서울시 월별 기상정보로 서울시 식중독 발생 환자 수를 예측하는 프로그램 Seoul FP-Weather 개발 프로젝트 진행과정 정리 및 회고. (2) 회귀모델(LightGBM) 모델링 과정

Seoul FP-Weather
- Github Repository 바로가기 : Seoul FP-Weather (클릭)
- App link = Seoul-FP-Weather (Koyeb 배포)
- 예측 모델 정상 작동 확인 완료
- Heroku를 통해 배포하였으나 2022년 11월 28일부터 Heroku 무료 요금제는 더 이상 제공되지 않으므로 Koyep을 통해 재배포 실시
(2023 수정사항)
- 기존의 프로그램의 경우 Heroku를 통해서 배포를 진행했었으나, heroku 정책상 2022년 11월 28일부터 Heroku 무료 요금제는 더 이상 제공되지 않기 때문에 Application Error가 발생함.
- 이에 Heroku와 동일하게 Gihub Repository 연동 방식이 가능한 Koyeb을 통해 재배포를 진행하였음.
- 재배포한 웹사이트에서 예측 모델이 정상적으로 구동됨을 확인 완료함.
- 대체 링크를 추가하여 수정사항을 반영하였음.
서울시 월별 날씨기반
식중독 환자수 예측
Seoul Food-Posisoning
Prediction by Weather

-
서울시 월간 기상정보를 기반으로 서울시 월간 식중독 발생 환자 수를 예측하는 AI 머신 러닝 프로그램
-
Tech Stack

00. 프로젝트 개요
필수 포함 요소
자유주제로데이터 파이프라인 구축및API 서비스 개발- 데이터베이스 구축 (
Pull&Store) - API 서비스 개발 (
Machine Learning&Frond-end) - 데이터 분석용
대시보드개발 및 배포
프로젝트 목차
- Introduction
서론- Food-Poisoning
식중독 - Seoul FP-Weather
프로그램소개
- Food-Poisoning
- Database
데이터베이스- Data Pipeline
파이프라인 - Database
DB구축
- Data Pipeline
- Modeling
모델링- Data Import
데이터 불러오기 - Regression Modeling
회귀 모델 - Object Encoding
객체 부호화
- Data Import
- Deployment
배포- Prediction
평년값 예측 - Dashboard
대시보드 - Web Deployment
웹 배포
- Prediction
- Conclusion
결론- Applications
활용방안 - Limitations
한계점 - Takeaway
핵심, 느낀점
- Applications
Data Pipeline
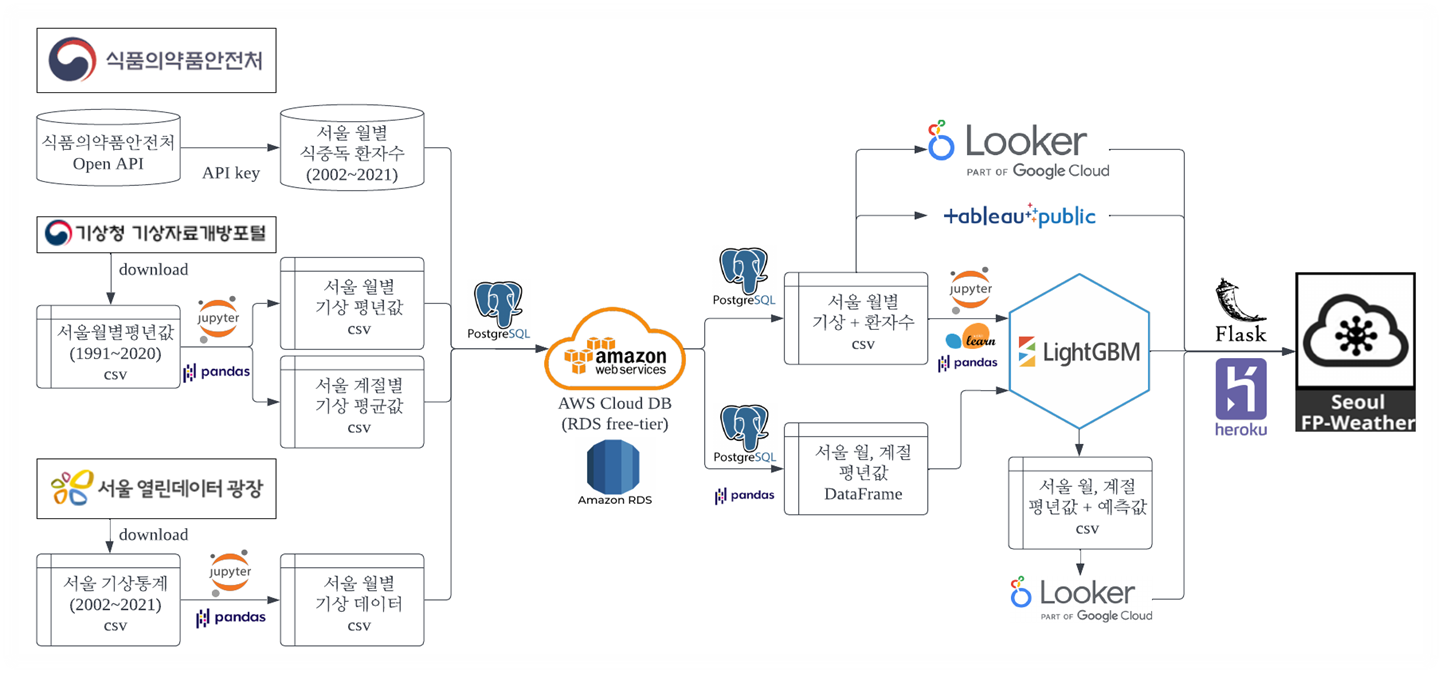
03. Modeling 모델링
3-1. Data Import 데이터 불러오기
로컬 데이터베이스
- DB 관리 시스템은 PostgreSQL을 이용
- python의 psycopg2 라이브러리를 통해 로컬환경과 DB를 연결
- 서울 월별 기상자료 + 서울 월별 식중독 환자 수
- SQL INNER JOIN을 통해 데이터를 병합하여 머신러닝 및 대시보드에 이용
- 월별, 계절별 평년값
- pandas 라이브러리로 DataFrame형식으로 불러와 예측 및 대시보드에 이용
- 다음 포스팅에서 자세히 다룰 예정
