
본 시리즈는 프로그래밍 자료구조의 개념을 정리하고 실습을 진행해보는 시리즈입니다.
- 실습은 다음과 같은 개발환경 및 버전에서 진행하였습니다.
- IDE : IntelliJ IDEA (Ultimate Edition)
- Java : JDK 21 (corretto-21)
- Python : 3.9 (conda env)
자료구조 - Hashtable (Part 2-1)
- 이번 포스팅에서는 지난 포스팅에서 다룬 Hashtable이 Java에서 어떻게 활용되는지를 구체적으로 다루어 보고자합니다.
- 그래서 Java의 해시테이블들의 특징 및 동작 원리를 살펴보고
HashSet,HashMap,LinkedHashSet,LinkedHashMap과 같은 구현체들을 다루어볼 예정입니다.
0. 서론 : Hashing 개념의 간단한 복습
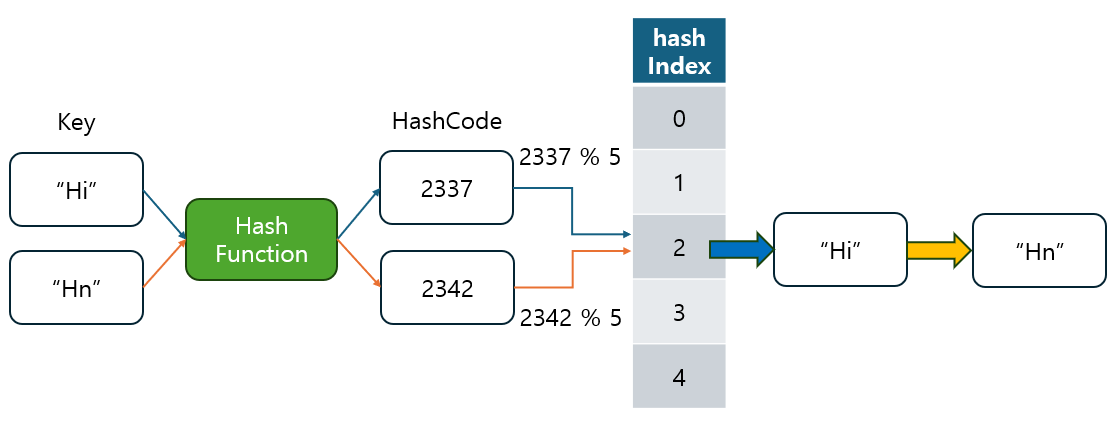
지난 포스팅에서는 해시 함수(Hash Function)의 개념과, 해시 코드(Hash Code)가 어떻게 생성되는지를 살펴보았습니다.
- 해시 함수는 데이터를 고정된 크기의 숫자로 변환하여 빠르고 효율적인 데이터 검색과 저장을 가능하게 해주는 중요한 도구입니다.
- 그러나 해시 함수를 통해 생성된 여러 값들이 서로 충돌하는 해시 충돌(Hash Collision)이 발생할 가능성도 확인했었습니다.
- 그래서 이 문제를 해결하기 위한 방법으로 Separate Chaining(체이닝 방식)과 Open Addressing(개방 주소 방식)과 같은 기법들을 다뤘습니다.
이번 포스팅에서는 이러한 해싱(Hashing) 개념이 Java에서 어떻게 적용되고 구현되는지를 좀 더 구체적으로 살펴보도록 합시다!
1. Java의 해시테이블 구현체 - 개요
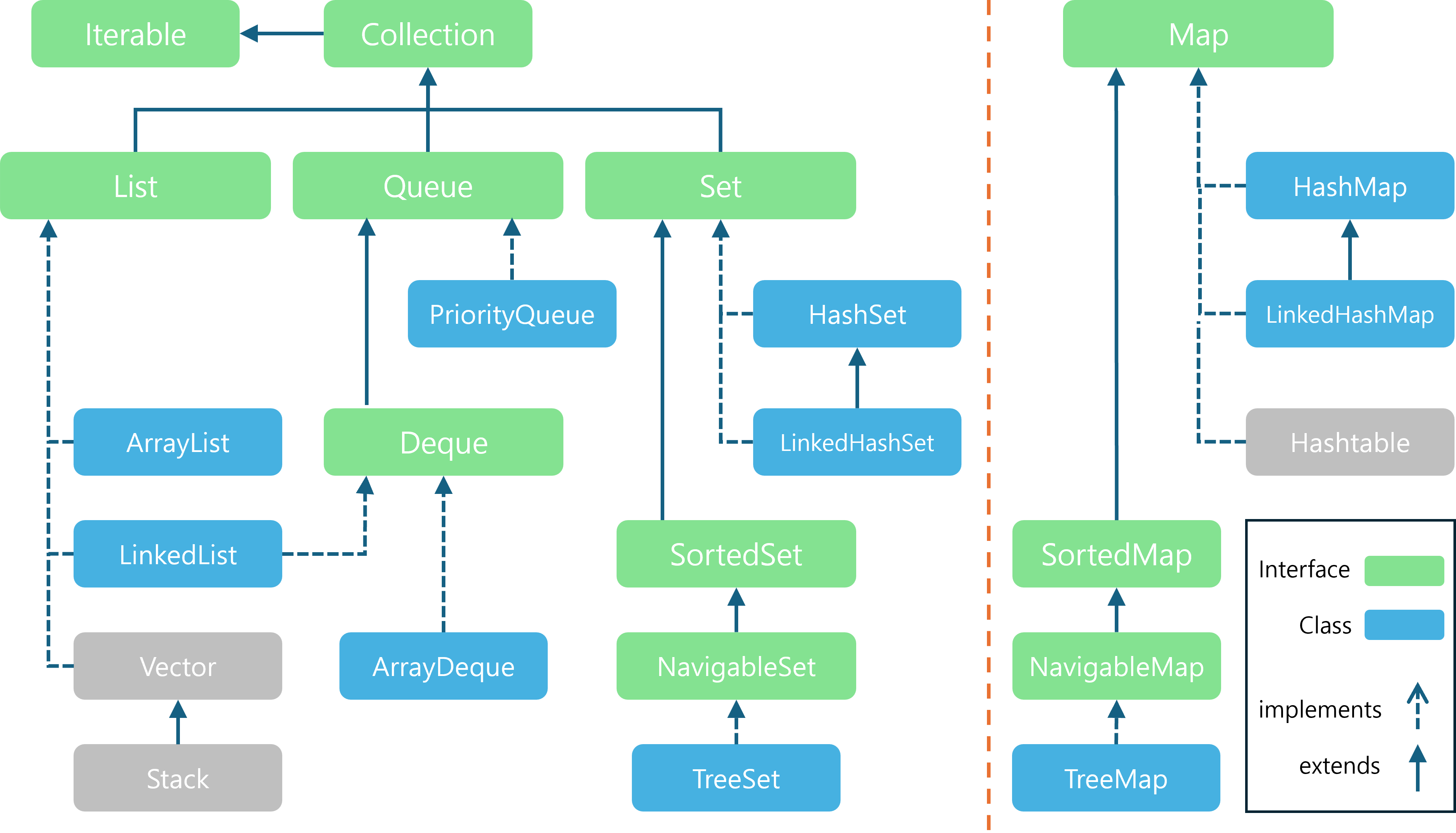
Java에서는 여러 가지 해시 기반 자료구조를 제공하며, 각 구현체는 고유한 특징과 사용 목적을 가지고 있습니다.
HashSet,HashMap,LinkedHashSet,LinkedHashMap은 자바에서 가장 많이 사용되는 해시 테이블 구현체들로, 해시 함수를 사용해 데이터를 빠르게 관리할 수 있는 장점이 있습니다.
그림에 보이는
Hashtable은 뭔가요?
Hashtable은 Java의 초기 버전부터 존재했던 해시 테이블 구현체로, 키와 값을 키-값 쌍으로 저장하는 자료구조입니다.- 하지만 최근의 Java 개발에서는
HashMap이 Hashtable을 대체하면서 거의 사용되지 않는 Legacy 클래스가 되었습니다. (하위 버전 호환용으로 남겨진 클래스라 보시면 됩니다)- 그럼에도 불구하고,
