'images/malware/'
nor_out_path = 'images/normal/'
im1 = IMAGE_feature(mal_path, mal_out_path)
im1.get_all()
im2 = IMAGE_feature(nor_path, nor_out_path)
im2.get_all()
if __name__ == '__main__':
main()몇 년전에 나온 책이라, 그동안 모듈이나 바뀐 것들이 많아 그 부분들만 수정했다.
발전이 정말 빠른 것 같다. malware는 파일이 빈 것들이 많아서 skip이 꽤나 많은데, normal은 거의 대부분이 다 이미지화된 것 같다. 이러다가 그냥 malware 샘플들 다 없어지는 거 아니야?
코드가 이렇게 쫘라라락 뜨고

이미지 파일에 이러한 형식으로 저장이 되는 것을 볼 수 있다.
진짜.. 끝이다. 어제가 가장 힘들었다고 생각했는데, 오늘이 가장 힘들었다. 날마다 갱신되네.. 내일은 더 힘드려나ㅠㅠ 제발 그러지 않기를.. 그래도 이렇게 끝까지 남아서 다 끝내니까 뿌듯하다. 내일의 다연이 화이팅! ㅎㅎ
