프로메테우스 프로젝트 주제가 결정됐다!
프로젝트 주제
< 이상형을 찾아주는 서비스 >
FaceNet을 이용해서 연예인 이상형 특징 찾기
→ 마음에 드는 연예인들의 평균을 매겨서 기준점 만들기
→ YOLO를 사용해서 일반인을 가져오고, 일반인의 얼굴 따기
→ 얼굴을 FaceNet에 실어서, 그 기준 벡터와의 유사도를 측정하기
→ 유사도를 %로 출력하기
이런 느낌으로 프로젝트가 진행될 예정이다!
인공지능 프로젝트가 뭔가 활용하는 데이터셋이랑 모델만 살짝 바꾸기만 해도 주제를 쉽게 바꿀 수 있는 것 같다..
데이터셋 만들기에서 내가 담당한 부분은 남자 아이돌 50명, 100장씩 얼굴 따오기!
요즘 남자 아이돌은 잘 모르지만ㅠ.. 10년만 젊었어도..
< 계획 >
1. Selenium을 사용해 이미지 크롤링
- Google 이미지 검색을 이용하거나 네이버, Pinterest 같은 사이트에서 크롤링
- 50명 각각 100장씩 저장
- 이미지 전처리 (얼굴 추출)
- OpenCV 라이브러리로 얼굴 감지 후 크롭
- 데이터 저장 및 관리
- 폴더 구조 정리 (idol_name/image_01.jpg 형식)
- 해상도 조정, 중복 제거
1. 남자아이돌 50명 찾기
우선 남자아이돌을 정리해보겠다.
- 방탄소년단 (7명)
- 세븐틴 (13명)
- 엔시티 (25명) << ?????
- 몬스타엑스 (6명)
- 차은우 (1명)
= 52명!
Thanks to NCT
이후에, 사진이 많은 없는 아이돌도 있어서
- 보이넥스트도어 (6명)
- 라이즈 (6명)
을 추가로 수집했다..!
2. 크롤링하기
pip3 install selenium webdriver-manager^ selenium 다운로드
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
import urllib.request
import urllib.parse
import time
import os
# 52명의 아이돌 리스트
idols = [
"방탄소년단 RM", "방탄소년단 진", "방탄소년단 슈가", "방탄소년단 제이홉", "방탄소년단 지민", "방탄소년단 뷔", "방탄소년단 정국",
"세븐틴 에스쿱스", "세븐틴 정한", "세븐틴 조슈아", "세븐틴 준", "세븐틴 호시", "세븐틴 원우", "세븐틴 우지",
"세븐틴 디에잇", "세븐틴 민규", "세븐틴 도겸", "세븐틴 승관", "세븐틴 버논", "세븐틴 디노",
"엔시티 쟈니", "엔시티 태용", "엔시티 유타", "엔시티 쿤", "엔시티 도영",
"엔시티 텐", "엔시티 재현", "엔시티 윈윈", "엔시티 정우", "엔시티 마크",
"엔시티 샤오쥔", "엔시티 헨드리", "엔시티 런쥔", "엔시티 제노", "엔시티 해찬",
"엔시티 재민", "엔시티 양양", "엔시티 천러", "엔시티 지성", "엔시티 시온",
"엔시티 리쿠", "엔시티 유우시", "엔시티 재희", "엔시티 료", "엔시티 사쿠야",
"몬스타엑스 셔누", "몬스타엑스 민혁", "몬스타엑스 기현", "몬스타엑스 형원", "몬스타엑스 주헌", "몬스타엑스 아이엠",
"차은우",
"보이넥스트도어 성호", "보이넥스트도어 리우", "보이넥스트도어 명재현", "보이넥스트도어 태산", "보이넥스트도어 이한", "보이넥스트도어 운학",
"라이즈 쇼타로", "라이즈 은석", "라이즈 성찬", "라이즈 원빈", "라이즈 소희", "라이즈 앤톤"
]
# 아이돌당 다운로드할 이미지 개수
image_cnt = 30
# 저장 디렉토리: Desktop/idols
desktop_path = os.path.join(os.path.expanduser("~"), "Desktop")
save_dir = os.path.join(desktop_path, "idols")
os.makedirs(save_dir, exist_ok=True)
# 웹드라이버 실행
driver = webdriver.Chrome()
def crawl_images_for_idol(idol, count):
