[Computer Vision] Survey on video compression techniques for efficient transmission
Abstract
Image Compression is the effective way to reduce the storage space and speedup the transmission. The Video transmission incurs higher bandwidth requirements. It is necessary to transfer the high quality images to the user devices without loss and latency.
This paper presents a survey of various research articles about the image or video compression techniques.
1. Introduction
Video compression techniques are used for reducing and removing the redundancy in video data. the compressed video file is smaller such that the video can be quickly transmitted over the network. The compression efficiency depends upon bit rate for a given resolution and frame rate. For lower bit rates, compression will be more efficient. In case the image quality is reduced, Video compression may be lossy. For lossy compression, efficient compression technique can be developed to provide good quality video. Even though the compressed video differs from the original, the differences are not clearly visible to the naked eye.
Video can be represented as a series of still frames. The sequence of frames contains both spatial and temporal redundancy. Many video compression algorithms use both spatial compression and temporal compression.
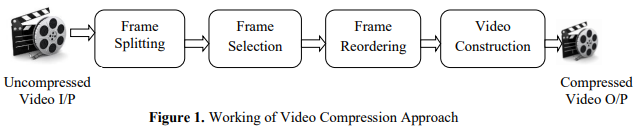
Frame Splitting
- The input uncompressed video is split into number of frames of images.
Fame Selection
- Selection of set of frames is made.
Frame Reordering
- Frames are reordered after compression.
Video Construction
- Video has been constructed to produce the compressed video.
The deframing is done by generating sequence of images. The number of images generated for 1 second of video is between 12 to 24 images. Set of frames are selected and reordered to produce a compressed video.
The objective of video compression is to provide the video content with low bit-rate, maintaining the good quality picture. Compression can be carried by identifying redundancy and removing it. Mostly video compression demands high quality video for encoding and transmission. However, a good quality video requires more amount of storage and network bandwidth.
2. Video Compression Techniques
2.1 Block Matching Techniques
Block Matching algorithm helps to find motion vector for each blocks within a search range and finds a best match that minimize error measure. Motion Vector is defined as the displacement of block location from current frame to the reference frame.
Block Matching Techniques
- Block Determination specifies the size and position of blocks in the current frame.
- The Search method used to indentify candidate block in the reference frames.
- Motion Estimation based temporal prediction is employed in MPEG video.
In this technique, high quality video can be obtained which incurs slight cost for the coding.
2.2 DCT Based Video Compresison
Discrete Cosine Transform(DTC) based video compression provides scalability. The compression mainly checks for the presence of redundancies among the several frames and correlation between them.
 DCT converts the entire pixel values into frequency representation residing the high frequency pixels. The frames are compressed and made into sequence to form compresssed video.
DCT converts the entire pixel values into frequency representation residing the high frequency pixels. The frames are compressed and made into sequence to form compresssed video.
This technique provides high compression ratio and gives better compressed quality video. This framework can be enhanced using video encoders to achieve higher quality video frames, high frame rate with high resolution.
2.3 DWT Based Video Compression
Discrete Wavelet Transform(DWT) is well known for its image processing and analysis techniques. The wavelets time frequency representation performs sign handling applications. DWT results in better mutilation image quality over the existing techniques.
The DWT architectures available in lifting based, convolution-based and B-spline based designs. The lifting based architectures were mostly preferred since they require less multipliers and adders.
DWT based Video Compression provides high compression ratio, low mean square error(MSE) and high peak signal to noise ratio.
2.4 Hybrid Wavelet Fractal based Video Compression
Hybrid Wavelet Fractal compression is based on self similarity within the images. The important thing in fractal based compression is to find the range for each image blocks. This makes the encoding computationally very expensive. The decoding is much faster than encoding and it depends on number of iterations. Fractal Video compression partitions the video data and then exploiting the self-similarity present in the video to reduce redundancy. Wavelets are introduced in fractal based Video Compression to achieve high compression gain and fidelity error. Compression ratio decreases as the wavelet passes increases. This can be applicable for 2D fractial images.
2.5 Frame Difference based Video Compression
Frame difference based video compression mothod extracts the frames from the input video then extracts the set of features. If the frame difference is higher, the frames are selected for video generation while the lower frame difference results in frame rejection.
Three different methods for frame rejection
- Zero difference approach
- The frames are eliminated when there is no difference between neighboring and adjacent frames occurs.
