[Computer Vision] Multi-Stage Progressive Image Restoration
Super Resolution
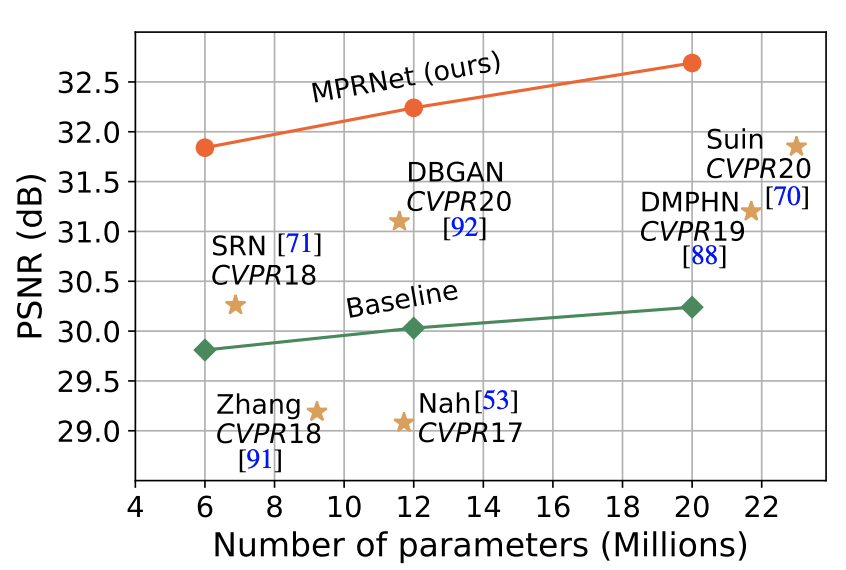
이미지 복원 작업은 이미지를 복원하는 동안 공간 세부 정보와 높은 수준의 contextualized 정보 간의 복잡한 균형을 요구한다. 이 논문에서 저자들은 이 균형을 맞춰줄 수 있는 새로운 모델로 Multi-stage 구조를 제안했다.
저자들이 제안한 이 모델은 degrade된 input에 대한 복원 기능을 점진적으로 학습하여 전체 복원 프로세스를 관리 가능한 단계로 세분화한다.
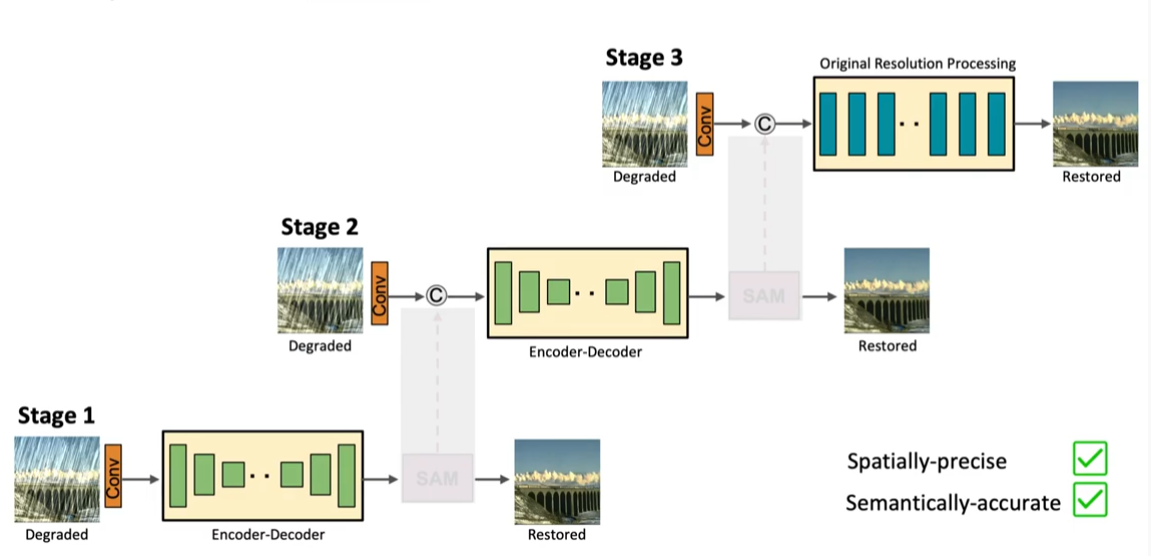
처음에 모델은 Encoder-Decoder 구조를 이용하여 contextualized function을 학습하고, 나중에 이것과 local 정보를 유지하는 고해상도 branch와 결합한다. 그리고 각 단계에서 local feature들의 가중치를 재조정하기 위해 내부 supervised attention을 활용하는 새로운 per-pixel adaptive design을 도입한다.