# 구글 이미지 검색 URL
search_query = idol + " 고화질"
URL = "https://www.google.com/search?tbm=isch&q=" + urllib.parse.quote(search_query)
driver.get(URL)
time.sleep(5)
# 무한 스크롤 및 "더보기" 버튼 클릭으로 추가 이미지 로드
last_height = driver.execute_script("return document.body.scrollHeight")
while True:
driver.find_element(By.CSS_SELECTOR, "body").send_keys(Keys.END)
time.sleep(4)
try:
more_button = driver.find_element(By.CSS_SELECTOR, ".mye4qd")
more_button.click()
time.sleep(4)
except Exception:
pass
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
break
last_height = new_height
# 페이지 소스 파싱
soup = BeautifulSoup(driver.page_source, 'html.parser')
image_info_list = driver.find_elements(By.CSS_SELECTOR, '.mNsIhb')
image_and_name_list = []
download_cnt = 0
for i, image_info in enumerate(image_info_list):
if download_cnt >= count:
break
try:
img_tag = image_info.find_element(By.CSS_SELECTOR, 'img')
img_src = img_tag.get_attribute('src')
if not img_src:
continue
# 파일명: 아이돌이름_순번.jpg (공백은 "_"로 치환)
file_name = idol.replace(' ', '_') + '_' + str(download_cnt) + '.jpg'
image_and_name_list.append((img_src, file_name))
download_cnt += 1
except Exception as e:
print(f"❌ {idol} 이미지 추출 실패: {e}")
return image_and_name_list
# 아이돌 리스트에 대해 크롤링 실행
for idol in idols:
print(f"📸 {idol} 크롤링 시작...")
# 각 아이돌별 폴더 생성
idol_folder = os.path.join(save_dir, idol)
os.makedirs(idol_folder, exist_ok=True)
# 해당 아이돌의 이미지 정보 수집
images = crawl_images_for_idol(idol, image_cnt)
# 수집된 이미지 다운로드
for src, file_name in images:
try:
file_path = os.path.join(idol_folder, file_name)
urllib.request.urlretrieve(src, file_path)
print(f"✅ {idol} 이미지 저장 완료: {file_name}")
except Exception as e:
print(f"❌ {idol} 이미지 다운로드 실패: {e}")
print(f"📸 {idol} 크롤링 완료!\n")
driver.quit()
print("✅ 모든 이미지 크롤링 완료!")^ 남자아이돌 사진 크롤링 (고화질 / 셀카 / 얼굴사진 / 등등..)
서치 쿼리를 바꿔가면서 총 300장을 얻어왔다. (중복, 얼굴 안나온사진, 얼굴 추출 불가능 사진을 방지하기 위해 최대한 많이 긁어왔다..!)
3. 이미지 전처리
이제 얼굴을 추출할 것이다! OpenCV를 통해 쉽게 얼굴만 추출하는 코드를 작성했다.