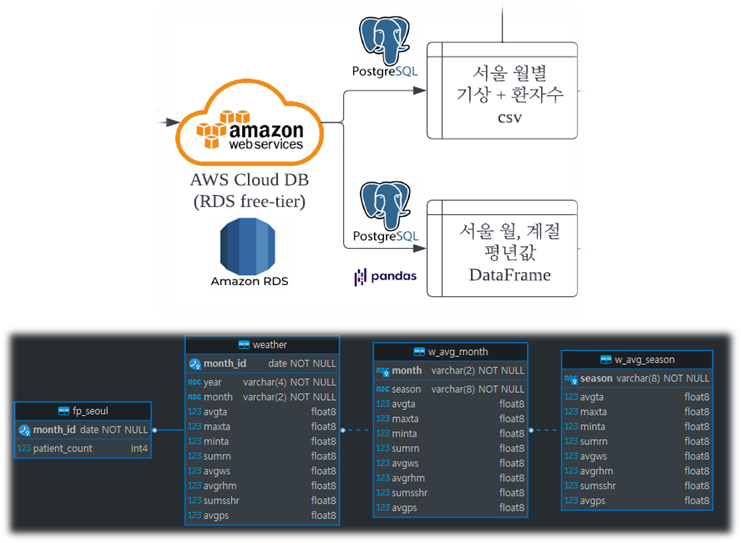
머신러닝 데이터 준비 (SQL -> csv)
- 서울 월별 기상자료 + 서울 월별 식중독 환자 수
# 라이브러리 import
import os
import sys
import csv
import psycopg2
from dotenv import load_dotenv
#PostgreSQL 연결정보를 변수로 저장
load_dotenv(verbose=True)
HOST = os.getenv('postgre_host')
PASSWORD = os.getenv('postgre_password')
DATABASE = 'postgredb'
USERNAME = 'kjcheong'
PORT = 5432
#파일 실행시 작동하는 함수안에 과정을 모두 포함
def main():
# postgreSQL 연결
try:
conn = psycopg2.connect(
host=HOST,
port=PORT,
database=DATABASE,
user=USERNAME,
password=PASSWORD)
cur = conn.cursor()
print('connection success to DB')
except:
print('connection failure to DB')
sys.exit()
# JOIN QUERY
sql_query_join = """
SELECT w."year" , w."month" , w.avgta , w.maxta , w.minta , w.sumrn , w.avgws , w.avgrhm , w.sumsshr , w.avgps , fs2.patient_count
FROM weather w
JOIN fp_seoul fs2
ON w.month_id = fs2.month_id
"""
# to csv
sql_csv = f"""COPY ({sql_query_join}) TO STDOUT WITH CSV DELIMITER ',';"""
with open("./data/csv/fp-weather.csv", "w") as cf:
cur.copy_expert(sql_csv, cf)
conn.close()
print('"fp-weather.csv" file created')
#파일 실행시 함수 실행 명령
if __name__ == "__main__":
main()# $ python data/postgresql-2-join-to-csv.py
'''
connection success to DB
"fp-weather.csv" file created
'''3-2. Regression Modeling 회귀 모델
- 기상 정보를 통해 식중독 환자수를 예측하기 위해 회귀분석(Regression)을 실시
- 훈련데이터 : 테스트데이터 = 3 : 1
- 특성, 타겟
- 특성 : 서울 월간기상정보 주요요소 8개
(평균기온, 최고기온, 최저기온, 강수량, 평균풍속, 상대습도, 일조시간, 해면기압) - 타겟 : 서울 월간 식중독 발생 환자 수
- 특성 : 서울 월간기상정보 주요요소 8개
- 회귀모델은 부스팅계열의 LightGBM으로 선정하여 진행
- LightGBM 특징 : 속도가 빠름, 준수한 성능
- 평가지표 : RMSE(Root Mean Square Error), MAE(Mean Absolute Error)
- 오차의 단위가 같은 RMSE와 MAE를 평가지표로 선정
- 모델링은 RMSE를 위주로 진행되었음.