adaptive design이란 각기 다른 이미지 크기 마다 그에 알맞게 조정되는 graphical user interface (GUI) design을 말한다.
multi-stage 구조에서 핵심 요소는 다른 단계들 사이 간 정보 교환이다. 저자들은 정보가 초기 단계부터 후기 단계까지 순차적으로 교환되는 것과 정보의 손실을 막기 위한 feature processing block들 사이의 측면 연결, 이 두 가지 접근법을 제안한다.
긴밀하게 연결된 multi-stage 구조를 MPRNet이라 부르며, 이는 deraining, deblurring, denoising 등 다양한 작업에 걸쳐 10개의 dataset에서 강력한 성능 향상을 보인다.
Encoder-Decoder Subnetwork
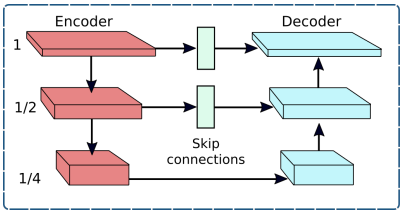 Encoder-Decoder Subnetwork는 기본 U-Net을 기반으로 하였으며, network의 구성요소는 다음과 같다.
Encoder-Decoder Subnetwork는 기본 U-Net을 기반으로 하였으며, network의 구성요소는 다음과 같다.
- 각각의 scale에서 feature들을 추출하기 위해 channel attention blocks(CABs)를 추가하였다.
- U-Net skip connections에서 feature maps은 CAB과 함께 진행되었다.
- Decoder 단계에서 feature들의 공간 해상도(spatial resolution)를 향상시키기 위해 Transposed convolution 대신 한 개의 convolution에서 bilinear upsampling하는 방법을 사용하였다.
Original Resolution Subnetwork
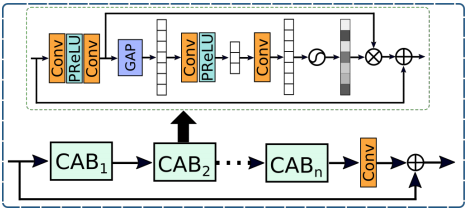
input 이미지에서 output 이미지까지 fine detail들을 보존하기 위해 저자들은 후기 단계에서 original-resolution subnetwork(ORSNet)을 도입하였다. ORSNet은 downsampling operation을 사용하지 않고 공간적으로 풍부한 고해상도 feature들을 만들어냈다. 이것은 여러 original resolution blocks(ORBs)로 구성되어 있으며, 각 block에는 CABs가 추가로 포함되어 있다.
Cross-stage Feature Fusion
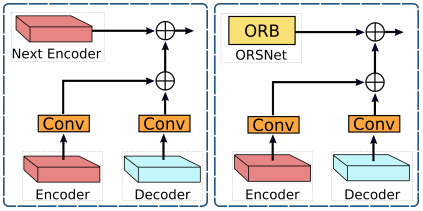
저자들은 Encoder-Decoders 사이(왼쪽)와 Encoder-Decoder과 ORSNet 사이(오른쪽)에 Cross-stage Feature Fusion(CSFF) 모듈을 도입하였다. 제안한 CSFF는 몇 가지 장점들을 가지고 있다.
- Encoder-Decoder에서 Up-sampling과 Down-sampling을 반복적으로 사용하여 네트워크 정보 손실에 덜 취약하게 만든다.