Hashtable을 여전히 사용 중인 레거시 시스템이 많기 때문에 이 클래스를 이해하고 있을 필요가 있습니다. 밑에서 부록으로 간단히 다루겠습니다.
1.1 HashSet
- 특징:
HashSet은 고유한 값을 저장하는 집합(Set) 자료구조입니다. 내부적으로HashMap을 사용해 구현되며, 중복을 허용하지 않습니다. - 용도: 중복되지 않는 고유한 요소들을 저장하고 싶을 때 사용합니다.
- 동작 방식: 값은
HashMap의 키(Key)로 저장되며, 값의 유일성을 해시 코드를 통해 보장합니다.
import java.util.HashSet;
public class HashSetExample {
public static void main(String[] args) {
HashSet<String> set = new HashSet<>();
set.add("apple");
set.add("banana");
set.add("apple"); // 중복된 값은 추가되지 않음
System.out.println(set); // [banana, apple]
}
}1.2 HashMap
- 특징:
HashMap은 키-값(Key-Value) 쌍을 저장하는 해시 테이블입니다. 각 키(Key)는 고유해야 하며, 키를 해시 함수로 변환하여 해시 인덱스로 데이터를 저장하고 검색합니다.- 내부적으로 Entry라는 구조를 사용하여 키와 값의 쌍을 저장합니다. Entry는 각각의 키-값 쌍을 저장하고, 같은 해시 인덱스에서 충돌이 발생하면 연결리스트로 이어집니다.
- 용도: 고유한 키에 매핑되는 값을 저장하고 검색할 때 사용합니다.
- 동작 방식: 내부적으로 연결리스트를 통해 Separate Chaining 방식으로 해시 충돌을 처리하며, Java 8 이후에는 충돌이 심한 경우 연결리스트를 트리 구조로 전환하여 탐색 성능을 향상시킵니다.
import java.util.HashMap;
public class HashMapExample {
public static void main(String[] args) {
HashMap<String, Integer> map = new HashMap<>();
map.put("apple", 10);
map.put("banana", 20);
System.out.println(map.get("apple")); // 10 출력
System.out.println(map); // {apple=10, banana=20}
}
}1.3 LinkedHashSet
- 특징:
LinkedHashSet은HashSet과 비슷하지만, 삽입된 순서를 유지하는 자료구조입니다. - 용도: 중복을 허용하지 않으면서도 삽입 순서를 유지해야 할 때 사용합니다.