import cv2
import os
input_dir = os.path.expanduser("~/Desktop/idols")
output_dir = os.path.expanduser("~/Desktop/idol_faces")
# Haar Cascade 로드
face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml')
# 저장 폴더 생성
os.makedirs(output_dir, exist_ok=True)
# 아이돌 폴더별로 처리
for idol_name in os.listdir(input_dir):
idol_path = os.path.join(input_dir, idol_name)
if not os.path.isdir(idol_path):
continue
save_path = os.path.join(output_dir, idol_name)
os.makedirs(save_path, exist_ok=True)
face_count = 0 # 얼굴 개수 카운터
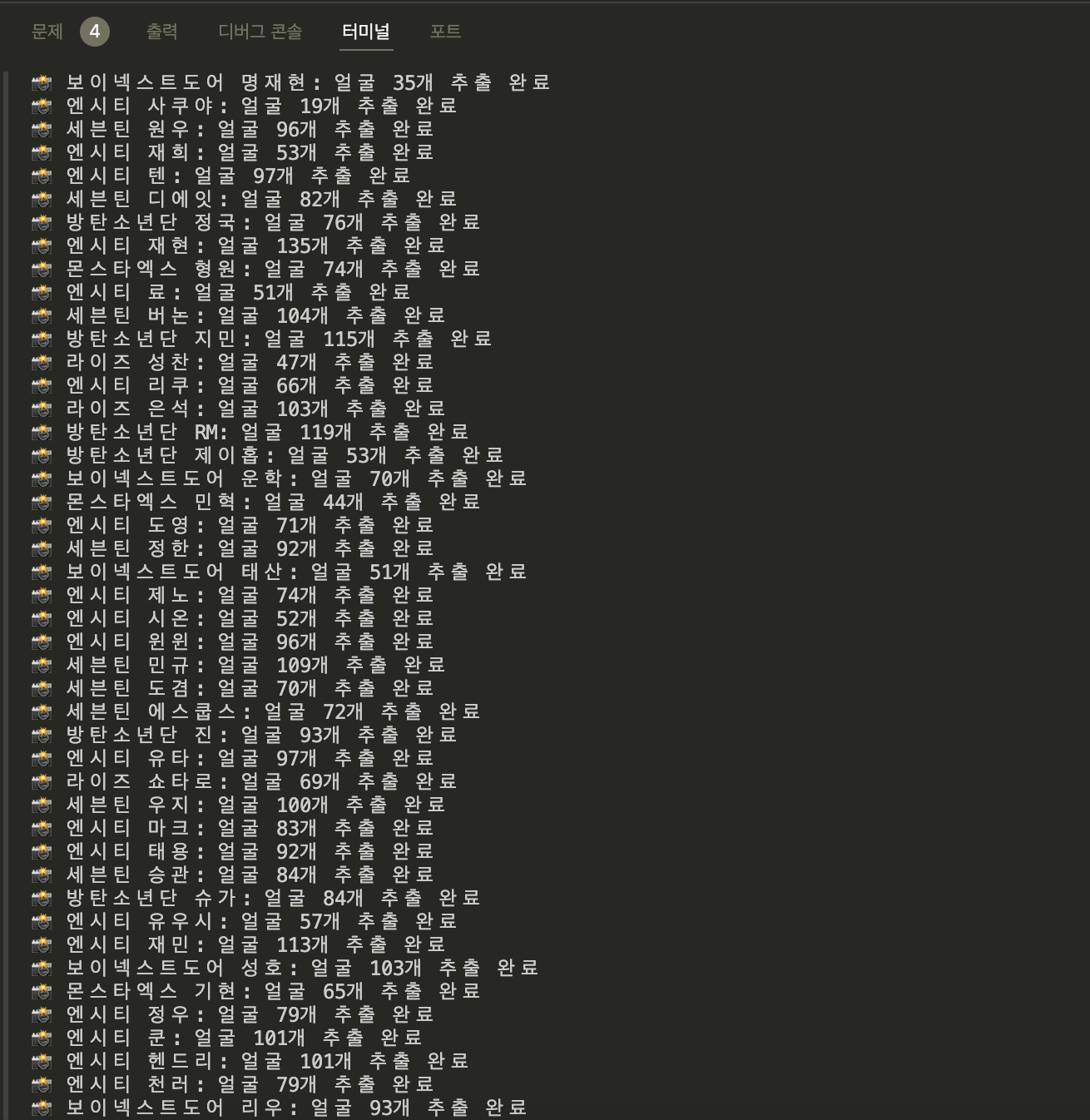
for image_file in os.listdir(idol_path):
image_path = os.path.join(idol_path, image_file)
img = cv2.imread(image_path)
if img is None:
continue
