
You Only Look Once : Unified, Real-Time Object Detection
1. Introduction
Current detection systems have complex pipelines = slow & hard to optimize
: Each individual component must be trained separately
YOLO reframe object detection as a single regression problem, straight from image pixels to bounding box coordinates and class probabilities.
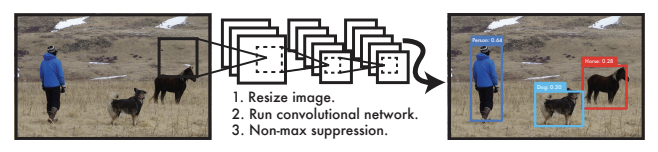
< YOLO benefit >
1. YOLO is extremely fast : Don't need a complex pipline ( frame detection as a regression problem )
→ Can process streaming video in real-time
2. YOLO reasons globally about the image → Sees the entire image
3. YOLO learns generalizable representations of objects → Less likely to break down
< YOLO tradeoff >
- YOLO struggles to precisely localize some objects, especially small ones
Sliding Window
배열이나 문자열 같은 연속된 데이터에서 고정된 크기의 윈도우(창)를 왼쪽에서 오른쪽으로 조금씩 움직이며 부분 데이터를 확인하는 방식 → 이전 윈도우 결과를 활용해 빠른 처리 가능
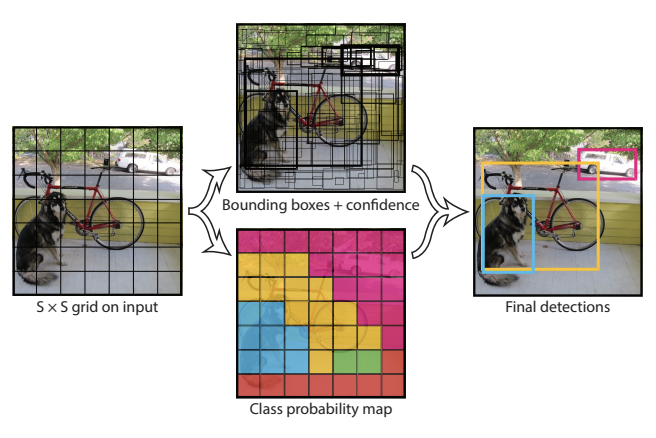
2. Unified Detection
Unify the separate components of object detection into a single neural network. Network uses features from the entire box to predict each bounding box. It also predicts all bounding boxes acorss all classes for an image simultaneously.
= Network reasons globally about the full image and all the objects in the image
: The YOLO design enables end-to-end training and real-time speeds while maintaining high average precision
Confidence score
Reflect how confident the model is that the box contains an object and also how accurate it thinks the box is that it predicts
- *
- : 확률
IOU (Intersection over Union)
: 두 개의 경계상자 (Bounding Box)가 겹치는 정도를 계산한 지표
- Intersection (교집합 면적) / Union (합집합 면적)
- Each bounding box consists of 5 predictions : confidence
- represent the center of the box relative to the bounds of the grid cell
- predicted relative to the whole image
- confidence represents the IOU between the predicted box & any ground truth box
- (conditional class probability) =
- Conditioned on the grid cell containing an object.
- Only predict one set of class probabilities per grid cell
Multiply the conditional class probabilities and the individual box confidence predictions,
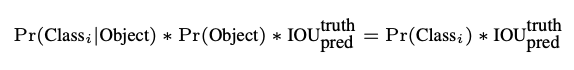
= class-specific confidence scores for each box
2-1. Network Design
We implement this model as a convolutional neural network.
The initial convolutional layers of the network extract features from the image while the fully connected layers predict the output probabilities and coordinates.
Network have
- 24 convolutional layers followed by 2 fully connected layers
Also trained fast YOLO designed to push the boudaries of fast object detection. Fast YOLO uses a neural network with fewer convolutional layers(9 instead of 24) and fewer filters in those layers.
2-2. Training
Pretrained convolutional layers on the ImageNet. For pretraining we used the first 20 convolutional layers followed by a average-pooling layer and a fully connected layer.
