
본 시리즈는 프로그래밍 자료구조의 개념을 정리하고 실습을 진행해보는 시리즈입니다.
- 실습은 다음과 같은 개발환경 및 버전에서 진행하였습니다.
- IDE : IntelliJ IDEA (Ultimate Edition)
- Java : JDK 21 (corretto-21)
- Python : 3.9 (conda env)
자료구조 - Hashtable (Part 1)
- 이번 포스팅부터는 자료구조에서 정말 자주 사용되는 Hashtable에 대해서 정리해보고자 합니다.
- 다루어야 할 내용이 많고 복잡할 수 있어, 여러 파트로 나누어 설명하려고 합니다.
- 이번 포스팅에서는
Hashtable의 기본적인 개념과 원리, 그리고 Hash 충돌이 발생했을 때 이를 해결하는 방법에 대해 설명하겠습니다.- 이후 포스팅부터 Java와 Python에서의 Hashtable 구현 및 사용법을 코드와 함께 정리해보려합니다!
이제 본격적으로 해시테이블의 기본 개념을 살펴보겠습니다.
1. Hash Code와 Hash Function
해시테이블(Hashtable)은 데이터를 효율적으로 저장하고 검색하기 위한 자료구조입니다.
- 이 구조의 핵심 개념 중 두 가지를 꼽아보면 해시 함수(Hash Function)와 해시 코드(Hash Code)입니다.
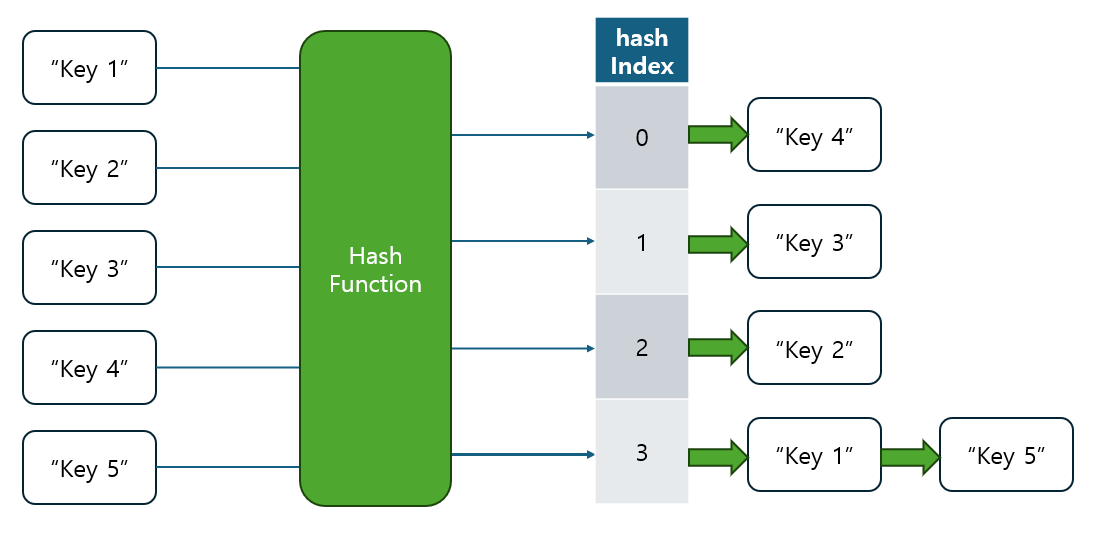
그럼 먼저 Hash Function이 무엇인지 살펴봅시다 !
1.1 Hash Function이란?
해시 함수(Hash Function)는 임의의 크기를 가진 입력 데이터를 고정된 크기의 값으로 변환하는 함수입니다.
- 입력값은 어떤 종류의 데이터라도 상관없습니다. 숫자, 문자열, 객체 등 다양할 수 있습니다.
- 해시 함수는 이 데이터를 받아 특정 규칙에 따라 고정된 길이의 값(숫자, 주로 정수)을 생성해 줍니다.
- 이렇게 생성된 숫자를 Hash Code(해시 코드)라고 합니다.
예시
쉽게 이해하기 위해 간단한 예를 들어 보겠습니다.