- 모델링은 Jupyter Notebook을 통해 진행되었음.
STEP0. Library import 라이브러리 호출
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['axes.unicode_minus'] = False
import seaborn as sns
#머신러닝
import lightgbm as lgbm
from lightgbm import early_stopping, log_evaluation
from sklearn.metrics import mean_squared_error, mean_absolute_error
from sklearn.model_selection import train_test_split
#객체 부호화
import pickleSTEP1. Data Import 데이터 불러오기
- SQL을 통해 가져온 데이터는 column에 대한 정보가 없으므로 컬럼명 지정
columns0 = ['year','month','avgTa','maxTa','minTa','sumRn','avgWs','avgRhm','sumSsHr','avgPs','fp_patients']
df0 = pd.read_csv('csv/fp-weather.csv', names=columns0)
df0.head()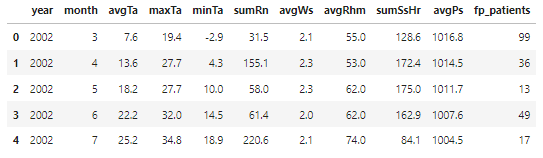
- 대시보드 제작에 쓰기 위해 csv로 저장해두기
df0.to_csv('csv/fp-weather-add-column.csv',index=False)- year, month 컬럼 제외
columns1 = ['avgTa','maxTa','minTa','sumRn','avgWs','avgRhm','sumSsHr','avgPs','fp_patients']
df1 = df0[columns1]
df1.head()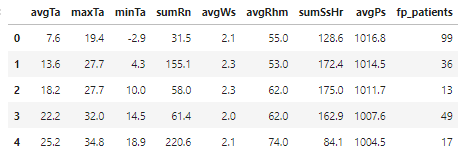
- 중복 및 결측치 확인
print('Sum of Duplicated Data : {}'.format(df1.duplicated().sum()))
print('Sum of Null Data : {}'.format(df1.isnull().sum().sum()))
'''
Sum of Duplicated Data : 0
Sum of Null Data : 0
'''STEP2. 데이터 분리
- 훈련, 테스트셋 분리
train, test = train_test_split(df1, test_size=0.25, random_state=42)
print('분리전 데이터 : {}\n'.format(df1.shape))
print('훈련 데이터 : {}'.format(train.shape))
print('테스트 데이터 : {}'.format(test.shape))
'''
분리전 데이터 : (208, 9)
훈련 데이터 : (156, 9)
테스트 데이터 : (52, 9)
'''- 특성, 타겟 분리
target = 'fp_patients'
features = df1.columns.drop(target)
X_train = train[features]
y_train = train[target]
X_test = test[features]
y_test = test[target]
print('X y 분리 후 shape\n')
print('X_train : {}'.format(X_train.shape))
print('y_train : {}'.format(y_train.shape))
print('\nX_test : {}'.format(X_test.shape))
print('y_test : {}'.format(y_test.shape))
'''
X y 분리 후 shape
X_train : (156, 8)
y_train : (156,)
X_test : (52, 8)
y_test : (52,)
'''STEP3. Baseline 기준모델
- 기준모델은 훈련데이터 평균값으로 설정
baseline = [y_train.mean()] * len(y_train)
baseline_mse = mean_squared_error(y_train, baseline)
baseline_rmse = np.sqrt(mean_squared_error(y_train, baseline))
baseline_mae = mean_absolute_error(y_train, baseline)
print('Baseline mean : {}'.format(y_train.mean()))
print('Baseline MSE : {}'.format(baseline_mse))
print('Baseline RMSE : {}'.format(baseline_rmse))
print('Baseline MAE : {}'.format(baseline_mae))
'''
Baseline mean : 103.72435897435898
Baseline MSE : 46863.85350920447
Baseline RMSE : 216.48060769779002
Baseline MAE : 113.04100920447075
'''STEP4. Modeling 모델링