Then convert the model to perform prediction. Adding both convolutional and connected layers to pretrained networks can improve performance. So, added four convolutional layers and two fully connected layers with randomly initialized weights
Final later predicts both class probabilites and bounding box coordinates. We use a linear activation function for the final layer and all other layers use the following leaky rectified linear activation
< Leaky ReLU (leaky rectified linear activation) >
양수 일 때는 일반 ReLU처럼 동작, 음수 일 때는 작은 gradient가 남아 동작
sum-squared error
모델의 오차가 얼마나 큰지 측정하는 방법
We use sum-squared error because it is easy to optimize, however it does not perfectly align with our goal of maximizing average precision.
In every image many grid cells do not contain any object
- Increase the loss from bounding box coordinate prediction
- Decrease the loss form confidence predictions for boxes that don't contain objects
Must reflect Small deviations in large boxes matter less than in small boxes
- Predict the square root of the bounding box width and height istead of the width and heighr directly
Only want one bounding box predictor to be reponsible for each project
- Assign one predictor to be responsible for predicting an object based on which prediction has the highest current IOU with the ground truth
→ Each predictor gets better at predicting certain sizes, aspect ratios, or classes of object, improving overall recall
During training, we optimize the multi-part loss function
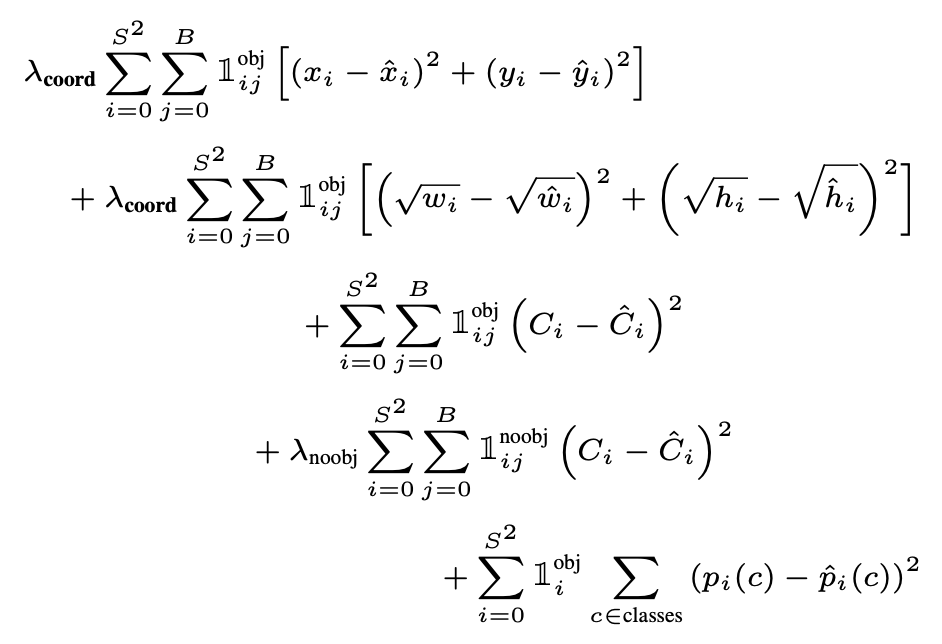
Loss function penalize
- Only penalizes classification error if an object is present in that grid cell
- Only penalizes bounding box coordinate error if that predictor is "responsible" for the ground truth box
To avoid overfitting we use dropout and extensive data augmentation.
2-3. Inference
Predicting detections for a test image only requires on network evaluation
The grid design enforces spatial diversity in the bounding box predictions. However, some large objects or objects near the border of multiple cells can be well localized by multiple cells. Non-maximal suppresion can be used to fix these multiple detections.
2-4. Limitations of YOLO
YOLO imposes strong spatial constraints on bounding box predictions since each grid cell only predicts two boxes and can only have one class.
This spatial constraint limits the number of nearby objects that our model can predict
The Model struggles to generalize to objects in new or unusual aspect ratios or configurations.
Loss function treats errors the same in small bounding boxes versus large bounding boxes. Our main source of error is incorrect localizations.
3. Comparison to Other Detection Systems
Detection pipeline starts by extracting a set of robust features from input images. Then, classifiers or localizers are used to identify objects in the feature space.
Comparisons with other detection systems..