- 동작 방식: 데이터가 추가될 때마다 기존 데이터와의 링크 연결을 통해 삽입된 순서를 기억하게 됩니다. (즉, 데이터를 연결리스트처럼 연결한 방식이라 보시면 됩니다)
1.4 LinkedHashMap
- 특징:
LinkedHashMap은HashMap과 비슷하지만, 삽입된 순서 또는 최근 접근된 순서로 데이터를 저장하고 유지합니다. 주로 LRU 캐시(Least Recently Used Cache)와 같은 자료구조를 구현할 때 유용합니다. - 용도: 순서가 중요한 키-값 저장소가 필요할 때 사용합니다.
- 동작 방식: 데이터가 추가될 때마다 기존 데이터와의 링크 연결을 통해 삽입된 순서를 기억하게 됩니다. (즉, 데이터를 연결리스트처럼 연결한 방식이라 보시면 됩니다)
1.부록: Legacy 클래스 Hashtable
Hashtable은 Java의 초기 버전에서부터 제공된 해시 테이블 구현체로, 키와 값을 키-값 쌍으로 저장하는 자료구조입니다.
- 하지만 최근의 Java 개발에서는
HashMap이 이를 대체하면서 거의 사용되지 않으며, 레거시 클래스로 간주됩니다. 그럼에도 불구하고 여전히 일부 레거시 시스템에서 Hashtable을 사용하는 경우가 있기 때문에 어느정도는 이해하는 것이 좋습니다.
주요 차이점
- 스레드 안전성:
Hashtable은 메서드가synchronized로 구현되어 있어 스레드 안전하지만, 동기화가 과도하게 이루어지면 성능이 저하될 수 있습니다. 반면,HashMap은 스레드 안전하지 않지만 성능이 더 우수합니다. - Null 허용 여부:
Hashtable은 null 키와 null 값을 허용하지 않습니다. 반면,HashMap은 null 키와 null 값을 허용합니다.
import java.util.Hashtable;
public class HashtableExample {
public static void main(String[] args) {
Hashtable<String, Integer> table = new Hashtable<>();
table.put("apple", 10);
table.put("banana", 20);
// Null 값 허용하지 않음
// table.put(null, 30); // NullPointerException 발생
// table.put("orange", null); // NullPointerException 발생
System.out.println(table.get("apple")); // 10 출력
}
}결론
현재 대부분의 개발에서는 Hashtable 대신 HashMap이 사용되며, 동시성 처리가 필요한 경우에는 ConcurrentHashMap을 사용하는 것이 좋습니다.
Hashtable은 레거시 시스템과의 호환성을 위해 남겨진 클래스이므로, 새로운 코드에서는 사용을 피하는 것이 좋습니다.
2. Java 해시테이블의 충돌 해결 원리
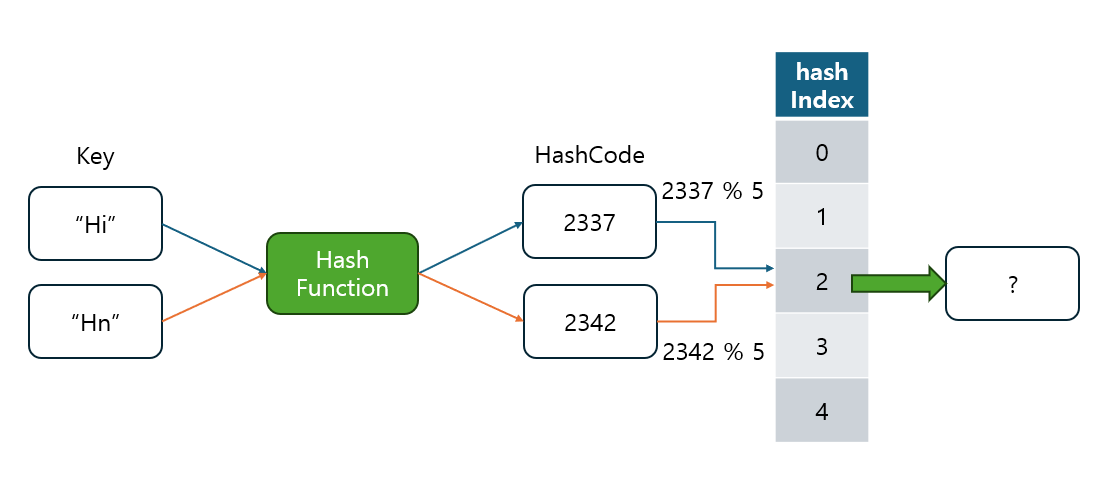
해시 테이블은 데이터를 효율적으로 저장하고 검색할 수 있는 자료구조이지만, 해시 충돌이라는 문제가 발생할 수 있습니다.
- 이는 서로 다른 두 개 이상의 키가 동일한 해시 인덱스를 가질 때 발생합니다.
- Java에서는 이러한 충돌을 해결하기 위해 Separate Chaining(개별 체이닝) 방식을 사용하며, Java 8 이후에는 성능 최적화를 위해 레드-블랙 트리로 전환하는 기법을 도입했습니다.