- 만약 여러분이
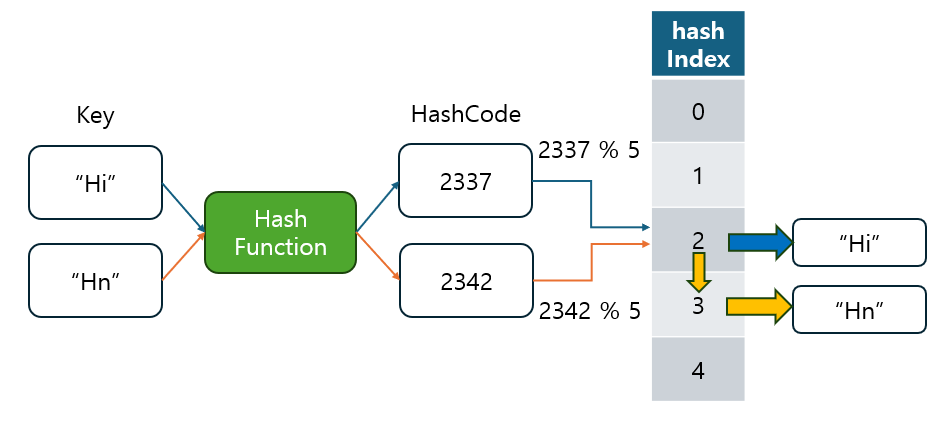
"Hi"라는 문자열을 해시 함수에 넣으면, 그 문자열은 다음과 같은 고정된 숫자로 변환됩니다
"Hi" --> 2337이 숫자는 Java에서 "Hi"라는 문자열을 해시 함수에 넣었을 때 반환되는 값(해시 코드)입니다.
- 이 숫자는 고정된 크기를 가지며, 데이터를 더 빠르게 검색하거나 저장할 때 사용됩니다.
Q. "Hi"는 왜 2337이 되었나요?
Java에서는 문자열을 유니코드 값으로 처리한 뒤, 각 문자의 값을 31씩 곱하고 더하는 방식으로 해시 코드를 계산합니다.
- 예를 들어,
"Hi"의 해시 코드는'H'(72) * 31 + 'i'(105) = 2337입니다.- 참고로, Python의 해시 함수는 보안 강화를 위해 실행할 때마다 해시 값을 무작위로 변경하는 Hash Randomization이라는 기능을 사용합니다.
- 같은 문자열이더라도 실행할 때마다 다른 해시 값을 반환할 수 있지만, 한 실행 내에서는 일관된 해시 값을 유지합니다.
- 이 부분은 너무 복잡하게 생각할 필요 없이, 실행 중에는 같은 문자열에 대해 일관된 결과를 준다고 기억하시면 됩니다.
아무튼 어떤 종류의 데이터라도 특정 규칙에 따라 고정된 값(정수)가 나오도록 하는 함수가 바로 해시 함수이고, 그 결과가 해시 코드이다! 이것만 기억하시면 됩니다.
1.2 Hash Code란?
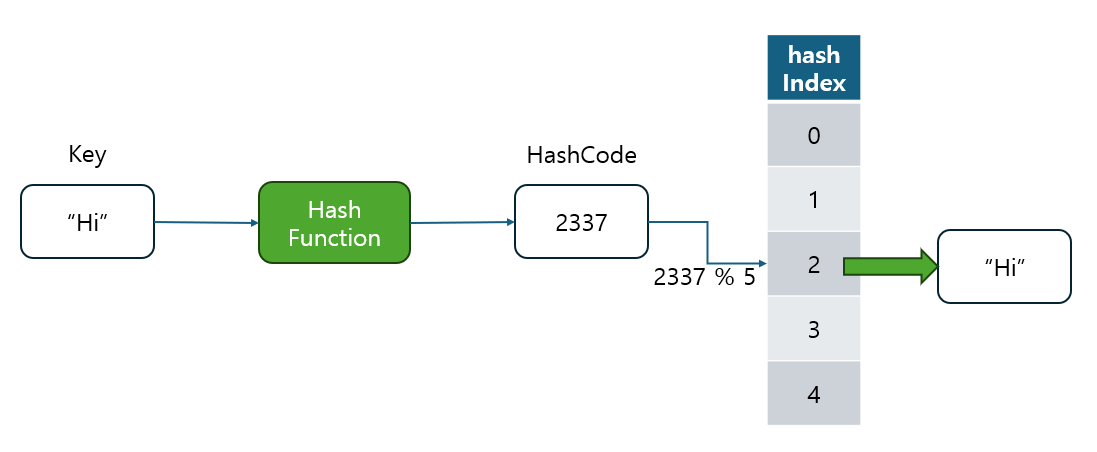
해시 코드(Hash Code)는 해시 함수에 의해 계산된 고정된 길이의 숫자입니다.