- 한 단계의 multi-scale feature들은 다음 단계의 feature들을 풍부하게 하는 데에 도움이 된다.
- 네트워크 최적화 절차는 정보의 흐름을 용이하게 만들어 보다 안정적이게 되고, 이로 인해 전체 구조에 여러 단계를 추가할 수 있게 한다.
Supervised Attention Module
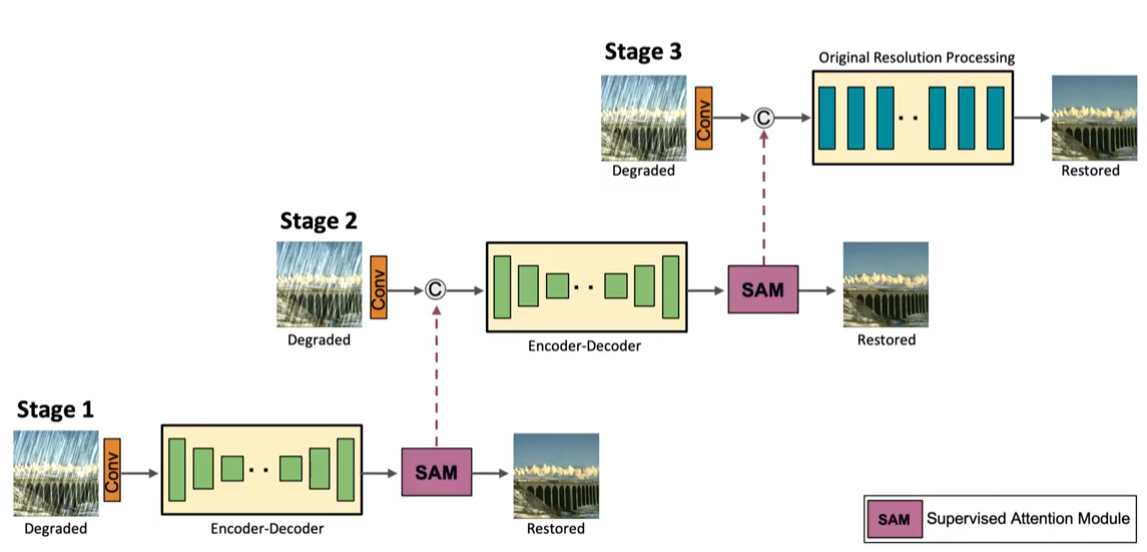
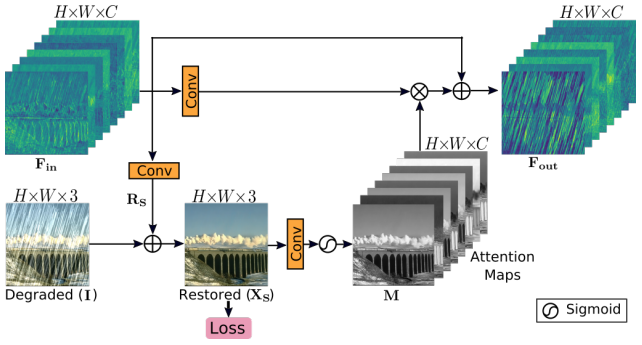
최근 image 복원을 위한 multi-stage 네트워크들은 각 단계에서 바로 이미지를 예측하고 다음 단계로 통과된다. 하지만 저자들은 모든 두 단계 사이에 supervised attention module(SAM)을 도입했고, 이로 인해 충분한 성능을 얻을 수 있게 되었다. SAM은 다음과 같이 두 가지를 기여하였다.
- 각 단계에서 점진적인 이미지 복원에 유용한 ground truth supervisory 신호를 제공한다.
- locall supervised predictions의 도움으로 현재 단계에서 덜 유익한 feature들을 억제하고, 유용한 features만 다음 단계로 전파하도록 attention map들을 생성한다.
Expreiment Results
1. Image Deraining Results

2. Image Deblurring Results

3. Image Denoising Results

MPRNet Code
https://github.com/seogihyun/Super_Resolution/tree/master/MPRNet