2.1 Separate Chaining(개별 체이닝)
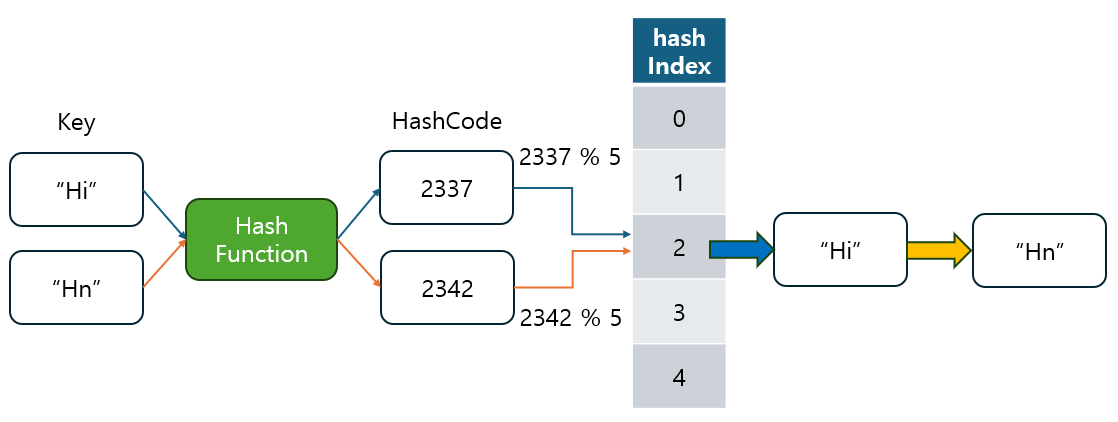
- 개념: 해시 충돌이 발생하면 동일한 해시 인덱스에 저장된 데이터를 연결리스트(Linked List) 형태로 관리하는 방식입니다.
- 이때
HashMap의 버킷은Entry객체를 통해 키-값 쌍을 저장하며, 같은 인덱스에 충돌이 발생하면 이 Entry들이 연결리스트로 연결됩니다.- 각
Entry객체는 키, 값, 그리고 다음 Entry를 가리키는 next 포인터를 가집니다.
- 각
- 이때
- 특징: 충돌이 발생해도 연결리스트의 끝에 데이터를 추가하기 때문에 테이블 크기와 무관하게 데이터를 관리할 수 있습니다.
- Java의 구현: Java의
HashMap은 기본적으로 Separate Chaining 방식을 사용하여 해시 충돌을 처리합니다.- 각 버킷(bucket)은 연결리스트로 관리되며, 동일한 해시 인덱스를 가진 여러 개의 키가 있을 경우 해당 리스트에
Entry객체들이 연결됩니다.
- 각 버킷(bucket)은 연결리스트로 관리되며, 동일한 해시 인덱스를 가진 여러 개의 키가 있을 경우 해당 리스트에
2.2 Java 8의 최적화: 레드-블랙 트리로 전환
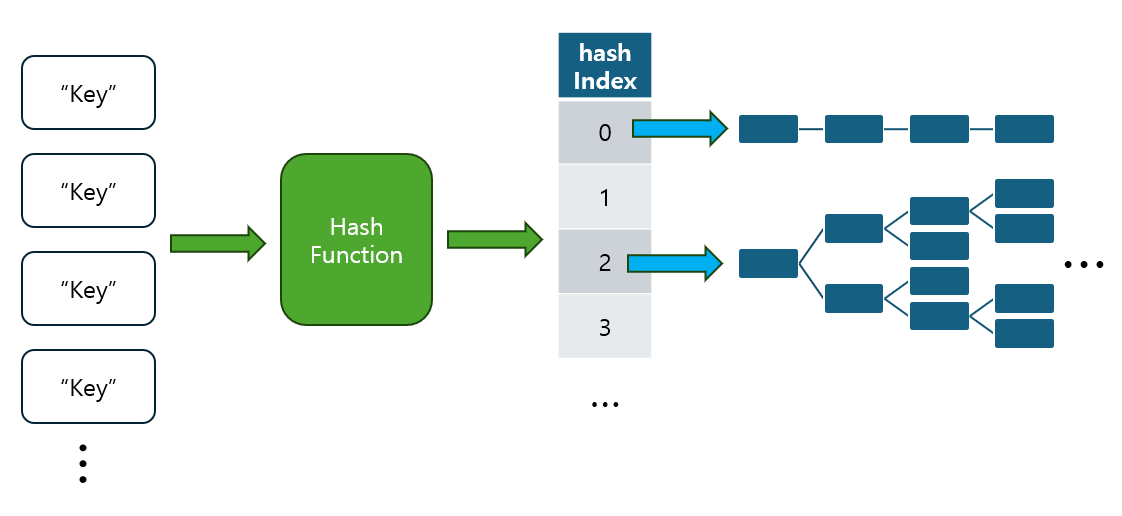
- 문제: 해시 충돌이 빈번하게 발생할 경우, 연결리스트의 길이가 길어져 탐색 성능이 저하될 수 있습니다.
- 연결리스트는 최악의 경우 O(n)의 탐색 시간이 소요될 수 있습니다.
- 해결책: Java 8부터는 한 버킷에 저장된 엔트리의 수가 일정 개수(기본적으로 8개)를 넘어서면 연결리스트 대신 레드-블랙 트리(Red-Black Tree)로 전환하여 성능을 향상시킵니다.