- 이 숫자는 해시테이블에서 데이터를 저장하거나 검색할 때 사용됩니다.
- 해시 코드를 사용하면 원본 데이터를 직접 비교하지 않고도 빠르게 탐색할 수 있습니다.
이렇게 계산 된 해시 코드는 일반적으로 테이블(혹은 배열)의 크기를 기준으로 나머지 연산을 통해 테이블 내의 특정 인덱스에 매핑됩니다.
- 예를 들어,
2337이라는 해시 코드가 있고, 배열의 길이가10이라면 10으로 나눈 나머지인7을 사용해서 데이터를 저장하거나 검색하는 인덱스를 결정하게 됩니다.- 이처럼 나머지 연산을 통해 매핑된 인덱스를 해시 인덱스라고 합니다.
Q. 해시 코드를 사용하는 이유는 뭔가요?
- 데이터를 직접 비교하는 대신, 해시 코드를 사용하여 더 빠르게 데이터를 탐색할 수 있기 때문입니다.
- 예를 들어, 대량의 문자열이 있을 때, 각각의 문자열을 하나하나 비교하는 대신, 해시 코드를 먼저 비교하여 빠르게 일치 여부를 판단할 수 있습니다.
- 이 덕분에 탐색 속도가 크게 향상됩니다.
2. Hash 충돌(collision)과 해결 방법
2.1 Hash 충돌이란?
해시 함수가 서로 다른 두 개 이상의 키에 대해 동일한 해시 코드를 반환할 때를 해시 충돌(Hash Collision)이라고 합니다.
- 예를 들어, 두 개의 키
"Key1"과"Key2"가 있을 때, 이 두 키가 모두 동일한 해시 인덱스로 매핑된다면, 해시 충돌이 발생하게 됩니다. - 해시 함수는 고정된 크기의 값을 반환하기 때문에, 다양한 데이터가 있을 경우 충돌이 발생하는 것은 자연스러운 현상입니다.
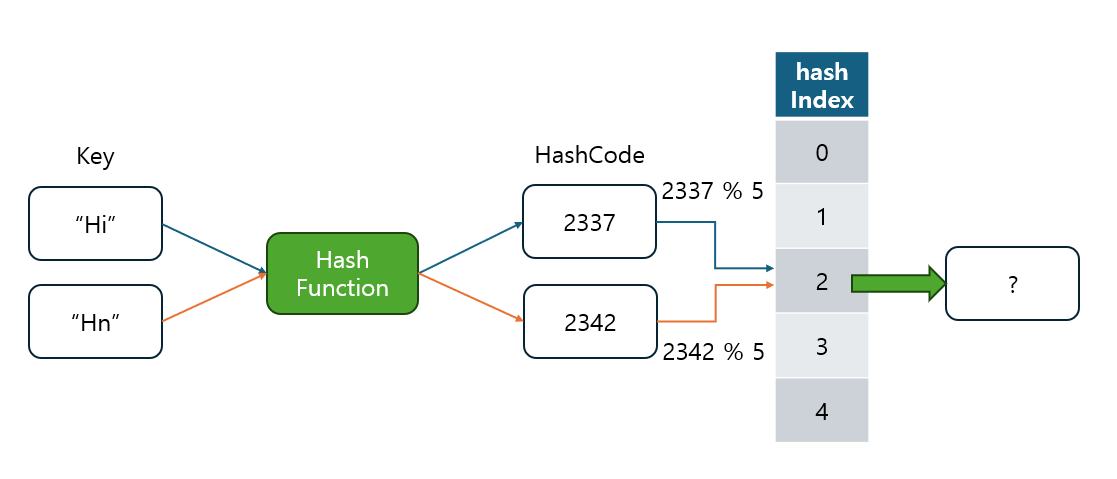
Q. 충돌이 발생하면 어떤 문제가 있나요?
- 해시 테이블에서 충돌이 발생하면, 동일한 인덱스에 여러 데이터가 저장되므로 데이터를 저장하거나 검색하는 과정이 복잡해집니다.
- 이를 해결하지 않으면 해시 테이블의 효율성이 크게 떨어집니다.
따라서 해시 충돌이 발생했을 때 이를 어떻게 처리할 것인지가 중요한데, 해시 충돌을 해결하는 방법은 크게 개별 체이닝(Separate Chaining)과 개방 주소법(Open Addressing) 두 가지로 나뉩니다.
2.2 해시 충돌 해결 방법
- 개별 체이닝(Separate Chaining)
- 동일한 해시 인덱스에 여러 개의 데이터를 저장할 수 있도록 리스트나 트리와 같은 자료구조를 사용하는 방법입니다.