Deformable parts models
: 객체 탐지 모델, 물체를 여러 부분으로 나눠서 각각 탐지하고 최종적으로 조합
YOLO replaces all of disparate parts with a single convolutional neural network. The network performs feature extraction, bounding box prediction, non-maximal suppression, and contextual reasoning all concurrently. Network trains the features in-line and optimizes them for the detection task.
R-CNN
- Similarity : Each grid cell proposes potential bounding boxes and scores those boxes using convolutional features
- Difference :
- Puts spatial constraints on the grid cell proposals which helps mitigate multiple detections of the same object
- Proposes far fewer bounding boxes
- Combines these individual components into a single, jointly optimized model
< Region Proposal >
: 객체 탐지에서, 이미지 안에서 객체가 있을 가능성이 높은 영역(region)을 제안하는 기법
Other Fast Detecters
Instead of trying to optimize individual components of a large detection pipline, YOLO throws out the pipeline entirely and is fast by design.
YOLO is a general purpose detector that learns to detect a variety of objects simultaneously
HOG (Histogram of Oriented Gradients)
: 이미지의 경계(edge) 방향과 크기를 분석해 특징 벡터를 만드는 기법
Deep MultiBox
Both YOLO and MultiBox use a convolutional network to predict bounding boxes in an image but YOLO is a complete detection system
MultiGrasp
: 로봇이 물체를 잡을 때, 여러가지 가능한 잡는 방법(Grasp)을 동시에 탐지하고 선택하는 기술
YOLO predicts both bounding boxes and class probabilites for multiple objects of multiple classes in an image
4. Experiments
mAP (mean Average Precision)
: 객체탐지모델이 얼마나 정확하게 객체를 탐지하는 지 종합적으로 평가하는 지표
값이 1에 가까울수록 완벽한 모델
mAP =
4-1. Comparison to Other Real-Time Systems
YOLO pushes mAP to 63.4% while still maintaining real-time performance
Training YOLO using VGG-16, is more accurate but also significantly slower than YOLO
4-2. VOC 2007 Error Analysis
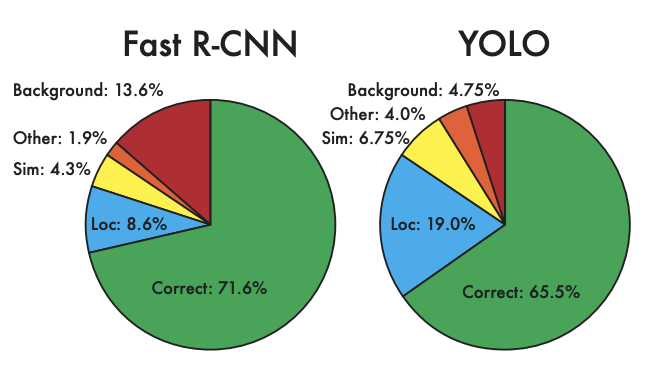
YOLO struggles to localize objects correctly
- Accuracy : YOLO < Fast R-CNN
- Background Error : YOLO < Fast R-CNN
4-3. Combining Fast R-CNN and YOLO
By using YOLO to eliminate background detections from Fast R-CNN we get a significant boost in performance
👍 YOLO makes different kinds of mistakes at test time that it is so effective at boosting Fast R-CNN's performance.
👎 This combination doesn't benefit from the speed of YOLO
→ Since YOLO is so fast it doesn't add any significant computational time compared to Fast R-CNN
4-4. VOC 2012 Results
- YOLO system struggles with small objects compared to its closest competitors.
- Combined Fast R-CNN + YOLO model is one of the highest performing detection methods.
4-5. Generalizability : Person Detection in Artwork
YOLO models the size and shape of objects, as well as relationships between objects and where objects commonly appear
5. Real-time Detection In The Wild
While YOLO processes images individually, when attached to a webcam it functions like a tracking system, detecting objects as they move around and change in appearance.
6. Conclusion
YOLO is trained on a loss function that directly corresponds to detection performance and the entire model is trained jointly.
Fast YOLO is the fastest general-purpose object detector in the literature and YOLO pushes the state-of-the-art in real-time object detection. YOLO also generalizes well to new domains making it ideal for applications that rely on fast, robust object detection.