- 트리는 O(log n) 시간 복잡도로 검색과 삽입을 처리할 수 있어 성능 저하를 방지합니다. (트리는 비선형 자료구조로 이후 포스팅에서 다룰 예정입니다)
- 레드-블랙 트리는 자체적으로 균형을 유지하는 특성이 있어서 O(log n)의 탐색 성능을 유지하게 됩니다.
- 조건: 버킷 내의 데이터가 많아져 연결리스트의 길이가 8개를 넘을 경우 트리로 전환되며, 반대로 6개 이하로 줄어들면 다시 리스트로 전환됩니다.
- 이러한 트리 전환 방식은 Java 8 이후 성능 최적화의 중요한 요소입니다.
- 참고로
HashSet에서는 이러한 방식이 적용되지 않고,HashMap에서만 이러한 방식으로 최적화가 이루어 집니다.
3. Java 해시테이블의 성능 최적화
3.1 해시 함수의 품질
- 해시 함수의 역할: 해시 함수는 데이터를 고정된 크기의 숫자로 변환하여, 해시 테이블의 인덱스에 매핑하는 중요한 역할을 합니다.
- 해시 함수가 균일하게 데이터를 분배하지 못하면 충돌이 자주 발생해 성능이 저하될 수 있습니다.
- 좋은 해시 함수의 조건:
- 균일성: 입력 데이터에 따라 고르게 분포된 해시 값을 생성하여 충돌을 최소화합니다.
- 효율성: 해시 함수는 적은 시간 안에 해시 값을 생성할 수 있어야 합니다.
Java에서의 기본 해시 함수
- 모든 Java 객체는
Object.hashCode()메서드와Object.equals()를 상속받아 해시 코드를 생성할 수 있습니다. - 기본적으로
String,Integer,Long등 자바에서 자주 사용되는 클래스들은 이 메서드를 자체적으로 오버라이드하여 효율적인 해시 코드를 생성합니다.- 예를 들어,
String클래스는 문자열의 각 문자를 기반으로 해시 코드를 계산합니다.
- 예를 들어,
String의 hashCode() 예시
public int hashCode() { int h = 0; for (int i = 0; i < length(); i++) { h = 31 * h + charAt(i); // 각 문자의 유니코드를 사용해 해시값 생성 } return h; }
사용자 정의 객체에서의 hashCode()와 equals() 구현
사용자가 정의한 객체에서도 hashCode()와 equals()를 올바르게 오버라이드하는 것이 중요합니다.
- 해시 테이블 기반 자료구조(예: HashMap, HashSet)는 키의 고유성과 일관성을 보장하기 위해 두 메서드를 활용합니다.
hashCode()와equals()메서드는 항상 일관성을 유지해야 합니다.- 일관성 원칙:
equals()가true인 두 객체는 반드시 같은hashCode()값을 반환해야 합니다. 반대로,equals()가false를 반환하는 객체들은 해시 코드가 달라도 괜찮습니다.
- 일관성 원칙:
hashCode()와 equals()를 오버라이드하는 예시
public class Person {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public int hashCode() {
// name과 age를 조합하여 고유 해시코드를 생성
return 31 * name.hashCode() + Integer.hashCode(age);
}
@Override
public boolean equals(Object obj) {
if (this == obj) return true;
if (obj == null || getClass() != obj.getClass()) return false;
Person person = (Person) obj;
return age == person.age && name.equals(person.name);
}
}-
hashCode()의 설계 원칙:
- 일관성: 프로그램 실행 중 동일한 객체에서
hashCode()를 여러 번 호출해도 항상 동일한 값을 반환해야 합니다. 단, 객체의 내부 상태가 변하지 않는 경우에 한합니다. - 균일한 분포: 서로 다른 객체들이 가능한 한 균일하게 해시 코드 값이 분포되어야 합니다.
- 해시 값이 고르게 분포되지 않으면 특정 해시 버킷에 데이터가 몰리게 되고, 충돌이 발생하여 해시 테이블의 성능이 저하됩니다.
- 빠른 계산: 해시 함수는 가능한 한 빠르게 계산되어야 하며, 복잡한 연산을 피하는 것이 좋습니다.
- 일관성: 프로그램 실행 중 동일한 객체에서
-
좋은 해시 함수의 예시:
- 위에서 언급한
String.hashCode()는 문자열의 각 문자를31로 곱하여 더하는 방식으로, 효율적이고 균일한 해시 값을 생성하는 좋은 예시입니다.31은 홀수이며 소수이기 때문에 충돌을 줄이고 계산이 빠릅니다. - Prime Number(소수)를 이용한 해시 함수는 충돌을 줄이는 데 유리합니다.
hashCode()구현 시 소수를 곱하는 이유는 해시 코드 값이 균일하게 분포되도록 도와주기 위함 입니다.
- 위에서 언급한
3.2 Load Factor와 Resizing
- Load Factor(부하 인수): 해시 테이블의 채워진 버킷의 비율을 나타내는 값으로, 해시 테이블이 리사이징(resizing)을 할 시점을 결정하는 중요한 요소입니다.
- Java
HashMap의 기본 Load Factor는 0.75입니다. - 즉, 테이블의 75%가 채워지면 테이블의 크기가 두 배로 늘어나고, 데이터를 다시 해시하여 새로운 테이블에 분배합니다.