- 충돌이 발생한 인덱스에 모든 데이터를 하나의 리스트에 연결하는 방식으로, 충돌이 발생하더라도 해당 인덱스에서만 데이터를 처리하면 됩니다.
- 이 방식은 테이블 크기와 관계없이 유연하게 사용할 수 있습니다.
Java에서 이 방식을 채택하여 해시테이블(Set, Map)에 적용합니다.
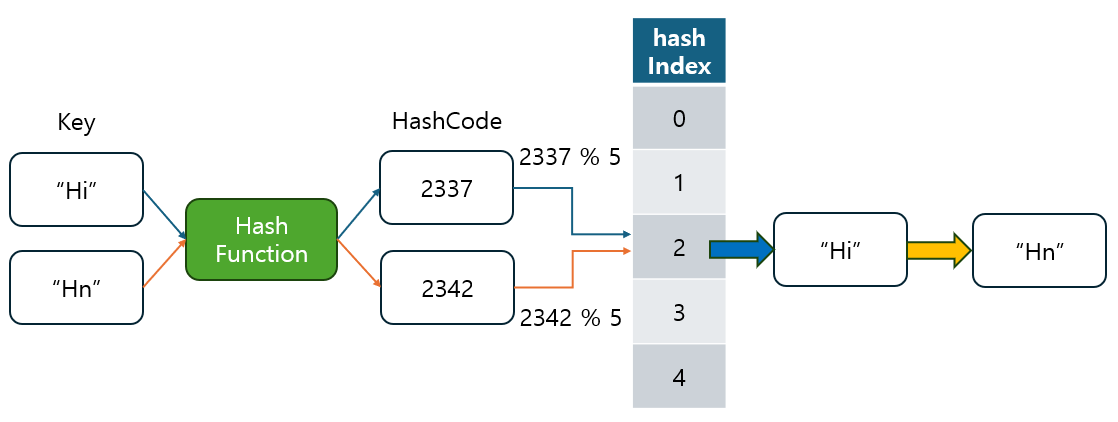
- 개방 주소법(Open Addressing)
- 해시 충돌이 발생했을 때, 충돌이 발생한 인덱스 대신 다른 빈 인덱스에 데이터를 저장하는 방식입니다.
- 이때 다음 빈 인덱스를 찾는 방식으로는 선형 탐사(Linear Probing), 제곱 탐사(Quadratic Probing), 이중 해시(Double Hashing) 등이 있습니다.
- 충돌이 발생하면 다른 위치에 저장하므로 추가적인 자료구조가 필요 없고, 단일 배열에서 모든 데이터를 관리할 수 있습니다.
Python이 이 방식을 채택하여 해시테이블(dict)에 적용합니다.
2.3 해시 충돌 해결 방법 별 장단점
개별 체이닝(Separate Chaining)
- 장점:
- 해시 충돌이 빈번한 상황에서도 유연하게 처리 가능합니다.
- 테이블 크기 조정이 필요하지 않습니다.
- 단점:
- 추가 메모리(리스트 또는 트리)를 사용하기 때문에 메모리 효율이 떨어질 수 있습니다.
- 충돌이 많아질수록 리스트가 길어져 성능이 저하 될 수 있습니다.
개방 주소법(Open Addressing)
- 장점: 데이터를 단일 배열에서 관리하므로 메모리 효율이 좋습니다.
- 단점: 충돌이 발생할 때 새로운 빈 인덱스를 찾아야 하므로, 충돌이 많아질수록 탐색 시간이 증가할 수 있습니다.
2.4 충돌 해결 방법 활용 사례 및 선택 기준
어떤 해시 충돌 해결 방법을 선택할지는 데이터의 크기, 메모리 사용량, 성능 요구사항 등에 따라 달라집니다.
- 개별 체이닝은 충돌이 많을 때 유리하며, 메모리 사용에 여유가 있는 환경에서 자주 사용됩니다.
- 개별 체이닝 방식은 Java의
HashMap,HashSet과 같은 자료구조에서 사용됩니다.
- 개별 체이닝 방식은 Java의
- 개방 주소법은 데이터 밀도가 낮거나 메모리 사용을 최소화해야 할 때 적합합니다.
- 작은 크기의 테이블이나 탐색 효율이 중요한 경우 유리합니다.
- Python의
dict와 같은 해시테이블에서 많이 사용됩니다.