- Mean difference apporach
- The frame difference with less value than the mean value gets removed.
- Percentage difference approach
- based on percentage value of difference, the compression is performed.
2.6 Deep Frame Interpolation based Video Compression
By providing the dense motion compensation, deep frame interpolation network for video compression solves the block based motion vector problem between the consecutive frames. Each frame's are coded with bi-directional inter-prediction by adding one reference frame.
The HEVC bit stream is modified to use reference frame. Deep interpolated frames are entropy coded to reduce syntax size. Deep frame interpolation manages several types of geometrical distortions by providing compact motion compensation.
2.7 Machine Learning based Video Compression
Machine learning based compression offers improved capabilities on complex data. This can be performed by automated analytical model with dynamic prediction. This type of machine learning approach fails in case of untrained videos since incapable of performing encoding operation.
2.8 Deep Learning based Video Compression
With the latest advancement in Deep Learning techniques, Convolutional Neural Network(CNN) based video compression framework is proposed in DeepCoder. Huffman Coding and Scalar Quantization techniques are used to encode feature maps into bit streams.
For 32x32 block, with H.264/AVC Deep Neural Network based video compression shows similar coding efficiency in compressing the video signal but it promises the great potential for future video coding.
There are several other deep learning frameworks are widely used for research such as TensorFlow, more recently PyTorch.
Reference
DeepCoder: A Deep Neural Network Based Video Compression.
2.9 RNN based Video Compression
Recurrent Neural Network(RNN) is a hierarchical network in which the input needs hierarchical process in the form of a tree. Recurrent Neural Network can be extended overtime. In a Paper, the method trains the images and selects the frames for compression based on classification.
The author proposed a new approach for pre and post processing using RNN. The framework consists of scalable parts which allow transmitting the frames and reconstructing with high accuracy. This algorithm works along with classic codec H.264.
Reference
State-of-the-art in artificial neural network applications: A survey
2.10 DNN based Video Compression
Conventional Video compression uses predictive coding. In a Paper, proposed End-to-end Deep Video Compression Framework to optimize the trade-off between compression ratio and quality. Deep models provide accurate motion information at pixel-level, which can be optimized end-to-end. Correspondingly, deep models are faster than the Conventional Video compression. Based on this framework, new approaches for optical flow, bi-directional prediction and control rate can be analyzed.
Reference
A Survey of Deep Neural Network Architectures and Their Applications
2.11 Region of Interest based Video Compression
ROI Detection Algorithm(RDA) is based on spatiotemporal coherent region detection from color and motion similarity analysis and posing the problem of grouping of these regions as an optimization problem.
Color and positional similarity evaluation has been done using graph-cut in feature space; and motion similarity assessment has been done using phase-correlation based motion segmentation.
By combining the color, motion and positional similarity, background regions are segregated and the initial ROI regions are generated. In the next step, the initial ROI regions are grouped to form the final Region(s) of Interest. In grouping model, predicate D is defined, for evaluation of two spatio-temporal regions. This is based upon dissimilarities among neighboring elements and adaptive with respect to the local characteristics of the data. This predicate determines the cost for the cluster.
ROI region grouping algorithm aims at minimization of grouping cost of the entire scene.
2.12 Light Field based Video Compression
Light field video normally captured by arrays of cameras represents tens to hundreds of images at a instance. Light Field based Video Compression method reduces the storage requirements by more than 95% while maintaining the visual quality.
Combining with ROI and Light Field technique, the compression method can protect 5% to 7% bitrates in compared with conventional Light Field video compression technique.
Content based light field method provides good visual quality with improved compression efficiency.
2.13 Object based Video Compression
In this type of video compression, different objects are matched with the frames for compression.
Video encoding structure achieves object detection, diminishes time based variations, provides rate-distortion and destroys redundant temporal fluctuations.
Hybrid object based video compression; a new object segmentation tool is incorporated for both objects and blocks results in high prediction accuracy.
2.14 Color Spaced based Video Compression
This approach extracts the color space from the initial image. The frame selection is done based on the similarity of color space measurements.
In a Paper, the experiment was conducted for a set of 39 HDR video which utilizes cutting edge methodology. Based on this, compression efficiency, quality and complexity of the images gets derived.
Reference
Video Server Retrieval Scheduling and Resource Reservation for Variable Bit Rate Scalable Video
2.15 Learning CCTV Compression
In CCTV, for digitizing signal 150mbps of digital stream can be achieved with lot of redundant information. Generally CCTV compression algorithms are lossy, because of higher compression ratio.