- Java
- Resizing(재해싱) 과정:
- 재해싱은 해시 테이블이 포화 상태가 되었을 때, 기존의 버킷 크기를 늘리고 데이터를 다시 해시하여 새로운 해시 인덱스로 분배하는 과정입니다.
- Resizing은 메모리와 성능 측면에서 부담이 될 수 있지만, 너무 높은 Load Factor는 충돌 빈도를 증가시키고 성능을 저하시킬 수 있으므로 적절한 Load Factor 설정이 필요합니다.
- 성능 측면에서의 trade-off:
- Load Factor가 낮으면 빈 버킷이 많아져 메모리 낭비가 발생하지만 충돌이 줄어들어 성능이 좋아집니다.
- 반면, Load Factor가 높으면 메모리 효율은 높아지지만 충돌이 증가할 수 있습니다.
예시 코드: Load Factor 조절
import java.util.HashMap;
public class LoadFactorExample {
public static void main(String[] args) {
// 초기 용량(capacity)을 16, Load Factor를 0.5로 설정한 HashMap 생성
HashMap<String, Integer> map = new HashMap<>(16, 0.5f); // Load Factor 0.5
// 키-값 쌍을 맵에 삽입
for (int i = 0; i < 20; i++) {
map.put("Key" + i, i); // "Key0"부터 "Key19"까지의 키-값 쌍을 삽입
}
// Load Factor가 0.5이므로, 16 * 0.5 = 8개 이상 데이터를 삽입하면 리사이징 발생
System.out.println("Map size with load factor 0.5: " + map.size()); // 맵 크기 출력
}
}
new HashMap<>(16, 0.5f)에서 16은 초기 용량(capacity)이고,0.5f는 Load Factor입니다.- Load Factor가 0.5이므로, 해시 테이블의 버킷이 50% 이상 채워지면 자동으로 크기가 두 배로 리사이징됩니다.
- 즉, 초기 용량이 16이므로 8개 이상의 데이터를 삽입하면 리사이징이 발생합니다.
- 반복문을 통해 데이터를 삽입하다가 8번째 데이터가 삽입되면 Load Factor 기준(0.5)에 도달하게 되어 리사이징(Resizing)이 일어납니다.
- 그 결과, HashMap의 용량이 16에서 32로 늘어나고, 기존 데이터는 새로운 버킷으로 다시 해시됩니다.
map.size()는 HashMap에 저장된 키-값 쌍의 총 개수를 반환합니다.- 여기선 이 값이
20으로 출력됩니다. 중요한 점은, 리사이징 과정이 발생했지만 데이터는 정상적으로 저장되며 HashMap은 데이터 손실 없이 처리된다는 것입니다.
- 여기선 이 값이
4. Java 해시 테이블 구현체 비교
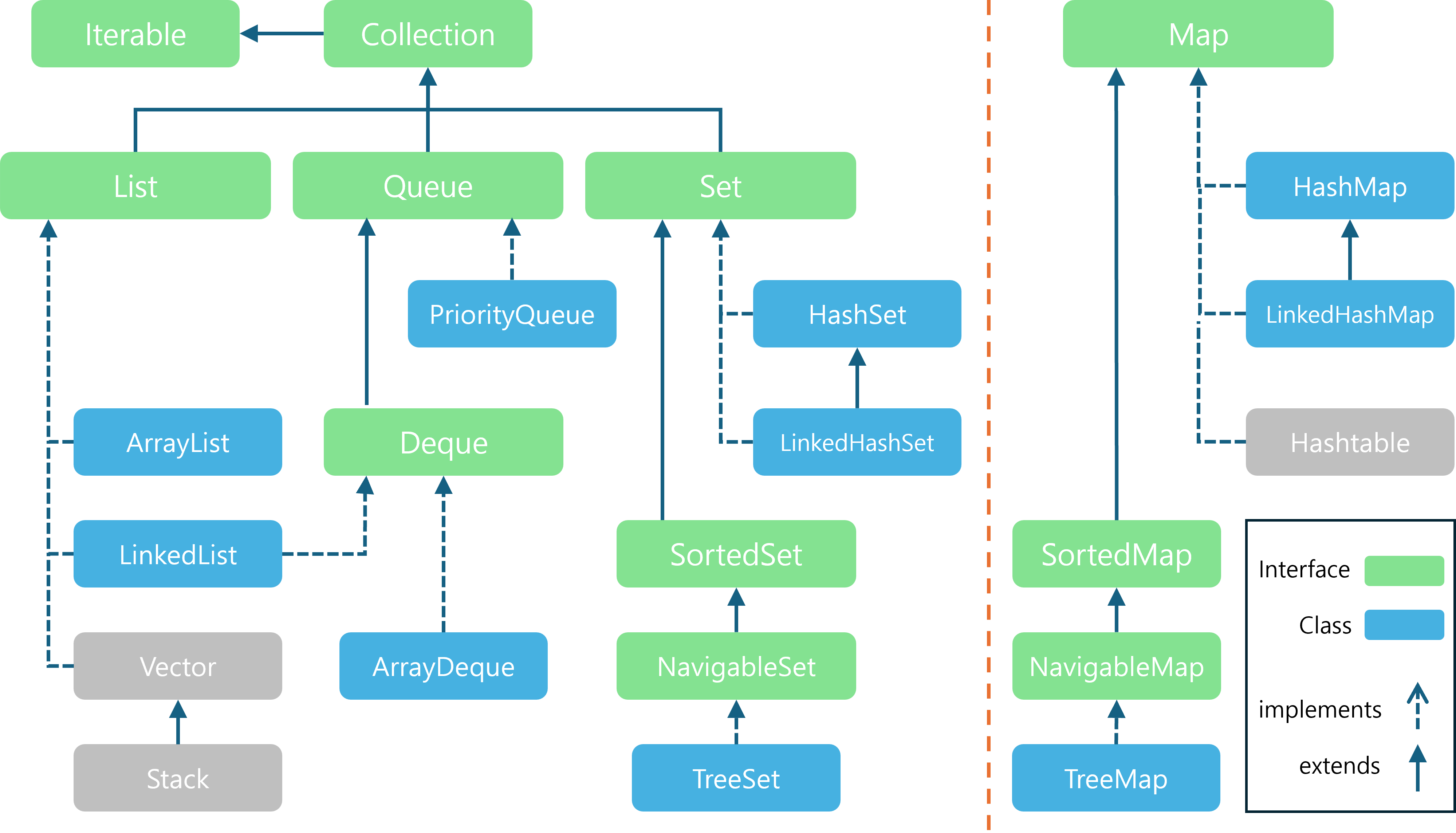
Java에는 여러 가지 해시 테이블 기반 자료구조가 존재합니다. 이들 구현체는 각기 다른 용도와 특성을 가지며, 상황에 따라 적합한 자료구조를 선택해야 합니다.