- 데이터셋 지정 및 하이퍼파라미터(직접 설정하였음)
train_ds = lgbm.Dataset(X_train, label= y_train)
test_ds = lgbm.Dataset(X_test, label= y_test)
param = {
'boosting' : 'gbdt',
'objective' : 'regression',
'metric' : 'rmse',
'seed' : 42,
'is_training_metric' : True,
'max_depth' : 16,
'learning_rate' : 0.05,
'feature_fraction' : 0.75,
'bagging_fraction' : 0.8,
'bagging_freq' : 16,
'num_leaves' : 128,
'verbosity' : -1
}- 모델링 (early_stopping=75)
model_lgbm = lgbm.train(params=param,
train_set=train_ds,
num_boost_round=1000,
valid_sets=test_ds,
callbacks=[early_stopping(75),
log_evaluation(75)])
#output
'''
Training until validation scores don't improve for 75 rounds
[75] valid_0's rmse: 120.443
[150] valid_0's rmse: 123.299
Early stopping, best iteration is:
[93] valid_0's rmse: 119.486
'''STEP5. Model Evaluation 모델 평가
- Metrics DataFrame
predict_train = model_lgbm.predict(X_train)
predict_test = model_lgbm.predict(X_test)
df_metrics = pd.DataFrame({'Baseline':[y_train.mean(),
baseline_mse,
baseline_rmse,
baseline_mae],
'Train':[predict_train.mean(),
mean_squared_error(y_train,predict_train),
np.sqrt(mean_squared_error(y_train,predict_train)),
mean_absolute_error(y_train,predict_train)],
'Test':[predict_test.mean(),
mean_squared_error(y_test,predict_test),
np.sqrt(mean_squared_error(y_test,predict_test)),
mean_absolute_error(y_test,predict_test)]},
index = ['Mean','MSE','RMSE','MAE'])
df_metrics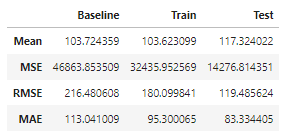
df_metrics_plot = df_metrics.iloc[2:]
df_metrics_plot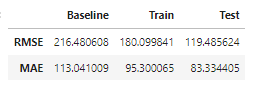
- Metrics barplot (matplotlib)
x = np.arange(2)
width = 0.3
fig, ax = plt.subplots()
rect1 = ax.bar(x-width, df_metrics_plot.Baseline.round(3), width, label='Baseline',color='black',alpha=0.5)
rect2 = ax.bar(x, df_metrics_plot.Train.round(3), width, label='Train',color='purple',alpha=0.5)
rect3 = ax.bar(x+width, df_metrics_plot.Test.round(3), width, label='Test',color='purple',alpha=0.75)
ax.set_title('Metrics of LightGBM model')
ax.set_xticks(x, df_metrics_plot.index)
ax.bar_label(rect1, padding=3)
ax.bar_label(rect2, padding=3)
ax.bar_label(rect3, padding=3)
fig.tight_layout()
plt.legend(ncol=3)
plt.show()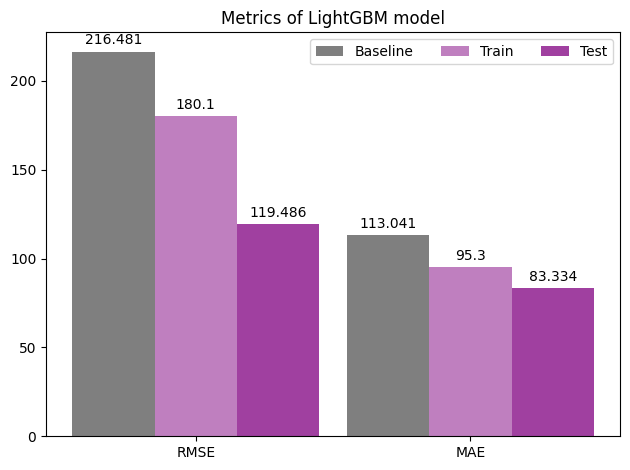
- Regplot
result = pd.concat([y_test.reset_index(drop=True), pd.DataFrame(predict_test)], axis = 1)
result.columns = ['label','predict']
sns.regplot(x='label', y='predict', data=result)
plt.title('Regplot of LightGBM model')
plt.show()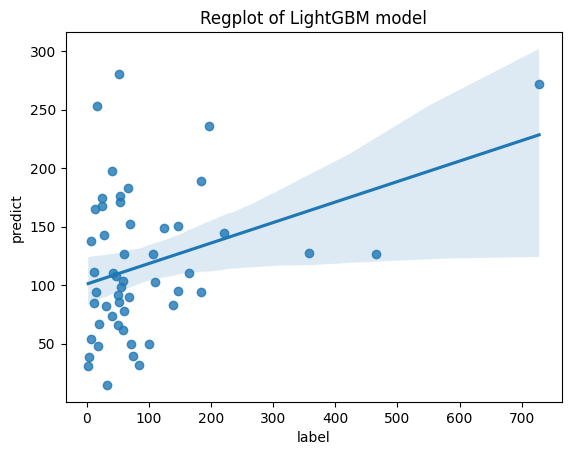
- 만족할만한 성능은 아니었지만, 이후 예측에는 문제가 없어 이대로 진행하였음.