위 두 방법 중 어느 방식이 더 나을지에 대한 절대적인 정답은 없습니다.
- 그래서 각 언어와 라이브러리에서는 각자의 설계 목표에 따라 서로 다른 방식이 선택되고 최적화되었습니다.
- 예를 들어, Java는 개별 체이닝 방식으로 해시 충돌을 처리하며, 이 방법은 대규모 데이터를 다룰 때 유연한 처리를 제공합니다.
- 반면에 Python은 개방 주소법을 채택하여, 상대적으로 메모리 효율성을 극대화하는 데 중점을 둡니다.
결론적으로, 데이터의 특성과 환경에 맞춰 각각의 방법이 활용될 수 있으며, 사용자가 환경에 맞는 방식을 선택하거나 언어에서 제공하는 최적의 해시테이블을 사용하면 됩니다.
3. Java와 Python의 Hashtable 예시
이제 해시 테이블의 기본 개념과 해시 충돌 해결 방법에 대해 어느정도 알아보았으니, Java와 Python에서 실제로 해시 테이블이 어떻게 구현되고 사용되는지 간단히 살펴보겠습니다.
- 각 언어별 구체적인 내용은 다음 포스팅부터 다룹니다.
3.1 Java에서의 Hashtable
Java에서 해시 테이블은 주로 HashMap과 HashSet과 같은 클래스에서 구현됩니다.
- 이들은 모두 개별 체이닝(Separate Chaining) 방식을 사용하여 해시 충돌을 해결합니다.
HashMap: Entry라고도 불리는 키-값 쌍을 저장하는 자료구조입니다. 키를 해시 함수로 해시코드로 변환한 후, 해시코드를 이용해 데이터를 저장합니다.
HashSet: 유일한 값을 저장하기 위한 자료구조로, 내부적으로 HashMap을 사용해 중복을 방지합니다. (쉽게 말해서 Key만 존재하는 HashMap이라 보시면 됩니다)
import java.util.HashMap;
public class HashMapExample {
public static void main(String[] args) {
// HashMap 생성
HashMap<String, Integer> map = new HashMap<>();
// 데이터 삽입
map.put("apple", 10);
map.put("banana", 20);
// 데이터 조회
System.out.println(map.get("apple")); // 10 출력
// 데이터 삭제
map.remove("banana");
}
}3.2 Python에서의 Hashtable
Python에서는 dict와 set이 해시 테이블로 구현되어 있으며, 주로 개방 주소법(Open Addressing)을 사용해 해시 충돌을 해결합니다.
dict: 키-값 쌍을 저장하는 자료구조로, 해시 함수를 사용해 키를 인덱스로 변환하고 데이터를 저장합니다.set: 중복되지 않는 유일한 값을 저장하는 자료구조로, 내부적으로dict를 사용하여 값의 존재 여부를 해시 테이블로 처리합니다.
# Python dict 예시
my_dict = {"apple": 10, "banana": 20}
# 데이터 조회
print(my_dict["apple"]) # 10 출력
# 데이터 삽입
my_dict["orange"] = 30
# 데이터 삭제
del my_dict["banana"]마무리
이번 포스팅에서는 해시 테이블의 기본 개념과 이를 구성하는 해시 함수(Hash Function), 해시 코드(Hash Code)의 원리를 다루었습니다.
또한, 해시 충돌이 발생하는 원리와 이를 해결하기 위한 두 가지 방법, 개별 체이닝(Separate Chaining)과 개방 주소법(Open Addressing)에 대해서도 알아보았습니다.
- 해시 함수는 데이터를 고정된 크기의 숫자(해시코드)로 변환하여 빠른 검색과 저장을 가능하게 합니다.
- 해시 충돌은 동일한 해시 코드로 인해 여러 데이터가 같은 인덱스에 저장되는 문제이며, 이를 해결하는 방법으로는 개별 체이닝과 개방 주소법이 있었습니다.
또한, 간단한 예시를 통해 Java의 HashMap과 HashSet, 그리고 Python의 dict와 set에서 해시 테이블이 어떻게 동작하는지를 간단하게 살펴보았습니다.
다음 포스팅에서는 먼저 Java에서의 해시 테이블 구현을 좀 더 구체적으로 다루어 보겠습니다.
- Java에서 제공하는
HashMap,HashSet,LinkedHashMap등의 자료구조를 비교하고, 이들이 어떻게 해시 충돌을 처리하는지, 그리고 성능 측면에서 어떤 차이가 있는지에 대해 깊이 있게 다루어볼 예정입니다.