- 이 섹션에서는
HashSet,HashMap,LinkedHashSet,LinkedHashMap을 비교하여, 각각의 특성과 사용 사례에 대해 다루어 보겠습니다.
4.1 주요 구현체 비교표
| 구현체 | 특징 | 순서 보장 여부 | Null 허용 여부 | 충돌 해결 방식 | 용도 |
|---|---|---|---|---|---|
| HashSet | 고유한 값만 저장 (내부적으로 HashMap 사용) | X | Null 값 1개 허용 | Separate Chaining | 중복 없이 값을 저장할 때 |
| HashMap | 키-값 쌍으로 저장, 빠른 조회 가능 | X | Null 키 1개 허용, (Null 값은 제한X) | Separate Chaining, 트리 전환 (Java 8) | 빠른 검색이 필요한 경우 (키-값 저장소) |
| LinkedHashSet | HashSet과 동일, 삽입된 순서 유지 | O | Null 값 1개 허용 | Separate Chaining | 중복 없는 값 저장 + 순서 보장이 필요할 때 |
| LinkedHashMap | HashMap과 동일, 최근 접근된 순서 유지 | O | Null 키 1개 허용, (Null 값은 제한X) | Separate Chaining, 트리 전환 (Java 8) | 캐시 구현(LRU), 순서가 중요한 경우 |
참고: 트리 전환은
Set구현체(HashSet,LinkedHashSet)에는 적용되지 않습니다.
- 트리 전환 최적화는 해시 충돌을 줄이고 성능을 높이기 위해
HashMap및LinkedHashMap에서만 적용됩니다.Set구현체는 고유한 값만을 저장하고, 별도의 트리 전환 없이 체이닝 방식으로 충돌을 처리합니다.
4.2 레거시 클래스 Hashtable 비교
- Hashtable은 Java 초기 버전에서부터 제공된 해시 테이블 구현체로, 키-값 쌍을 저장하며 스레드 안전성을 보장합니다.
- 하지만
Hashtable은 현재 레거시 클래스로 간주되며, 일반적으로는 HashMap으로 대체되었습니다.
- 하지만
Hashtable은 HashMap과 다음과 같은 차이점이 있습니다:- 스레드 안전성:
Hashtable은 메서드가synchronized로 구현되어 있어 스레드 안전합니다. 하지만, 이로 인해 성능이 저하될 수 있습니다.- 반면,
HashMap은 스레드 안전성을 제공하지 않으므로 더 빠른 성능을 제공합니다. - 그래서 스레드 안전한 해시 테이블이 필요할 경우 ConcurrentHashMap을 사용하는 것이 더 적합합니다.
- 반면,
- Null 허용 여부:
Hashtable은 null 키와 null 값을 허용하지 않습니다. 반면,HashMap은 null 키 1개와 null 값 여러 개를 허용합니다. - 성능 및 활용:
Hashtable은 동기화로 인한 성능 저하가 발생할 수 있으며, 새로운 코드에서는 주로 HashMap이나 ConcurrentHashMap이 사용됩니다.
- 스레드 안전성:
4.3 구현체 선택 가이드
- 중복이 없는 값 관리:
- HashSet: 순서가 중요하지 않고, 중복 없이 데이터를 저장하고 빠르게 검색할 때 사용.
- LinkedHashSet: 중복 없이 값을 저장하면서 삽입 순서를 기억해야 할 때 사용.
- 키-값 저장 및 검색:
- HashMap: 데이터를 키-값 쌍으로 빠르게 저장하고 검색해야 할 때 가장 일반적으로 사용되는 자료구조.
- LinkedHashMap: 삽입 순서나 최근 접근 순서가 중요한 경우 사용.
- 특히, LRU 캐시 같은 시스템에서 유용.
- 성능과 순서 유지의 트레이드오프:
HashMap과LinkedHashMap:LinkedHashMap은 삽입 순서를 유지해야 하는 상황에서 사용되고, 다만 메모리 사용량이 증가할 수 있지만 대체로 성능 차이가 크지는 않습니다.