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, scaleFactor=1.3, minNeighbors=5)
for idx, (x, y, w, h) in enumerate(faces):
face_img = img[y:y+h, x:x+w]
face_filename = f"{os.path.splitext(image_file)[0]}_face{idx}.jpg"
cv2.imwrite(os.path.join(save_path, face_filename), face_img)
face_count += 1
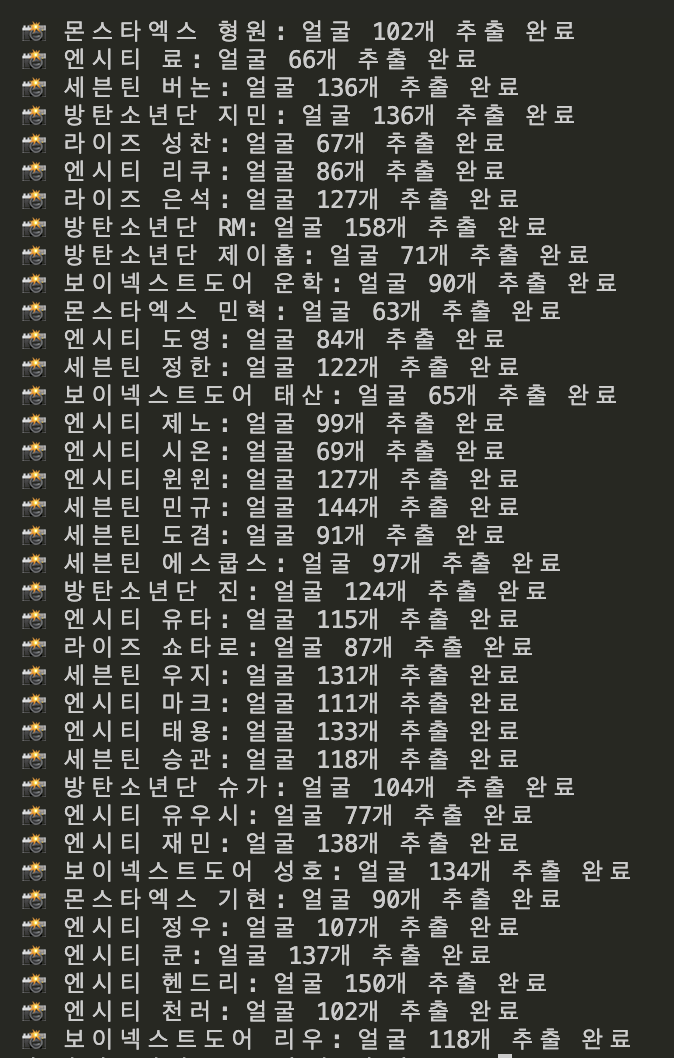
print(f"📸 {idol_name}: 얼굴 {face_count}개 추출 완료")우선 중복은,, 제거를 못하겠어서 이정도만 했다. 아이돌마다 얼굴이 잘나온 사진이 많으면 좀 많이 추출되고, 얼굴이 잘 안나온 사진은 추출을 못해서 사진 개수가 다 다르다..
약간 아쉽기는 한데 이걸 수습할 방법이 생각나지 않아서,, 아마 이게 최선인 것 같다ㅎㅎ!!
여기에서 전처리 후 사진 90장을 넘긴 아이돌들만 데리고 가기로 결정..~
아무튼 이렇게!! 프로젝트 데이터셋을 만들었다! 그렇게 어려운 건 없었는데, 사진에서 이미지 전처리를 하니까 열심히 크롤링한 사진들 개수가 갑자기 훅! 떨어져서 약간 아쉽다..ㅠ 뭐 어쩌겠어~ 끄읕!