3-3. Object Encoding 객체 부호화
- 모델링을 마치고 pickle library를 통해 모델을 부호화(encoding)하였음.
with open('model.pkl', 'wb') as pf:
pickle.dump(model_lgbm, pf)- 피클링을 통해 부호화한 모델이 다른 파일에서도 제대로 동작하는지 확인해보았음.
- 기상청 기상자료개방포털에서 주요요소 월별평년값으로 테스트 진행
import pickle
import numpy as np
model = pickle.load(open("./data/model.pkl", "rb"))
# 1월 평년값(1991~2020)
array1 = np.array([[-1.9, 2.1, -5.5, 16.8, 2.3, 56.2, 169.6, 1024.9]])
# 2월 평년값(1991~2020)
array2 = np.array([[0.7, 5.1, -3.2, 28.2, 2.5, 54.6, 170.8, 1023.2]])
# 3월 평년값(1991~2020)
array3 = np.array([[6.1, 11.0, 1.9, 36.9, 2.7, 54.6, 198.2, 1019.4]])
# 4월 평년값(1991~2020)
array4 = np.array([[12.6, 17.9, 8.0, 72.9, 2.7, 54.8, 206.3, 1014.8]])
# 5월 평년값(1991~2020)
array5 = np.array([[18.2, 23.6, 13.5, 103.6, 2.5, 59.7, 223.0, 1010.9]])
# 6월 평년값(1991~2020)
array6 = np.array([[22.7, 27.6, 18.7, 129.5, 2.2, 65.7, 189.1, 1007.3]])
# 7월 평년값(1991~2020)
array7 = np.array([[25.3, 29.0, 22.3, 414.4, 2.2, 76.2, 123.6, 1006.4]])
# 8월 평년값(1991~2020)
array8 = np.array([[26.1, 30.0, 22.9, 348.2, 2.1, 73.5, 156.1, 1008.2]])
# 9월 평년값(1991~2020)
array9 = np.array([[21.6, 26.2, 17.7, 141.5, 1.9, 66.4, 179.7, 1013.5]])
# 10월 평년값(1991~2020)
array10 = np.array([[15.0, 20.2, 10.6, 52.2, 2.0, 61.8, 206.5, 1019.2]])
# 11월 평년값(1991~2020)
array11 = np.array([[7.5, 11.9, 3.5, 51.1, 2.2, 60.4, 157.3, 1022.6]])
# 9월 평년값(1991~2020)
array12 = np.array([[0.2, 4.2, -3.4, 22.6, 2.3, 57.8, 162.9, 1025.1]])
array_list = [array1, array2, array3, array4, array5, array6, array7, array8, array9, array10, array11, array12]
for array in array_list:
pred = int(model.predict(array).round(0))
print(pred)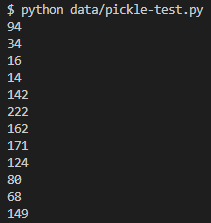
- 문제 없이 동작하였음!
04~. 이후 배포 및 결론 과정은 다음 포스팅에서!

일 때문에 포스팅은 잠시 쉬어요 ㅠ 바쁘다 바빠 모두들 화이팅! // Machine Learning (AI) Engineer & BackEnd Engineer (Entry)