- 레거시 시스템에서의 사용:
- Hashtable: 기존의 레거시 시스템이나 스레드 안전이 필요한 경우
Hashtable이 사용되지만, 최신 코드에서는 HashMap이나 ConcurrentHashMap을 사용하는 것이 더 적합합니다.
5. Java 해시테이블의 주요 메서드 및 복잡도
5.1 Set 구현체의 주요 메서드
Set 인터페이스를 구현하는 HashSet, LinkedHashSet의 주요 메서드를 정리합니다.
| 메서드 | 설명 | 시간 복잡도 |
|---|---|---|
| add(E e) | 주어진 값을 집합에 추가합니다. 중복된 값은 추가되지 않습니다. | O(1) |
| remove(Object o) | 주어진 값을 집합에서 제거합니다. | O(1) |
| contains(Object o) | 해당 값이 집합에 존재하는지 여부를 반환합니다. | O(1) |
| size() | 집합에 저장된 요소의 개수를 반환합니다. | O(1) |
| isEmpty() | 집합이 비어 있는지 여부를 반환합니다. | O(1) |
5.2 Map 구현체의 주요 메서드
Map 인터페이스를 구현하는 HashMap, LinkedHashMap, Hashtable의 주요 메서드를 정리합니다.
| 메서드 | 설명 | 시간 복잡도 |
|---|---|---|
| put(K key, V value) | 주어진 키와 값을 맵에 추가합니다. 키가 이미 존재하면 값을 덮어씁니다. | O(1) |
| get(Object key) | 주어진 키에 대응하는 값을 반환합니다. 존재하지 않으면 null을 반환합니다. | O(1) |
| remove(Object key) | 주어진 키에 대응하는 값을 맵에서 제거합니다. | O(1) |
| containsKey(Object key) | 주어진 키가 맵에 존재하는지 여부를 반환합니다. | O(1) |
| containsValue(Object value) | 주어진 값이 맵에 존재하는지 여부를 반환합니다. | O(n) |
| size() | 맵에 저장된 키-값 쌍의 개수를 반환합니다. | O(1) |
| isEmpty() | 맵이 비어 있는지 여부를 반환합니다. | O(1) |
5.3 각 구현체의 시간복잡도 및 공간 복잡도
각 Set과 Map 구현체의 시간 복잡도와 공간 복잡도를 비교하면 다음과 같습니다.
| 구현체 | 추가(삽입) | 삭제 | 검색 | 공간 복잡도 |
|---|---|---|---|---|
| HashSet | O(1) | O(1) | O(1) | O(n) - 저장된 값과 충돌된 요소 저장 |
| LinkedHashSet | O(1) | O(1) | O(1) | O(n) - 순서 유지 위한 추가 공간 사용 |
| HashMap | O(1) | O(1) | O(1) | O(n) - 저장된 키-값 쌍 저장 |
| LinkedHashMap | O(1) | O(1) | O(1) | O(n) - 순서 유지 위한 추가 공간 사용 |
| Hashtable | O(1) | O(1) | O(1) | O(n) - 스레드 안전성 위한 추가 자원 사용 |
마무리
이번 포스팅에서는 Java에서 제공하는 다양한 해시 테이블 구현체들인 HashSet, HashMap, LinkedHashSet, LinkedHashMap을 중심으로 각각의 특징, 동작 방식, 그리고 주요 메서드와 성능 최적화 기법들을 살펴보았습니다.
해시 테이블은 데이터의 빠른 저장과 검색을 가능하게 해주는 매우 강력한 자료구조입니다.
- 특히 Java에서는 각각의 요구 사항에 맞춰 다양한 구현체를 제공하며, 이를 통해 우리는 중복 없는 데이터 저장, 순서 보장, 빠른 검색, 스레드 안전성 등 다양한 시나리오에서 최적화된 방법을 선택해 사용할 수 있습니다.
포스팅에서 다룬 바와 같이 해시 충돌 문제는 해시 테이블의 주요 과제 중 하나입니다.
- Java 8부터 도입된 트리 전환 기법과 같은 최적화는 이러한 충돌 문제를 해결하는 데 큰 도움을 줍니다.
- 또한, Separate Chaining 방식을 통해 효율적으로 해시 충돌을 처리하는 원리도 살펴보았습니다.
마지막으로, Hashtable과 같은 레거시 클래스와 ConcurrentHashMap과 같은 스레드 안전한 대안까지 언급하며 다양한 선택지를 소개했습니다.
- 새로운 프로젝트에서는 주로
HashMap을 사용하고, 스레드 안전이 필요한 상황에서는ConcurrentHashMap을 사용하는 것이 바람직하다는 점도 다루었습니다.
다음 포스팅에서는 Python에서의 해시 테이블 구현체, 즉 딕셔너리(dictionary)와 셋(set) 관련 자료구조들을 다룰 예정입니다.
- Python에서는 해시 테이블을 기반으로 한 자료구조가 어떻게 설계되어 있으며, Java와 어떤 차이점이 있는지 살펴보게 됩니다.
- 또한, Open Addressing(개방 주소 방식)을 통한 충돌 해결 방법도 Python에서의 활용 사례와 함께 설명드릴 예정입니다.