There are two categories of CCTV compression available namely Frame and Stream based compression. Besides Frame based compression, Stream based compression is widely used and provides more storage and simple transmission.
The Stream based CCTV Compression Algorithms
- JPEG2000
- MJPEG(Motion JPEG)
- H.264
- MPEG-4
JPEG2000 provides good quality image. Another advantage is that, it is good for motion detection algorithm since decompresses lower resolution. JPEG2000 requires high system performance thereby making it complex.
Motion JPEG is the most common compression algorithm for stream based CCTV compression and is most suitable for video storage.
H.264 is 50-80% efficient than MPEG-4. For limited bandwidth, MPEG-4 and H.264 algorithms are suitable.
In terms of compression ratio, MPEG-4 is three times more efficient than MJPEG. However, it will be a wrong choice for the systems having 5-6 frames.
Comparative Study
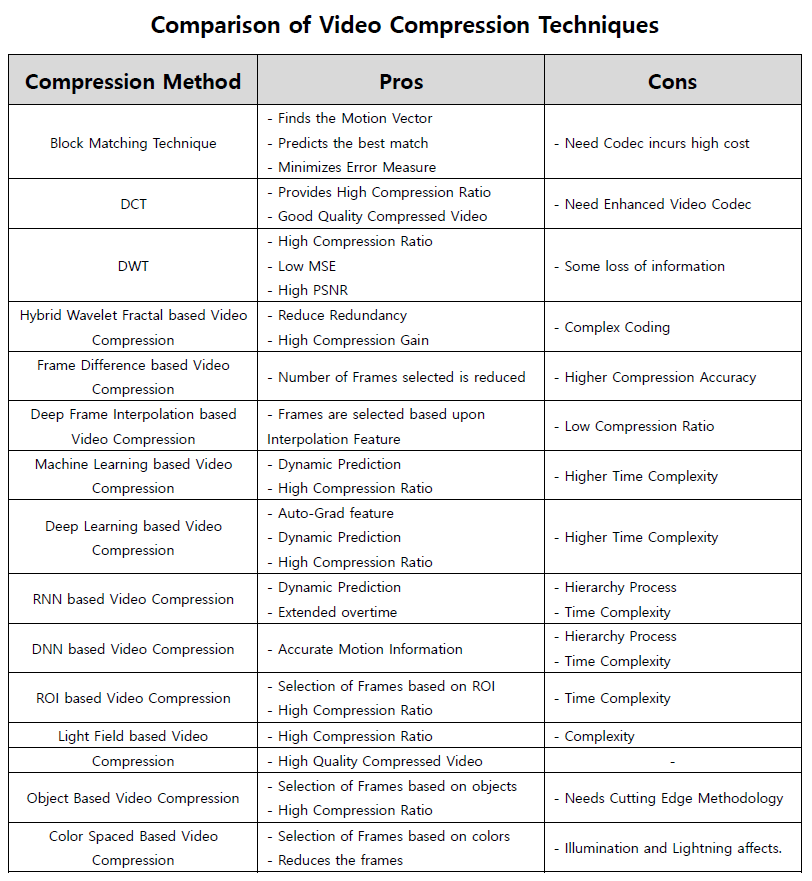
Conclusion
This paper presents a detailed survey on various methods of video compression for space reduction and efficient transmission over the network bandwidth. As part of analyzing the video compression techniques, we can understand different methods have different implications. Further studies may be carried out based on several hybrid compression models.

4개의 댓글

Lowes Customer Satisfaction Survey is an online platform that serves many questions and ratings to the customers and guests to know about their performance for every month
Nice Post,
Thanks for sharing this information with us
ShopRite is among the most renowned chains of supermarkets appreciates your feedback and is determined to improve the shopping experience.
https://myshopriteexperiences.net/
Conducting surveys is the best technique to know the customers genuine feedback. Nowadays most of the well known companies are following the same online survey method to know their customers visiting exerience to better their companies services. Recently I personally participated in the official lowes customer satisfaction sweepstakes survey at https://lowescomsurvey.co/ website and shared my honest experience with them and luckily I shortlisted to win a $500 gift card for free. This lowes customer survey took 10 minutes of my time and every month five lucky customers have an amazing chance to get a $500 gift card for free.